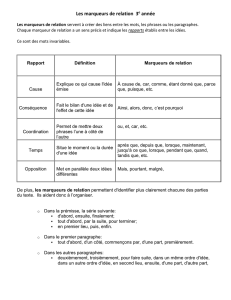
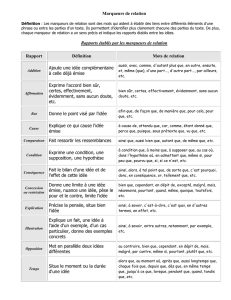
NNT: 2016SACLA027
THÈSE
PRÉSENTÉE POUR OBTENIR LE GRADE DE DOCTEUR DÉLIVRÉ PAR
L’UNIVERSITÉ PARIS-SACLAY
PRÉPARÉE À
L'INSTITUT DES SCIENCES ET INDUSTRIES DU VIVANT ET DE L'ENVIRONNEMENT
(AGROPARISTECH)
ECOLE DOCTORALE N°581
ABIÈS :AGRICULTURE, ALIMENTATION, BIOLOGIE, ENVIRONNEMENT ET SANTÉ
Spécialité : Mathématiques appliquées
Par
SÉBASTIEN RAGUIDEAU
ANALYSE DE DONNÉES DE MÉTAGÉNOMIQUE
FONCTIONNELLE PAR NMF POUR LA MODÉLISATION
DE LA DÉGRADATION DES FIBRES
PAR LE MICROBIOTE INTESTINAL HUMAIN.
Soutenue publiquement le 6 Décembre 2016 à Jouy-en-josas devant le jury composé de :
Marie-Laure Martin-Magnette Directeur de Recherche INRA Présidente du Jury
Hidde de Jong Directeur de recherche INRIA Rapporteur
Guy Perriere Directeur de recherche CNRS Rapporteur
Théodore Bouchez Ingénieur IRSTEA Examinateur
Béatrice Laroche Directeur de Recherche INRA Directrice de thèse
Marion Leclerc Chargé de Recherche INRA Co-directrice de thèse
Sandra Plancade Chargé de recherche, Inra Co-directrice de thèse
Thèse préparée à l'INRA, dans l'unité
Mathématique et Informatique Appliquées du Génome à l'environnement, UR1404,78350
Jouy-en-Josas, France.


Table des matières
1 Microbiote intestinal humain et metagénomique 10
1.1 Caractérisation du microbiote intestinal humain . . . . . . . . . . . . . . . . . . 11
1.1.1 Du système digestif humain au microbiote . . . . . . . . . . . . . . . . . 11
1.1.2 Le microbiote intestinal humain . . . . . . . . . . . . . . . . . . . . . . . 14
1.1.3 Dynamique du microbiote intestinal humain . . . . . . . . . . . . . . . . 19
1.2 Quelstypesdedonnées................................ 22
1.2.1 Descriptions taxonomiques du microbiote intestinal humain . . . . . . . . 22
1.2.2 Descriptions génétiques du microbiote intestinal humain . . . . . . . . . 22
1.2.3 Projets de métagénomique sur le microbiote humain . . . . . . . . . . . . 24
1.3 Quelle utilisation des données métagénomiques . . . . . . . . . . . . . . . . . . . 25
1.3.1 Clusterisation taxonomique des individus . . . . . . . . . . . . . . . . . . 25
1.3.2 Reconstruction du génome d’espèces non cultivées . . . . . . . . . . . . . 26
1.3.3 Mise en évidence des spécificités fonctionnelles des microbiotes humains . 28
1.4 Présentation des données métagénomiques utilisées dans ce travail de thèse . . . 29
1.4.1 Integrated Gene Catalog (IGC) . . . . . . . . . . . . . . . . . . . . . . . 29
1.4.2 Abondances des gènes de l’IGC pour 1423 échantillons métagénomiques . 30
2 Modélisation biologique de la dégradation des fibres 32
2.1 Comment décrire la dégradation des fibres par l’éco-système du microbiote in-
testinalhumain .................................... 33
2.1.1 Quelques notions d’écologie . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.1.2 Une description fonctionnelle plutôt que taxonomique . . . . . . . . . . . 37
2.2 Sélection de traits fonctionnels de la dégradation anaérobie des fibres par le
microbiote intestinal humain . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.2.1 Hydrolyse des polysaccharides . . . . . . . . . . . . . . . . . . . . . . . . 39
2.2.2 Sélection des marqueurs de la métabolisation des oses . . . . . . . . . . . 42
3

