infrasons ultrasons sons audibles 20 0 20000 f(Hz)

NB : Les indications en rouge ne sont pas à retranscrire (ce sont juste des conseils ou des exigences).
Généralités sur le son
(titre de niveau 1 : « grand titre »)
Récupérer l’image suivante dans un fichier (avec un nom explicite) puis envoyer cette image sur le serveur avec
FileZilla … et le mieux est de mettre toutes vos images dans un répertoire
/images
(sur le serveur).
Puis dans votre page HTML, utiliser la balise auto-fermante <img src="images/sound.jpg" /> pour l’insérer sur la
page Web.
Le son est produit par une vibration d'un milieu matériel.
Ci-dessous, il y a une liste à puces (donc non-ordonnée … donc la balise <ul> puis <li> pour chaque item.)
Un son possède 3 caractéristiques :
- sa fréquence de vibration
- son niveau sonore
- sa vitesse de propagation dans le milieu matériel
Un son audible par l'oreille humaine est compris entre 20 Hz et 20 000 Hz (mettre un espace insécable sur
20 000 pour qu’il n’y ait pas de retour à la ligne entre 20 et 000 … idem pour chaque nombre, et devant chaque
unité : 20 Hz).
Au-delà de 20 000 (mettre un espace insécable 20 000) il
s'agit des ultrasons (audibles pour certains animaux). En deçà il
s'agit des infrasons.
Lorsque le son émis à une fréquence de 20 Hz (mettre un
espace insécable 20 Hz), la couche d'air vibre et reprend sa position initiale 20 fois par seconde.
L'amplitude de la vibration correspond à l'intensité sonore, mesuré en décibel (dB).
Les années 1980 ont marqué les grandes heures du son analogique gravé sur des disques vinyles ou enregistré
sur des bandes magnétiques. La qualité est jugée moyenne et de plus la qualité s’altère chaque fois qu’on recopie
le son.
Puis dans les années 2000, on passe au son numérique. Cette fois, les données sont binaires donc il n’y a plus de
perte de qualité lors des copies (c’est le début de la crise du disque) !!!
infrasons ultrasonssons audibles
20
020000 f(Hz)

Numérisation d’un son
(titre de niveau 1)
Il s’agit de stocker un son de manière binaire, c’est-à-dire en une suite de 0 ou 1, appelé BIT (mettre en info-
bulle que BIT est l’abréviation de BInary digiT avec la balise <abbr>).
La méthode de numérisation (la théorie)
(titre de niveau 2)
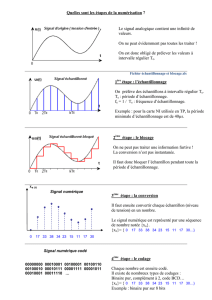
1 - D’abord on utilise un microphone pour convertir les vibrations mécaniques en vibrations électriques (qui sont
de même fréquence f).
2 - Puis on utilise un convertisseur analogique numérique (CAN) pour mémoriser la tension électrique produite :
1/ ces valeurs analogiques de tensions sont numérisées c'est à dire transformées en valeur 1 ou 0. C’est la
numérisation.
2/ cette numérisation n’est pas faite en continu, mais que toutes les 22 micro-secondes (mettre un espace
insécable 22 micro-secondes) (on note dt = 22 × 10
-6
s avec des espaces insécables dt = 22 * 10
-6
s), ce qui
donne une fréquence de 44 100/s notée aussi 44 100 Hz (rappel : fréquence = 1/dt). C’est la fréquence
d’échantillonnage. (mettre des espaces insécables 44 100 etc ... jusqu’à la fin du fichier)
Evidemment : Plus la fréquence d'échantillonnage est importante, meilleure est la qualité du son enregistré.
fréquence
d'échantillonnage
Qualité du son
44 100 Hz qualité CD
22 000 Hz qualité radio
8 000 Hz qualité téléphone
Q
UESTIONNAIRE
:
Q-a/ Combien de mesures de tension sont enregistrées puis numérisées par seconde dans un morceau de
musique enregistré sur un CD ? Réponse : ..........................
-b/ La qualité téléphone est-elle supérieure à la qualité radio ? Réponse : ..........................
Travaux Pratiques
(titre de niveau 1 )
TP 1 : la fréquence d’un son
(titre de niveau 2)
Le
logiciel Audacity
(titre de niveau 3)
Ce logiciel Audacity (mettre un lien hypertext vers un le site http://audacity.fr/ ) permet d’enregistrer un son
puis de le numériser avec une fréquence d’échantillonnage réglable. On branchera une webcam ou un micro sur
l'ordinateur (la webcam servira de microphone).

