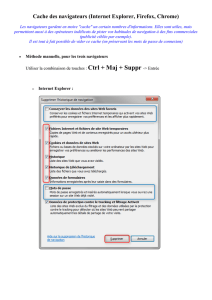
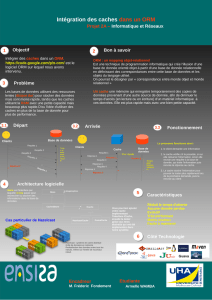
Mémoire cache - Fichier

M€moire cache 1
Mémoire cache
Une mémoire cache ou antémémoire est, en informatique, une m€moire qui enregistre temporairement des copies
de donn€es provenant d'une autre source de donn€e, afin de diminuer le temps d'acc•s (en lecture ou en €criture) d'un
mat€riel informatique (en g€n€ral, un processeur) ‚ ces donn€es. La m€moire cache est plus rapide et plus proche du
mat€riel informatique qui demande la donn€e, mais plus petite que la m€moire pour laquelle elle sert d'interm€diaire.
Des m€canismes mettant en ƒuvre des m€moires caches peuvent „tre impl€ment€s entre tous producteurs et
consommateurs de donn€es fonctionnant de fa…on asynchrone, c'est notamment le cas entre le processeur et la
m€moire vive, mais aussi par exemple entre cette m„me m€moire et les r€seaux informatiques ou les disques durs.
Les donn€es mises en cache peuvent „tre par exemple un programme, un bloc d'image ‚ traiter, etc. La m€moire
source des donn€es peut „tre par exemple un disque dur, la m€moire centrale, etc.
La m€moire cache est souvent tr•s co†teuse car choisie afin d'„tre la plus rapide possible, les concepteurs
d'architecture informatique choisissent des technologies haut de gamme. Les plus connues des m€moires caches sont
celles dont le fonctionnement est associ€ ‚ celui des microprocesseurs. En effet, la taille et la performance de ces
caches, qui peuvent „tre externes ou internes, peuvent tr•s fortement influencer la vitesse de traitement des
programmes. Dans le cas des caches internes, la place utilis€e par les transistors dans le wafer conditionne le co†t de
fabrication des processeurs. Dans ce dernier cas, la m€moire cache est particuli•rement utile si l'algorithme ‚
ex€cuter implique des acc•s r€p€titifs ‚ de petites zones de m€moires (un bout de programme qui se r€p•te, un travail
sur une sous-partie d'un fichier son, etc.) ou si le processeur est capable de pr€dire ses besoins futurs en donn€es pour
remplir la m€moire cache en parall•le d'un calcul, de sorte qu'elle contiendra au moment venu une copie locale des
donn€es ‚ acc•s beaucoup plus rapide.
Dénomination
Mémoire cache est la m„me expression que celle utilis€e en anglais, ‚ savoir cache memory[1], qui a remplac€ ‡
slave-memory ˆ, donn€ par son inventeur Maurice Vincent Wilkes en 1965. L'Acad€mie fran…aise propose plut‰t le
terme ant€m€moire. La diff€rence entre mémoire cache et mémoire tampon r€side dans le fait que la m€moire cache
duplique l'information, tandis que le tampon exprime plut‰t l'id€e d'une salle d'attente, sans impliquer
n€cessairement une duplication. Le cache buffer (tampon de cache) du disque ou disk cache (cache de disque) est ‚
la fois un tampon oŠ transite l'information et une m€moire cache qui recopie sous forme €lectronique les donn€es
stock€es dans le disque sous forme magn€tique.
Fonctionnement
Le cache contient une copie des donn€es originelles lorsqu'elles sont co†teuses (en termes de temps d'acc•s) ‚
r€cup€rer ou ‚ calculer par rapport au temps d'acc•s au cache. Une fois les donn€es stock€es dans le cache,
l'utilisation future de ces donn€es peut „tre r€alis€e en acc€dant ‚ la copie en cache plut‰t qu'en r€cup€rant ou
recalculant les donn€es, ce qui abaisse le temps d'acc•s moyen.
