ARCHITECTURE MATERIELLE DES SYSTEMES INFORMATIQUES

Lycée Gaston CRAMPE - 40800 AIRE sur l’ADOUR
Section de Techniciens Supérieurs en
Informatique et Réseaux pour l’Industrie et les
Services Techniques
STS IRIS
ARCHITECTURE MATERIELLE
DES SYSTEMES INFORMATIQUES
Partie 1
Chapitre 1 : Introduction à l'architecture des systèmes informatiques
Chapitre 2 : Représentation des informations
Chapitre 3 : La programmation
Chapitre 4 : Le processeur
Chapitre 5 : Les mémoires
Chapitre 6 : décodage d'adresses
Chapitre 7 : Introduction à la gestion des Entrées-Sorties
Chapitre 8 : Les périphériques
J-Cl. CABIANCA

Architecture matérielle des systèmes informatiques Jean-Claude CABIANCA
Chapitre 1
Introduction à l’architecture des systèmes informatiques
1 - Introduction
•Un système informatique est l'ensemble des moyens logiciels (Software) et matériels
(Hardware) nécessaires pour satisfaire les besoins informatiques de l'utilisateur.
•L'architecture d'un système informatique est la description de ses unités fonctionnelles et de
leurs interconnexions.
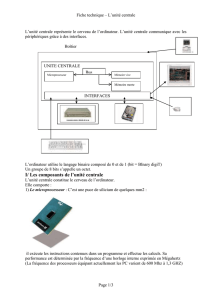
•La configuration habituelle d’une station de travail est donnée ci-dessous :
-L'unité centrale de traitement ou UC est constituée :
•Du CPU (Central Process Unit) ou processeur correspondant au moteur de la machine.
Il exécute les instructions des programmes ;
•De la mémoire centrale qui contient les programmes et les données à traiter.
-Le clavier, la souris et l’écran permettent l’interaction avec les utilisateurs.
-Le disque dur, le disque optique (CD, DVD….) et le stockage USB permettent le stockage
permanent des informations.
-Le MODEM (MOdulateur - DEModulateur) permet de communiquer avec d'autres ordinateurs
éloignés en utilisant une ligne téléphonique.
-Le Digitaliseur (Scanneur) permet de digitaliser des documents, c'est à dire de transformer une
image en une forme numérique (fichier).
-La carte réseau permet de communiquer avec d'autres ordinateurs éloignés en utilisant un
support Ethernet.
Chapitre 1 : Introduction à l’architecture des systèmes informatiques Page 1/14

Architecture matérielle des systèmes informatiques Jean-Claude CABIANCA
2 – Les réseaux
•L'avènement des réseaux (Networks) a permis de relier différents ordinateurs. Ces
ordinateurs peuvent être soit groupés dans un voisinage, par exemple le même bâtiment, c’est ce
que l'on appelle un réseau local, soit dispersés de par le monde.
•La notion de réseau est importante car un réseau permet de relier un grand nombre d'ordinateurs
entre eux et ainsi d’offrir aux utilisateurs des fonctionnalités de communication et de mise à
disposition d'un énorme potentiel d'informations.
3 - Utilisation des ordinateurs
•L’utilisation d’un ordinateur sous-entend l'exécution d’un programme par celui-ci, c’est
pourquoi toute application nécessite du matériel, en l'occurrence un ordinateur, et du logiciel
qui est exécuté par cet ordinateur.
•Le logiciel se décompose en deux familles :
-Les programmes systèmes;
-Les programmes d'application.
•Les fonctions de base d'un ordinateur sont réalisées au moyen de programmes système.
•Le système d'exploitation (OS : Operating System), le plus important des programmes
système, s'occupe de gérer les différentes ressources de la machine. Il facilite la tâche du
programmeur en lui offrant un accès simplifié aux ressources de la machine.
Chapitre 1 : Introduction à l’architecture des systèmes informatiques Page 2/14

