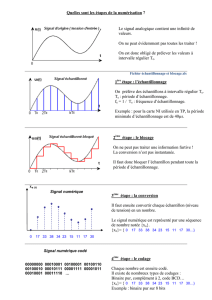
Analyse des données

Analyse et collecte des données

Analyse et collecte des données 2
Modélisation des éléments
aléatoires d’un système
Deux types d'estimation :
A) Paramétrique
On choisit une famille de lois de probabilité
et
on estime les paramètres de cette loi.
La cueillette et l'analyse de données est une étape cruciale dans la construction d'un
modèle de simulation.
À partir des données recueillies, nous devons caractériser les éléments aléatoires d'un
système (lois de probabilité, paramètres de ces lois).
Jusqu'à maintenant, ces lois étaient supposées connues. En pratique, il faut les estimer
à partir de données statistiques.

Analyse et collecte des données 3
Modélisation des éléments
aléatoires d’un système
B) Non-paramétrique
On utilise les données pour construire une fonction de répartition
empirique :
F (x) = Proportion des valeurs qui sont x.
C'est cette fonction qui est utilisée directement.
^

Analyse et collecte des données 4
Avantages de l’approche
paramétrique
Les fonctions de densité et de répartition s'expriment souvent sous forme
analytique.
On dispose de fonctions analytiques pour caractériser les paramètres de ces
lois de probabilité.
On dispose de procédures toutes faites pour générer des valeurs aléatoires
selon ces lois.
On peut avoir des raisons théoriques (physiques) de croire qu'une v.a. devrait
suivre une loi spécifique.

Analyse et collecte des données 5
Inconvénients de l’approche
paramétrique
Il est très difficile, souvent impossible, de choisir le bon type de loi.
Rien ne nous garantit que le choix que l'on a fait est le bon.
Lors de l'ajustement de la courbe, il y a souvent perte ou distorsion d'informations.
L'estimation des paramètres n'est pas toujours facile et robuste.
La génération de valeurs pseudo-aléatoires à partir d'une loi théorique n'est pas
toujours facile.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
1
/
60
100%