Le processus fonctionne ainsi :
1.1. l'€l€ment demandeur (microprocesseur) demande une information ;
2. le cache v€rifie s'il poss•de cette information. S'il la poss•de, il la retransmet ‚ l'€l€ment demandeur – on parle
alors de succès de cache (cache hit en anglais). S'il ne la poss•de pas, il la demande ‚ l'€l€ment fournisseur
(m€moire principale par exemple) – on parle alors de défaut de cache (cache miss) ;
3.3. l'€l€ment fournisseur traite la demande et renvoie la r€ponse au cache ;
4.4. le cache la stocke pour utilisation ult€rieure et la retransmet ‚ l'€l€ment demandeur au besoin.
Si les m€moires cache permettent d'accro‹tre les performances, c'est en partie grŒce ‚ deux principes qui ont €t€
d€couverts suite ‚ des €tudes sur le comportement des programmes informatiques :

M€moire cache 2
1. le principe de localité spatiale qui indique que l'acc•s ‚ une donn€e situ€e ‚ une adresse X va probablement „tre
suivi d'un acc•s ‚ une zone tr•s proche de X. C'est €videmment vrai dans le cas d'instructions ex€cut€es en
s€quence.
2. le principe de localité temporelle qui indique que l'acc•s ‚ une zone m€moire ‚ un instant donn€ a de fortes
chances de se reproduire dans la suite imm€diate du programme. C'est €videmment vrai dans le cas des boucles de
quelques instructions seulement.
Concernant le calcul matriciel, le cache introduit en revanche de fortes dissym€tries selon qu'on acc•de la matrice
par lignes ou par colonnes, dissym€tries d'autant plus importantes que la matrice est de grande taille. Un rapport du
CNUCE[2] mentionne un €cart de performances d'un facteur 8 ‚ 10 pour des matrices dont la plus petite dimension
est 50.
Divers niveaux de mémoire cache
On trouve une zone de cache :
•• dans les disques durs ;
• dans les serveurs proxy (dont les squids) ;
• dans les serveurs de pages dynamiques ;
•• dans les m€moires g€r€es par les bases de donn€es
Dans les microprocesseurs, on diff€rencie plusieurs niveaux de caches, souvent au nombre de trois :
•• Le cache de premier niveau (L1), plus rapide et plus petit (cache de donn€es pouvant „tre s€par€ du cache
d'instructions) ;
•• Le cache de second niveau (L2), moins rapide et plus gros ;
•• Le cache de troisi•me niveau (L3), encore moins rapide et encore plus gros ;
Ces derniers caches peuvent „tre situ€s dedans ou hors du microprocesseur.
Mémoire cache des microprocesseurs
Elle est tr•s rapide, mais aussi tr•s ch•re. Il s'agit souvent de SRAM.
Diff€rents niveaux de m€moire d'un
microprocesseur
La pr€sence de m€moire cache permet d'acc€l€rer l'ex€cution d'un
programme. De ce fait, plus la taille de la m€moire cache est grande,
plus la taille des programmes acc€l€r€s peut „tre €lev€e. Il y a
cependant une limite au-del‚ de laquelle l'augmentation de la taille du
cache ne sert plus ‚ rien. En effet, dans les codes, il y a des
branchements qui ne peuvent pas „tre pr€dits par les processeurs. Ž
chaque branchement, la partie du code peut faire appel ‚ une zone m€moire diff€rente. C'est la raison pour laquelle,
"l'horizon" au-del‚ duquel le microprocesseur ne peut voir s'il aura besoin de certaines donn€es limite l’efficacit€ du
cache. La taille du cache est un €l€ment souvent utilis€ par les constructeurs pour faire varier les performances d'un
produit sans changer d'autres mat€riels. Par exemple, pour les microprocesseurs, on trouve des s€ries brid€es (avec
une taille de m€moire cache volontairement r€duite), tels que les Duron chez AMD ou Celeron chez Intel, et des
s€ries haut de gamme avec une grande m€moire cache comme les processeurs Opteron chez AMD, ou Pentium 4EE
chez Intel. Autrement dit, la taille de la m€moire cache r€sulte d'un compromis co†t/performance.