Architecture matérielle des systèmes informatiques Jean-Claude CABIANCA
4 - Le matériel
4.1 - Introduction
•Les ordinateurs ont d'abord été des machines à calculer. En effet, les mathématiques
permettent entre autres choses, de définir une algèbre sur des grandeurs binaires (Algèbre de
Boole) avec des propriétés très intéressantes.
•Les grandeurs binaires peuvent se matérialiser très simplement (0 ou 1 = Absence ou
Présence de courant électrique), ce qui fait que dés que l’on a pu manipuler rapidement des
ensembles suffisamment importants d’éléments binaires (bits), on a pu réaliser des calculateurs
puis des ordinateurs.
•Pour traiter une information un processeur seul ne suffit pas, il faut lui associer de la mémoire
(pour stocker le programme) et des interfaces d'entées-sorties (pour dialoguer avec l'extérieur).
Ces différents organes sont reliés par des voies de communication appelées bus comme le
montre la figure suivante :
4.2 - Le processeur ou CPU
•C'est l'organe de contrôle. Tout traitement (opération logique ou arithmétique) se fera dans le
processeur.
•Celui-ci manipule les octets (ensemble de 8 bits), qui circulent sur un ensemble de fils appelé
Bus de données. Ces mots circulent entre le processeur et les mémoires ou les interfaces
d'Entrées / Sorties (E / S).
•Le processeur considère que chaque octet est rangé dans un endroit qu’il peut repérer et
atteindre que nous appellerons provisoirement " Tiroir " dont le nombre de casiers correspond au
nombre de bits. Chaque tiroir sera connu du processeur par un numéro qui permettra de l'ouvrir,
lui et lui seul.
Chapitre 1 : Introduction à l’architecture des systèmes informatiques Page 3/14

Architecture matérielle des systèmes informatiques Jean-Claude CABIANCA
•On appelle ce numéro, l'adresse du tiroir et il sera véhiculé par le bus d'adresses dont la
largeur (son nombre de fils) dépendra du nombre d'adresses que le processeur pourra produire.
•Sa principale caractéristique est la vitesse de son horloge (exprimée actuellement en Ghz) qui
permet de connaître le nombre de millions d’instructions exécutées par secondes (MIPS).
•A chaque top d'horloge (et ce pour les instructions simples) le processeur :
1. Lit l'instruction à exécuter en mémoire (travail effectué par l’unité de commande) ;
2. Exécute l'instruction (travail effectué par l’unité de traitement aussi appelée UAL – Unité
Arithmétique et Logique) ;
3. Passe à l'instruction suivante.
•Les processeurs peuvent être basés sur deux types d’architecture : CISC ou RISC.
-Les processeurs basés sur l'architecture CISC (Complex Instruction Set Computer) peuvent
traiter des instructions complexes. Elles sont cependant lentes à exécuter (un processeur basé
sur l'architecture CISC ne peut traiter qu'une instruction à la fois).
-Par opposition, un processeur utilisant l'architecture RISC (Reduced Instruction Set
Computer) possède des instructions plus simples, peu nombreuses et qui peuvent être traitées
en un cycle machine. Cependant, pour effectuer certaines opérations complexes, ce type
d’architecture demandera plus de ressources.
Remarques :
-Le bus de données est bidirectionnel : le processeur peut " remplir " (écrire dans) ou " vider "
(lire dans) tout tiroir.
-Le bus d'adresses est unidirectionnel : le processeur indique le numéro du tiroir qu'il veut
actionner.
-Un bus est caractérisé par sa largeur (nombre de bits) et par sa fréquence (vitesse) ce qui
permet d’obtenir son débit théorique (en Mo ou Go par seconde).
-Il existe aussi un bus de commande ou bus de contrôle qui transporte les ordres et les signaux
de synchronisation en provenance du processeur et à destination de l'ensemble des composants
matériels (mémoires et interfaces d'entrées-sorties).
-La multiplication des périphériques autour du processeur nécessite la présence d'un décodeur
d'adresses chargé d'aiguiller les données présentes sur le bus de données vers le boîtier
d'interface d'entées-sorties concerné.
4.3 - Les mémoires.
•Puisque le processeur manipule des groupes de bits assemblés en mots, il faut déjà de la
mémoire pour le stockage des données. Mais pour exécuter ces manipulations de façon
automatique, le processeur doit recevoir des instructions correspondantes. Celles-ci seront, elles
aussi rangées dans de la mémoire lors de la programmation.
•Un ordinateur va donc comporter un certain nombre de mémoires où l'on pourra indifféremment
lire ou écrire.
Chapitre 1 : Introduction à l’architecture des systèmes informatiques Page 4/14
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
1
/
72
100%