sujet corrigé

Examen M2R Sciences Cognitives
« Cognition Bayésienne »
J. Diard & P. Bessière
27 / 01 / 2011 (durée 2h)
Note : les exercices sont indépendants et peuvent être traités dans n’importe
quel ordre ; documents et calculatrices autorisées.
Exercice 1 : « modèle de fusion capteur / modèle
de perception multi-sensorielle »
Question 1 : Rappelez la structure d’un Programme Bayésien : quelles sont
les étapes pour définir un Programme Bayésien ?
R : cf. le cours.
Question 2 : Un robot dispose de Ncapteurs S1, S2, . . . , SN. Chacun de ces
capteurs fournit une information sur une grandeur Vde l’environnement.
Rappelez le Programme Bayésien de fusion capteur qui permet de calculer
la distribution sur Vsachant les valeurs lues sur les capteurs (pour rappel,
ce Programme est aussi appelé « modèle de perception multi-sensorielle »
dans le domaine de la modélisation du vivant).
R : Le Programme Bayésien de fusion capteur a été couvert en cours ; pour
rappel, la décomposition est
P(V S1S2. . . SN) = P(V)P(S1|V)P(S2|V). . . P (SN|V).
Idéalement, la réponse est présentée sous la forme d’un PB, dont on vient
de rappeler la forme à la question précédente (c’est-à-dire, avec les vari-
ables, puis la décomposition, etc.).
Question 3 : Quelle hypothèse est au cœur de ce modèle ? Comparez ce mod-
èle avec celui qui ne ferait pas cette hypothèse : que gagne-t-on, et que
perd-on, en faisant cette hypothèse ?
R : On gagne en facilité d’écriture (un produit de termes, tous identiques), et en
espace mémoire requis ; on perd en temps de calcul (un produit plutôt qu’à
un accès dans un tableau, si le modèle complet était tabulé en mémoire),
et en pouvoir d’expression du modèle (certaines dépendances ne peuvent
plus être exprimées).
1

Exercice 2 : lois de succession de Laplace
Les lois de succession de Laplace sont des distributions de probabilité. Leur
domaine est un support discret quelconque ; pour simplifier cet exercice, on
considère que le support est une variable X, dont la valeur est un entier com-
pris entre 1et k:X={1,2,3, . . . , k}. On suppose avoir un ensemble de N
observations sur la variable X. De ces Nobservations, on ne mémorise que
le nombre de fois nique chaque valeur ia été observée : le cas (X= 1) a été
observé n1fois, le cas (X= 2) a été observé n2fois, etc. Evidemment, la somme
de tous les niest égale à N.
Définition La loi de succession de Laplace sur X, au vu des Ndonnées, est
une distribution de probabilité définie par :
P(X=i) = ni+ 1
N+k.
Question 1 : Rappelez la forme que prend la loi de succession de Laplace dans
les cas suivants :
•lorsque aucune donnée n’a encore été observée (N= 0) ;
•lorsqu’un très grand nombre de données a été observé (Ntrès grand
par rapport à k).
R : Lorsque N= 0, cela implique que tous les nisont aussi 0, et donc :
P(X=i) = ni+ 1
N+k=1
k.
La loi de succession de Laplace, avant d’avoir vu la première donnée, est
identique à une distribution de probabilité uniforme (discrète).
Lorsque Nest très grand par rapport à k,N+kdevient proche de N;
aussi, ni+ 1 devient proche de ni(sauf cas pathologiques, non développés
ici). On obtient donc :
P(X=i) = ni+ 1
N+k≈ni
N.
La loi de succession de Laplace, lorsqu’il y a beaucoup d’observations, est
très proche d’une distribution des fréquences ni/N, c’est-à-dire d’un his-
togramme.
Dans la suite de cet exercice, on va s’intéresser à généraliser la définition
des lois de succession de Laplace de plusieurs manières. Pour le premier cas, on
remarque que la formule définissant la loi de succession de Laplace est un cas
particulier de la formule suivante :
P(X=i) = ni+W
N+kW ,
où West un réel positif quelconque. Le cas précédent était donc le cas où
W= 1.
2