En programmation, pour profiter de l'acc€l€ration fournie par cette m€moire tr•s rapide, il faut que les parties de
programme tiennent le plus possible dans cette m€moire cache. Comme elle varie suivant les processeurs, ce r‰le
d'optimisation est souvent d€di€ au compilateur. Cela dit, un programmeur chevronn€ peut €crire son code d'une
mani•re qui optimise l'utilisation du cache.

M€moire cache 3
C'est le cas des boucles très courtes qui tiennent enti•rement dans les caches de donn€es et d'instruction, par exemple
le calcul suivant (€crit en langage C) :
long i;
double s;
s = 0.0;
for (i = 1; i < 50000000; i++)
s += 1.0 / i;
Définitions
Une ligne
le plus petit €l€ment de donn€es qui peut „tre transf€r€ entre la m€moire cache et la m€moire de niveau
sup€rieur.
Un mot
le plus petit €l€ment de donn€es qui peut „tre transf€r€ entre le processeur et la m€moire cache.
Différents types de défauts de cache (miss)
Il existe trois types de d€fauts de cache en syst•me monoprocesseur et quatre dans les environnements
multiprocesseurs. Il s'agit de :
•• les d€fauts de cache obligatoires : ils correspondent ‚ la premi•re demande du processeur pour une
donn€e/instruction sp€cifique et ne peuvent „tre €vit€s ;
•• les d€fauts de cache capacitifs : l'ensemble des donn€es n€cessaires au programme exc•dent la taille du cache, qui
ne peut donc pas contenir toutes les donn€es n€cessaires ;
•• les d€fauts de cache conflictuels : deux adresses distinctes de la m€moire de niveau sup€rieur sont enregistr€es au
m„me endroit dans le cache et s'€vincent mutuellement, cr€ant ainsi des d€fauts de cache ;
• les d€fauts de coh€rence : ils sont dus ‚ l'invalidation de lignes de la m€moire cache afin de conserver la
coh€rence entre les diff€rents caches des processeurs d'un syst•me multi-processeurs.
La correspondance (ou mapping)
La m€moire cache ne pouvant contenir toute la m€moire principale, il faut d€finir une m€thode indiquant ‚ quelle
adresse de la m€moire cache doit „tre €crite une ligne de la m€moire principale. Cette m€thode s'appelle le mapping.
Il existe trois types de mapping r€pandus dans les caches aujourd'hui :
• les m€moires caches compl•tement associatives (fully associative cache) ;
• les m€moires caches N-associatives (N-way set associative cache) ;
• les m€moires caches directes (direct mapped cache).

M€moire cache 4
Cache pleinement associatif (fully associative cache)
Chaque ligne de la m€moire de niveau sup€rieur peut „tre €crite ‚ n'importe quelle adresse de la m€moire cache.
Cette m€thode requiert beaucoup de logique car elle donne acc•s ‚ de nombreuses possibilit€s. Ceci explique
pourquoi l'associativit€ compl•te n'est utilis€e que dans les m€moires cache de petite taille (typiquement de l'ordre de
quelques kibioctets). Cela donne le d€coupage suivant de l'adresse :
Cache à correspondance préétablie (direct-mapped cache)
Chaque ligne de la m€moire principale ne peut „tre enregistr€e qu'‚ une seule adresse de la m€moire cache, par
exemple associ€e au modulo de son adresse. Cela cr€e de nombreux d€fauts de cache si le programme acc•de ‚ des
donn€es en collision sur les m„mes adresses de la m€moire cache. La s€lection de la ligne oŠ la donn€e sera
enregistr€e est habituellement obtenue par: Ligne = Adresse mod Nombre de lignes.