2.2.2.1 Le catabolisme des monosaccharides en condition anaérobie . . 42
2.2.2.2 Principe de sélection des marqueurs fonctionnels . . . . . . . . 49
2.2.2.3 Voies du catabolisme des sucres simples provenant de la dégra-
dationdesfibres .......................... 50
2.2.2.4 Glycolyse anaérobie . . . . . . . . . . . . . . . . . . . . . . . . 61
2.2.2.5 Du pyruvate aux accepteurs finaux d’électrons . . . . . . . . . . 65
2.2.2.6 Réutilisation des produits de fermentation . . . . . . . . . . . . 72
2.2.2.7 Graphe topologique des marqueurs fonctionnels sélectionnés . . 77
2.3 Constitution de la matrice des abondances des TFA . . . . . . . . . . . . . . . 84
3 Modélisation Mathématique 86
3.1 Un modèle de Combinaisons de Trait Fonctionnels Agrégés (CTFA) . . . . . . . 87
3.2 Prendre en compte l’information biologique pour la construction des CTFA . . . 90
3.2.1 Transformer une connaissance sur la structure des génomes en une contrainte
algébriquesurlesCTFA ........................... 90
3.2.2 Transformer une connaissance métabolique en contrainte algébrique . . . 91
3.3 Construction pratique de la contrainte de structure liée au métabolisme . . . . . 94
3.3.1 Exploitation du graphe topologiques associé aux 61 KO . . . . . . . . . . 94
3.3.2 Étude de 190 génomes d’espèces prévalentes dans le microbiote intestinal
humain afin de calibrer les contraintes . . . . . . . . . . . . . . . . . . . 96
4 Factorisation en Matrices non-Négatives 101
4.1 Divergencematricielle ................................103
4.1.1 Divergences usuelles en NMF . . . . . . . . . . . . . . . . . . . . . . . . 104
4.1.1.1 Divergence associée à la norme de Frobenius . . . . . . . . . . . 104
4.1.1.2 La divergence de Kullback-Leibler généralisée . . . . . . . . . . 105
4.1.2 Avantages et inconvénients de ces deux divergences . . . . . . . . . . . . 105
4.1.3 Choix d’implémentation . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.2 Termedepénalisation ................................107
4.2.1 Pénalisations usuelles en NMF . . . . . . . . . . . . . . . . . . . . . . . . 107
4.2.2 Choix d’implémentation . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
4.2.3 Étude des constantes de pénalisation . . . . . . . . . . . . . . . . . . . . 108
4.3 Propriétés du problème d’optimisation de NMF . . . . . . . . . . . . . . . . . . 111
4.3.1 Leproblèmegénéral .............................111
4.3.1.1 Point stationnaire et minimum local . . . . . . . . . . . . . . . 112
4.3.1.2 Propriétés de la fonction de coût . . . . . . . . . . . . . . . . . 114
4

4.3.1.3 Minimisation des problèmes bi-convexes . . . . . . . . . . . . . 115
4.3.2 Particularité de la NMF sous contrainte . . . . . . . . . . . . . . . . . . 116
4.4 Résolution du problème de minimisation . . . . . . . . . . . . . . . . . . . . . . 117
4.4.1 Etatdel’art..................................117
4.4.1.1 Quelques algorithmes à résolution partielle . . . . . . . . . . . . 118
4.4.1.2 Quelques algorithmes de minimisation alternée . . . . . . . . . 120
4.4.1.3 Gradient proximal accéléré . . . . . . . . . . . . . . . . . . . . . 124
4.4.2 Implémentation................................124
4.5 Détermination des paramètres du problème de NMF . . . . . . . . . . . . . . . . 127
4.5.1 Méthodes de sélection de la dimension kdans la littérature . . . . . . . . 127
4.5.1.1 Stabilité numérique . . . . . . . . . . . . . . . . . . . . . . . . 127
4.5.1.2 Validation Croisée adaptée à la NMF : Bi-Validation-Croisée . 129
4.5.1.3 Autres méthodes . . . . . . . . . . . . . . . . . . . . . . . . . . 130
4.5.2 Sélections de αet k.............................130
4.5.2.1 Critères choisis . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
4.5.2.2 Démarche globale . . . . . . . . . . . . . . . . . . . . . . . . . . 131
4.5.2.3 Paramètres sélectionnés . . . . . . . . . . . . . . . . . . . . . . 132
5 Résultats de l’inférence : analyse des matrices Wet H137
5.1 La NMF, une approche de réduction de dimension . . . . . . . . . . . . . . . . . 138
5.1.1 Interprétation géométrique des résultats . . . . . . . . . . . . . . . . . . 138
5.1.2 Conservation de l’information de A.....................143
5.2 AnalysedesCTFA ..................................145
5.2.1 Présentation générale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
5.2.2 Comparaison des CTFA . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
5.3 Analyse des abondances des CTFA . . . . . . . . . . . . . . . . . . . . . . . . . 159
5.3.1 Abondances des CTFA selon les méta-variables . . . . . . . . . . . . . . 160
5.3.2 Validation de la discrimination de la maladie de Crohn . . . . . . . . . . 165
Perspectives 170
Annexes 174
A Valorisation scientifiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
B Abondance des CTFA pour chaque catégorie de métavariable . . . . . . . . . . 176
C Liste des 190 génomes choisis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
D Article soumis à Plos Computational Biology . . . . . . . . . . . . . . . . . . . . 187
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
1
/
241
100%