Analyses de régression
Considérations
économétriques
Tests statistiques
Formes fonctionneles
Exemples
SÉANCE 9
STATISTIQUES ANALYTIQUES (suite)
17 mars 2006

Modèles et formes fonctionnelles
Régression (OLS)
Linéaire et non-linéaire
Autoregressif (SAR ou SARS)
Maximum de vraisemblance
Artificial Neural Networks (ANNs)
Abductive Learning Networks(ALNs)
Case-Based Reasoning (CBR)
Très utilisées, conviennent bien lorsque résultats de
l’échantillon s’applique à la population,
cependant biaisées et paramétriques
Récemment utilisées, préférés lorsque la dimension spatiale
et temporelle affecte le phénomène, nécessite coordonnées,
réduit les erreurs et fournit de paramètres fiables.
Récemment utilisées, permet de mieux modéliser, suit le du
cerveau humain, cependant problèmes de «Over-Fitting » et
«Black-Box ». Il n’est pas encore tout à fait connu.
Même principe que ANNs, cependant «Over-Fitting » résolu,
ne tient pas compte des bruits d’informations
contrairement à ANNs. Il reste à en savoir plus.
Fonctionne selon une approche multicritère, conditions
spécifiées dans une table de critères référencée à la base
de données utilisées. Semble être moins bon que OLS.

Régression linéaire
« Méthode des moindres carrés ordinaires »
Y = B0+ (B1* D) + (B2 * S) + (B3* R) + (B4* T) + E
où
Y Valeur marchande ;
DStructurel ;
SSpatial ;
R Socio-économique ;
T Temporel;
B0et B1,2,3,4 Coefficients de la régression;
E part d’erreur dans le modèle.

Superficie habitable
Type de propriété (Bungalow, Cottage,…)
Garage
Piscine
Foyer
Climatisation
Distances : centre-ville, emploi, commerce, école, …
Proximités : parc, fleuve, autoroute, chemin de fer, industrie, …
Positions : municipalités et divers secteurs.
Revenus
Scolarité
Origine ethnique
Taux de chômage
Autocorrélation spatiale
Mois écoulés depuis la transaction
Saison de vente
Cycle immobilier
Autocorrélation temporelle
STRUCTUREL
(CUM)
SPATIAL
(SIG et statistiques)
SOCIO-ÉCONOMIQUE
(RECENSEMENT et SIG)
TEMPOREL
(CUM et statisques)

Correlations
1,000
-,199
,436
,321
,142
,334
,300
,073
,436
,
,000
,000
,000
,003
,000
,000
,121
,000
450
450
450
450
450
450
450
450
450
-,199
1,000
-,096
-,060
-,313
-,326
-,055
,159
-,096
,000
,
,043
,203
,000
,000
,244
,001
,043
450
450
450
450
450
450
450
450
450
,436
-,096
1,000
,758
,333
,068
,241
,170
1,000
,000
,043
,
,000
,000
,153
,000
,000
,000
450
450
450
450
450
450
450
450
450
,321
-,060
,758
1,000
,328
,118
,129
,202
,758
,000
,203
,000
,
,000
,012
,006
,000
,000
450
450
450
450
450
450
450
450
450
,142
-,313
,333
,328
1,000
,116
-,005
,013
,333
,003
,000
,000
,000
,
,014
,910
,787
,000
450
450
450
450
450
450
450
450
450
,334
-,326
,068
,118
,116
1,000
-,125
-,132
,068
,000
,000
,153
,012
,014
,
,008
,005
,153
450
450
450
450
450
450
450
450
450
,300
-,055
,241
,129
-,005
-,125
1,000
-,028
,241
,000
,244
,000
,006
,910
,008
,
,550
,000
450
450
450
450
450
450
450
450
450
,073
,159
,170
,202
,013
-,132
-,028
1,000
,170
,121
,001
,000
,000
,787
,005
,550
,
,000
450
450
450
450
450
450
450
450
450
,436
-,096
1,000
,758
,333
,068
,241
,170
1,000
,000
,043
,000
,000
,000
,153
,000
,000
,
450
450
450
450
450
450
450
450
450
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
PRIX
AGEFFECT
SUPTERR
FRONTAGE
PROFOND
GARJSSOL
GARJINTG
GARJEXT
SUPHABT
PRIX
AGEFFECT
SUPTERR
FRONTAGE
PROFOND
GARJSSOL
GARJINTG
GARJEXT
SUPHABT
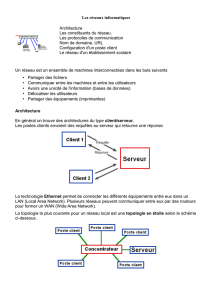
Analyse de corrélation – test bilatéral (2-tailed)
Il y a corrélation entre deux variables du modèle lorsque les valeurs prises par les deux fluctuent simultanément
dans le même sens (corrélation positive ou inverse (corrélation négative).
En recherche, le seuil de signification statistique des corrélations est habituellement en dessous de 5 %.
Dans le tableau qui suit, la plus forte relation est entre la superficie du terrain et son frontage, soit 75,8 % (et le
test est très significatif).
 6
7
8
9
10
11
6
7
8
9
10
11
1
/
11
100%