Mapping direct
Une ligne de cache est partag€e par de nombreuses adresses de la
m€moire de niveau sup€rieur. Il nous faut donc un moyen de savoir
quelle donn€e est actuellement dans le cache. Cette information est
donn€e par le tag, qui est une information suppl€mentaire stock€e dans
le cache. L'index correspond ‚ la ligne oŠ est enregistr€e la donn€e. En
outre, le contr‰leur de la m€moire cache doit savoir si une adresse
donn€e contient une donn€e ou non. Un bit additionnel (appel€ bit de
validit€) est charg€ de cette information.
Prenons l'exemple d'une adresse de 32 bits donnant acc•s ‚ une m€moire adressable par octet, d'une taille de ligne de
256•bits et d'une m€moire cache de kibioctets. La m€moire cache contient donc bits (1 Kio = octets et
1 octet = bits). Sachant qu'une ligne est de 256•bits soit bits, nous d€duisons qu'il y a lignes stockables
en m€moire cache. Par cons€quent, l'index est de s+5 bits.
L'adresse de 32•bits permet d'acc€der ‚ une m€moire de octets, soit bits. L'index €tant de s+5 bits, il faut
distinguer €l€ments de la m€moire principale par ligne de cache. Le tag est donc de 22-s bits.
De plus, une ligne a une taille de 256•bits soit 32•octets. La m€moire €tant adressable par octet, cela implique un
offset de 5•bits. L'offset est le d€calage ‚ l'int€rieur d'une ligne pour acc€der ‚ un octet particulier. Ces calculs

M€moire cache 5
donnent le d€coupage de l'adresse suivant pour une m€moire cache mapp€e directement :
Le mapping direct est une strat€gie simple mais peu efficace car elle cr€e de nombreux d€fauts de cache conflictuels.
Une solution est de permettre ‚ une adresse de la m€moire principale d'„tre enregistr€e ‚ un nombre limit€ d'adresses
de la m€moire cache. Cette solution est pr€sent€e dans la section suivante.
N-way set associative cache
N-way set associative cache
Il s'agit d'un compromis entre le
"mapping" direct et compl•tement
associatif essayant d'allier la simplicit€
de l'un et l'efficacit€ de l'autre.
La m€moire cache est divis€e en
ensembles (sets) de N lignes de cache.
Un ensemble est repr€sent€ sur la
figure ci-jointe par l'union des
rectangles rouges. Une ligne de la
m€moire de niveau sup€rieur est
affect€e ‚ un ensemble, elle peut par
cons€quent „tre €crite dans n'importe
laquelle des voies. Ceci permet d'€viter
de nombreux d€fauts de cache
conflictuels. Ž l'int€rieur d'un
ensemble, le mapping est Direct
Mapped, alors que le mapping des N
Sets est Full Associative. En g€n€ral,
la s€lection de l'ensemble est effectu€e par : Ensemble = Adresse mémoire mod (Nombre d'ensembles).
Reprenons l'exemple de la section pr€c€dente (m€moire cache de kibioctets) mais constitu€ de voies. Le
nombre de voies est en effet toujours une puissance de 2 afin d'obtenir un d€coupage simple de l'adresse m€moire.
La m€moire cache contient donc bits par voie. Sachant qu'une ligne repr€sente 256 bits, il y a donc
lignes par ensemble. L'index est donc de s-n+5 bits.
Les m€moires consid€r€es ici sont adressables par octet. Par cons€quent, les adresses de 32•bits donnent acc•s ‚ une
m€moire de bits, soit l'€quivalent de lignes de m€moire cache. Ainsi, chaque ensemble de la m€moire cache
contient lignes distinctes. Le tag est donc de 22-s+n bits. Le d€coupage de l'adresse est alors :
 6
7
8
6
7
8
1
/
8
100%







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}