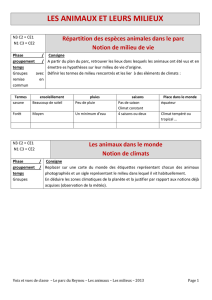
OLAP - LabUnix

OLAP
Équipe:
Johanne Lavoie
Giovanni Malizia
Présenté le 26 avril 2004
Prof. : Robert Godin
Cours : INF7115
Session : Hiver 2004

2
Plan de présentation
Survol
Problématiques
Approches OLAP
Amélioration de la performance
Processus de sélection des vues à matérialiser
Hiérarchies des attributs
Contexte étudié
Cadre du treillis
Algorithmes glouton
Modèle de coût
Produits commerciaux
Conclusion
Références

3
Survol
Introduit en 1993 par E.F. Codd
Performance inacceptable sur un environnement opérationnel
Utilisation pour l’aide à la décision
Utilisateurs OLAP autonomes
Différents types : MOLAP, ROLAP, HOLAP, DOLAP
Étroitement lié aux entrepôts de données

4
Défis
Croissance constante des données
Complexité des requêtes
Temps de réponse
Coûts
Le dilemme
Quelles vues doit-on matérialiser pour
optimiser le temps de réponse,
minimiser l’espace disque occupé et
diminuer les coûts ?

5
Approche MOLAP
Les données sont nettoyées, agrégées dans des dimensions
multiples
Les données sont emmagasinées dans des rangées
multidimensionnelles
Pré compilation des rangées d'organisation et de données qui
peuvent être consultées directement et plus rapidement
Joints déjà fait
Vue multidimensionnelle directe des données
Facilité d'utilisation
Crystal decisions, « Compound OLAP. An OLAP Architecture for the Real World », 2001, p.1-15
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
1
/
33
100%