Bioinformatique - TP2 : recherche de cadres de

Bioinformatique - TP2 : recherche de cadres de lecture ouverts (ORF)
Jean-Baptiste Lamy /
Manipuler des s´equences biologiques en Python
Importation des modules n´ecessaires :
from Bio.Seq import *
from Bio.SeqIO import *
Les s´equences charg´ees avec BioPython peuvent ˆetre manipul´ee comme des chaˆınes de caract`ere Python, et poss`edent en
plus des fonctions sp´ecifiques aux s´equences (transcription, etc). Il existe deux mani`eres de traiter les s´equences en Python :
les s´equences anonymes (Seq) et les s´equences nomm´ees (SeqRecord, incluant le nom du g`ene, de l’esp`ece, etc, en plus de la
s´equence proprement dite).
Op´erations Code Python
Cr´eer une s´equence anonyme d’ADN, d’ARN ou une
s´equence prot´eique (d’acides amin´es)
adn = Seq("ATGC...", IUPAC.unambiguous_dna)
arn = Seq("AUGC...", IUPAC.unambiguous_rna)
prot = Seq("MLVA...", IUPAC.protein)
Charger `a partir d’un fichier FASTA une s´equence
(nomm´ee) d’ADN, d’ARN ou d’acides amin´es
adn = read("fichier.fasta", format="fasta")
arn = read("fichier.fasta", format="fasta")
prot = read("fichier.fasta", format="fasta")
Transformer une s´equence anonyme en s´equence nomm´ee
(ADN ou autre) SeqRecord(adn, name="nom")
Transformer une s´equence nomm´ee en s´equence anonyme adn.seq
Compter le nombre de paire de base / d’acide amin´e dans
une s´equence (ADN, ARN ou prot´eine) len(adn)
Afficher la totalit´e d’une s´equence str(adn) # S´equence anonyme (Seq)
str(adn.seq) # S´equence nomm´ee (SeqRecord)
Obtenir la base n°i d’une s´equence adn[i]
Extraire une partie d’une s´equence de la base i `a la base j adn[i : j]
Parcourir toutes les bases d’une s´equence for base in adn: print(base)
for i in range(len(adn)): print(adn[i])
Les op´erations suivantes sont disponibles uniquement sur les s´equences anonymes (sinon, remplacer adn par adn.seq)
Calcule le compl´ement d’une s´equence d’ADN ou d’ARN adn.complement()
Inverse une s´equence d’ADN, d’ARN ou d’AA et prend
son compl´ement adn.reverse_complement()
Transcrire une s´equence d’ADN (brin codant) en ARN
(transcription brute ne prenant pas en compte les sites
promoteurs)
adn.transcribe()
Traduire une s´equence d’ADN (brin codant) ou d’ARN en
AA (traduction brute ne prenant pas en compte les
codons start et stop, le cadre de lecture, etc)
adn.translate()
arn.translate()
Rechercher des motifs en Python
Importation des modules n´ecessaires :
import Bio.motifs as motifs
Cr´eer un motif `a partir d’une ou plusieurs
s´equences (ADN, ARN ou prot´eique) motif = motifs.create([adn1, adn2,...])
Recherche exacte (dans une s´equence anonyme
uniquement)
for position, sequence in motif.instances.search(adn):
print(position)
Recherche approximative (matrice PSSM, dans
une s´equence d’ADN anonyme uniquement)
for position, score in motif.pssm.search(adn):
print(position)
1

Exercice :
L’objectif du TP est de rechercher des cadres de lecture ouverts (ORF) dans un g´enome. Pour cela nous allons travailler
sur le g´enome d’Escherichia coli K-12 ; le d´ebut de ce g´enome est dans le fichier “genome e coli debut.fasta” (NB c’est le brin
codant qui est repr´esent´e).
1. Importer les modules BioPython pour la manipulation des s´equences et des motifs.
2. Charger le fichier “genome e coli debut.fasta” dans une variable que l’on appellera “adn”.
3. Afficher la s´equence d’ADN. Combien a-t-elle de paires de base ?
4. Transcrire la s´equence d’ADN en ARN, et mettre le r´esultat dans la variable “arn”.
5. Cr´eer un motif appel´e “motif start” correspondant `a la s´equence du codon start (AUG).
6. Rechercher toutes les positions sur l’ARN correspondants `a des codons starts `a l’aide du motif “motif start”. Mettre
les r´esultats dans la variable “tous les start” (astuce : on utilisera une boucle pour ne garder que les positions, et pas
les s´equences des motifs trouv´es).
7. De la mˆeme mani`ere, rechercher toutes les positions correspondants `a des codons stop (UAA, UAG et UGA).
8. `
A quelle position commence le premier ORF ? `a quelle position se trouve le codon stop correspondant (attention
question pi`ege) ?
9. Combien y a-t-il de phases de lecture possibles sur ce brin d’ADN ?
10. Rechercher (automatiquement) le stop du premier ORF (qui commence sur le premier start en 29).
Astuce : le stop correspondant au premier start doit :
— ˆetre situ´e apr`es le start
— ˆetre sur la mˆeme phase de lecture
On utilisera une boucle pour passer en revue les stops, lorsque le bon stop est trouv´e on gardera sa position et on
interrompra la boucle avec un “break”.
11. Cr´eer une liste “toutes les fins” contenant les stops de chaque start.
Astuce : on partira d’une liste vide et on effectuera une boucle sur les starts. Dans cette boucle, on d´eterminera le
stop de chaque start en utilisant la mˆeme m´ethode qu’`a la question pr´ec´edente.
12. Cr´eer une liste appel´ee “toutes les longueurs” contenant la longueur de chaque ORF sur la premi`ere phase de lecture
(en paires de base).
13. Afficher les ORF (1 ORF par ligne, avec son d´ebut, sa fin et sa longueur).
14. Avons-nous trouver tous les ORF pr´esents sur ce morceau de g´enome ? Pourquoi ?
15. Pourrait-on utiliser la mˆeme m´ethode pour rechercher des ORF chez l’homme ?
16. Les ORF de notre tableau correspondent-ils tous `a des prot´eines pr´esentes dans la bact´erie ? pourquoi ?
17. Quelle est la probabilit´e d’avoir un codon stop “par hasard” dans l’ADN, si la distribution des bases ´etait al´eatoire ?
Quelle est la probabilit´e d’avoir un codon autre que le codon stop ?
18. Pour une suite de 10 codons al´eatoires, quelle est la probabilit´e de ne pas avoir de stop ? (Astuce : utiliser l’op´erateur
puissance, qui se note ** en Python). Pour une suite de 70 codons ? Que peut-on en d´eduire pour les ORF de longueur
sup´erieure `a 70 codons ?
19. Extraire l’ARN du premier ORF codant pour plus de 70 acides amin´es, puis le traduire en prot´eine.
20. Rechercher avec BLAST cette s´equence prot´eique. L’ORF correspond-il bien `a une s´equence codante ?
2
1
/
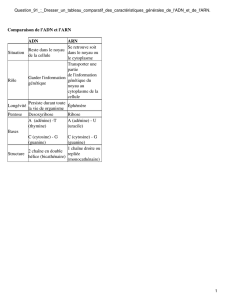
2
100%






![86 [Quels sont les constituants de l`ADN et de l`ARN? ] ADN](http://s1.studylibfr.com/store/data/007383263_1-9a41736365764fe43d1f9e7462bcdc21-300x300.png)