Installation d’Audacity et Lame MP3
(titre de niveau 3)
1°/ Télécharger Audacity (mettre un lien hypertext vers un le site http://audacity.fr/ )
Puis l’installer. Par défaut, le répertoire d’installation est «
C:\Program Files (x86)\Audacity »
. On pourra mettre le
chemin dans des balises <code> : soit <code>
C:\Program Files (x86)\Audacity </code> et des espaces insécables
C:\Program Files (x86)\Audacity
2°/ Télécharger LAME MP3 (mettre un lien hypertext vers http://lame.buanzo.org/#lamewindl )
Puis Clic sur « Lame_v3.99.3_for_Windows.exe » (lien vers
http://lame.buanzo.org/Lame_v3.99.3_for_Windows.exe
),
le téléchargement s’effectue.
Installer LAME MP3. Par défaut, le répertoire d’installation est «
C:\Program Files (x86)\Lame For Audacity »
.
(Ne pas changer le nom de répertoire
Lame For Audacity
sinon Audacity ne trouvera pas Lame MP3.)
NB : Pour que ces 2 logiciels puissent interagir, il doivent avoir impérativement le même répertoire parent (donc
C:\Program Files (x86)
).
Concours de sifflement (aigu puis grave)
(titre de niveau 3)
Réglage préalable d’Audacity
Ouvrir le logiciel, menu Edition > Préférences >
Qualité puis régler les valeurs comme
indiquées ci-contre.
Refermer le logiciel puis le rouvrir pour que les
nouveaux réglages soient pris en compte.
0- Brancher le micro (fiche rose).
1 - Enregistrer le sifflement le plus aigu possible (bouton Enregistrement et Stop ).
2 – Sélectionner une partie ayant une amplitude à peu près constante (1 seconde suffit), puis la copier dans un
nouveau fichier : menu ‘Edition' > ‘Copier'. Puis ‘Fichier' > ‘Nouveau' et ‘Edition' > ‘Coller'.

3 - a ) Agrandir l’échelle horizontale avec la loupe +
b ) Agrandir l’échelle verticale en positionnant la souris sur l’échelle verticale.
=> Agrandissez suffisamment les 2 échelles jusqu’à obtenir une courbe similaire à celle-ci :
(remplacer ce signal par une copie-écran de votre signal à vous)
Chaque point correspond à une mesure du signal (c’est l’échantillonnage).
L’écart entre 2 points consécutifs est 0,000125 seconde car f = 1/dt donc dt = 1/f = 1/8000 = 0,000125
Q
UESTIONNAIRE
:
Q- Pour obtenir une courbe réellement sinusoïdale, faut-il augmenter ou diminuer la fréquence ? Réponse : .......
5 – On remarque que le signal est périodique, et on ne va garder que 10 périodes.
Même méthode : Sélectionner 10 périodes avec précision, puis la copier dans un nouveau fichier.
Par précaution :
• Enregistrer le projet Audacity dans le dossier musique : sifflement_aigu.aup
(Fichier >
enregistrer le
projet)
• Et exporter l’audio en WAV 16 bits dans le dossier musique : sifflement_aigu.wav
(Fichier >
exporter
l’audio)
6 - Mesurer la durée correspondante à ces 10 périodes (en calculant durée = t
final
– t
initial
) et garder tous les
chiffres significatifs.
7 – En déduire la durée d’une période, puis la fréquence du son.
Recommencer avec le 2
ème
sifflement le plus grave possible sifflement_grave
Q
UESTIONNAIRE
:
Q 1/ Pour le sifflement_aigu : durée d’une période = ............ fréquence du son = .......................
2/ Pour le sifflement_grave : durée d’une période = ............ fréquence du son = .......................
3/ Lequel de ces 2 sifflements a la fréquence la plus grande ? .......................
TP 2 : Echantillonnage
(titre de niveau 2)
0 – Vérifier les réglages d’Audacity (voir le TP 1 précédent) :
• fréquence d’échantillonnage = 8000 Hz
• format d’échantillonnage = 16-bits
1 – Enregistrer au moins 10 secondes de lecture de texte.
2 - Puis on ne va garder que 10 secondes.
Pour sélectionner précisément 10 secondes, vous pouvez taper au clavier la durée de la sélection :

Puis copier cette sélection dans un nouveau fichier.
Puis exporter l’audio en WAV (PCM sans compression) 16 bits dans le dossier musique : conversation_8000hz
(Fichier >
exporter l’audio)
3 – Si vous avez un casque, écouter le son enregistré et apprécier sa qualité.
4 - Calculer la taille théorique du fichier (qui possède 2 pistes : c’est la stéréo), en effectuant ce produit :
durée (en seconde) × nbre de mesures par seconde × l’espace-disque pour mémoriser une mesure × 2 (en stéréo)
donc : 10 secondes × 8000 Hz × 16 bits × 2 = 2 560 000 bits = 320 000 octets (Rappel : 1 octet = 8 bits.)
5 - Comparer avec la taille réelle du fichier. Pourquoi est-elle supérieure à la taille théorique ?
1
ère
raison : un fichier WAV comporte 44 octets d’en-tête qui stocke le format et autres métadonnées. On
obtient donc une taille théorique de 320 044 octets.
2
ème
raison : Sous Windows, il y a une différence entre « taille » et « taille sur le disque » à cause de la taille
des clusters (bloc mémoire) occupés par le fichier.
De plus, Windows note par erreur « Ko » alors qu’il s’agit de « Kio » (Windows fait bien une division par 1024 et
non par 1000) ! Rappel : 1 Kio = 1024 octets 1 Ko = 1000 octets
vous prendrez pour image un screenshot de votre fichier à vous
Recommencer l'expérience en enregistrant la même conversation de 10 secondes mais en choisissant la
fréquence d'échantillonnage maximale (96 000 Hz). Ne pas oublier de fermer puis ré-ouvrir le logiciel pour
que ces nouveaux réglages soient pris en compte !!! Ecouter le son et noter/calculer la taille du fichier son.
Q
UESTIONNAIRE
:
Q : Calculer la taille mémoire en octets d’une chanson de 3 minutes en qualité CD (donc fréquence
d’échantillonnage = 44 100 Hz et numérisation sur 16-bits) ?
NB : un tel fichier est non compressé donc enregistré au format WAV.
Remettre les réglages par défaut d’Audacity
(titre de niveau 2)
Le TP est terminé … Remettre les réglages par
défaut d’Audacity
 6
7
6
7
1
/
7
100%