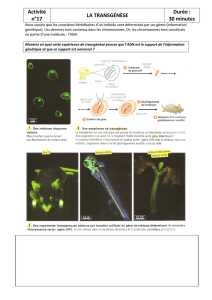
iii. gene, code genetique et synthese des proteines

le caryotype. De nouvelles techniques de marquage
des chromosomes directement sur coupes tissulaires
(FISH) ou in vitro ( C G H ) (Fig. 14) ont été dévelop-
pées ces dernières années et permettent d’étudier des
remaniements chromosomiques sur des populations
cellulaires hétérogènes comme le sont les tumeurs.
Les séquences d’ADN constituant le génome
humain sont hétérogènes. Cette séquence est structu-
rée à 30% en unités fonctionnelles appelées gènes et
à 70% en séquences extragéniques dont la fonction
n’est pas connue au moins pour une partie d’entre
elles. Elles ne sont pas vitales car elles ont été élimi-
nées du génome de certaines espèces animales ou
végétales (espèces à génome condensé). Cet ADN
“non fonctionnel” extragénique est constitué à envi-
ron 20% de séquences répétitives, comme l’ADN
satellite, riches en paires G-C ou en paires A-T. Cet
ADN répétitif contient des séquences variables
(polymorphiques) et spécifiques de régions chromo-
somiques qui peuvent servir de marqueurs pour éta-
blir des cartes génétiques (Fig. 15).
Le gène peut être défini comme un segment de
l’ADN correspondant à une unité de l’information
génétique dont la séquence correspond à une protéi-
ne qui en assurera la fonction. Récemment, J.
Weissenbach a suggéré que le génome humain
contiendrait vraisemblablement e n v i ron 56000
gènes et non 100000 comme les premières estima-
tions le laissaient penser. Au total, l’ADN intragé-
nique codant (exonique) pour des protéines ne
représenterait que moins de 10% du génome
total. L’importance de l’ADN non codant ne doit
cependant pas être sous estimé car il joue proba-
blement un rôle essentiel dans le régulation de
l’expression de l’ADN codant.
La spécificité de l’information génétique repose sur
la particularité structurelle des gènes et se traduit in
fine par la synthèse d’une protéine dont la fonction
est définie par une structure tridimensionnelle préci-
se. C’est de la qualité physico-chimique de la
séquence linéaire (extrémités NH2 & COOH)
d’acides aminés que résultent la structure tridimen-
sionnelle et la fonction de la protéine (Fig. 16).
Le transfert de l’information génétique de l’ADN est
assuré par une étape intermédiaire: la transcription
où l’acide ribonucléique dit “ m e s s a g e r ”
(ARNm) est synthétisé. La molécule d’ARNm est
formée de ribonucléotides correspondant à la
séquence en nucléotides d’un des deux brins
d’ADN. A la différence de l’ADN, dans l’ARN,
l’Uracile remplace la Thymidine comme base com-
plémentaire de l’Adénine. Sous l’action d’enzymes,
la molécule d’ADN s’ouvre et par complémentarité
des bases (Adénine-Uracile et Guanine-Cytosine),
des nucléotides s’associent en une séquence iden-
tique à celle du brin d’ADN informatif. Ainsi une
molécule d’ARNm simple brin est formée et trans-
met l’information génétique pour la synthèse pro-
téique. L’ARNm est fabriqué dans le noyau puis
transféré dans le cytoplasme avant l’étape de syn-
thèse proprement dite de la protéine ou traduc-
tion.
La synthèse des protéines repose sur la correspon-
dance, dans un système appelé code génétique,(Fig.
17) entre un ensemble de 3 bases (codon) et un acide
aminé : ce code génétique est tout aussi universel
que l’ADN lui-même. Au cours de la traduction, la
séquence de l’ARNm est convertie en une séquence
d’acides aminés pour former une chaîne polypepti-
dique. Cette étape utilise un code dont l’unité est le
codon : triplets de bases dont l’ordre est traduit en
une succession d’acides aminés correspondants
(polypeptides) au niveau des ribosomes.Les acides
aminés sont ordonnés dans la séquence déterminée
par la succession de codons de l’ARNm. Chaque
ARN de transfert (ARNt) transporte un acide aminé
différent en fonction du motif de 3 nucléotides (anti-
codon) qu’il présente. Les ARNt s’ordonnent par
leur anticodon en fonction des codons présentés par
l’ARNm. Ainsi les protéines sont constituées d’une
chaîne linéaire d’acides aminés: ceux-ci sont, dans
tout le règne animal, au nombre d’une vingtaine.
Certains acides aminés peuvent être codés par plu-
sieurs triplets, c’est pourquoi le code génétique est
dit dégénéré. En effet, il y a 64 codons différents :
61 pour les 20 acides aminés et 3 (UAA, UAG et
UGA) pour des signaux qui contrôlent la traduction
et qui sont qualifiés de codons “ non sens ”. En fait,
ces codons, contrairement à leur qualification de
non-sens, ont un sens bien particulier puisqu’ils arrê-
tent la traduction. Le codon ATG, quant à lui, agit
comme point de départ. Il code pour la méthionine et
correspond au site d’initiation de la traduction.
Chaque gène est donc caractérisé par des séquences
III. GENE, CODE GENETIQUE ET
SYNTHESE DES PROTEINES
716

717
Figure 14 : Techniques de marquage des chromosomes par hybridation génomique comparative (C.G.H.) et hybridation in
situ fluorescente (F.I.S.H).

718
Figure 16 : Structure des protéines
Structure primaire
Structure secondaire
Structure tertiaire Structure quaternaire
(assemblage de sous unités)
Figure 15 : différentes dénominations de l’ADN selon ses séquences et fonctions

719
Figure 16 : Suite Structure des protéines

720
ALANINE Ala AGCU GCA
GCC GCG
ARGININE Arg R CGU CGA AGA
CGC GGG AGG
ASPARAGINE Asn NAAU
AAC
ACIDE ASPARTIQUE Asp DGAU GAC
CYSTINE Cys CUGU UGC
ACIDE GLUTAMIQUE Glu EGAA GAG
GLUTAMINE Gln QCAA
CAG
GLYCINE Gly GGGU GGA
GGC GGG
HISTIDINE His HCAU
CAC
ISOLEUCINE Ile IAUU
AUC
AUA
LEUCINE Leu LUUA CUU CUG
UUG CUC
AUA CUA
LYSINE Lys KAAA AAG
METHIONINE Met MAUG (Depart)
PHENYLALANINE Phe FUUU CUU CUG
UUC CUC
CUA
PROLINE Pro PCCU CCA
CCC CCG
SERINE Ser SUCU UCA AGU
UCC UCG AGC
THREONINE Thr TACU ACA
ACC ACG
TRYTOPHANE Trp WUGG
TYRONINE Tyr YUAU UAC
VALINE Val VGUU GUA
GUC GUG
STOP UAA UAG UGA
Figure 17 : Code génétique
 6
7
8
9
10
11
12
13
14
6
7
8
9
10
11
12
13
14
1
/
14
100%