Question 2 : Supposons que W= 10−6. Quelle est la forme initiale de la
distribution (N= 0) ? Que devient la distribution après avoir observé la
première donnée ?
R : On obtient :
P(X=i) = ni+W
N+kW =W
kW =1
k,
et la forme initiale est toujours une distribution de probabilité uniforme.
Supposons que la première observation est le cas X=a. Alors, on obtient :
(P(X=a) = 1+W
1+kW =1+10−6
1+k.10−6≈1
P(X6=a) = 0+W
1+kW =10−6
1+k.10−6≈0.
La loi de succession de Laplace, dans ce cas, est quasiment identique à une
distribution de probabilité Dirac, centrée sur la première valeur observée.
Question 3 : Supposons que W= 106. Quelle est la forme initiale de la dis-
tribution (N= 0) ? Que devient la distribution après avoir observé la
première donnée ?
R : De la même manière que précédemment, on obtient :
P(X=i) = ni+W
N+kW =W
kW =1
k,
et la forme initiale est toujours une distribution de probabilité uniforme.
Supposons que la première observation est le cas X=a. Alors, on obtient :
(P(X=a) = 1+W
1+kW =1+106
1+k.106≈106
k.106=1
k
P(X6=a) = 0+W
1+kW =106
1+k.106≈106
k.106=1
k
.
La loi de succession de Laplace, dans ce cas, est quasiment identique à
une distribution de probabilité uniforme, après la première observation.
Question 4 : Au vu des réponses aux questions 2 et 3, donnez une interpréta-
tion du paramètre W.
R : Les questions précédentes montrent les propriétés suivantes. Premièrement,
lorsque West très petit, la loi de succession de Laplace se transforme très
vite, et passe de sa forme initiale uniforme, pour converger vers une dis-
tribution très contrainte par les données. Deuxièmement, lorsque West
très grand, la loi de succession de Laplace ne se transforme que très lente-
ment, et il faudra accumuler beaucoup d’observation avant de s’écarter de
la forme initiale, uniforme. En conséquence, Wa deux interprétations,
qui sont équivalentes : West soit proportionnel au « poids » de la forme
initiale (du prior) de la distribution, soit inversement proportionnel à la
vitesse d’apprentissage. Note : Dans la littérature, le paramètre Wa par-
fois le nom de « equivalent sample size », c’est-à-dire la taille d’un jeu de
données virtuel qu’on imaginerait avoir observé avant d’observer la vraie
première donnée.
3

On peut généraliser encore plus les lois de succession de Laplace : on se donne
kparamètres p1, p2, . . . , pk, on note Pla somme de ces paramètres P=Pk
i=1 pi,
et on redéfinit la formule des lois de succession de Laplace en :
P(X=i) = ni+W pi
N+W P .
Le cas précédent était donc le cas où tous les piétaient égaux.
Question 5 : Quelle est la forme initiale de la distribution (N= 0) ? Quelle est
la forme de la distribution après avoir observé un grand nombre de données
(Ntrès grand par rapport à W P ) ? Au vu des réponses précédentes,
donnez une interprétation de l’ensemble des paramètres pi.
R : Initialement, on a :
P(X=i) = ni+W pi
N+W P =W pi
W P =pi
P.
La loi de succession de Laplace, dans sa forme initiale, est donc une dis-
tribution discrète, dont la forme est entièrement définie par les paramètres
pi. En revanche, lorsqu’on a observé un grand nombre de données (Ntrès
grand par rapport à W P ), on a :
P(X=i) = ni+W pi
N+W P ≈ni
N.
Dans ce cas, les paramètres initiaux pin’interviennent plus, et on a con-
vergé vers une distribution de probabilité dictée par les observations. On
peut donc interpréter les picomme définissant la forme a priori de la loi
de succession de Laplace. Cette généralisation permet d’avoir une dis-
tribution quelconque pour cette forme initiale, et non plus seulement une
distribution uniforme (au prix d’un plus grand nombre de paramètres libres
à définir).
Exercice 3 : programmation bayésienne d’un robot
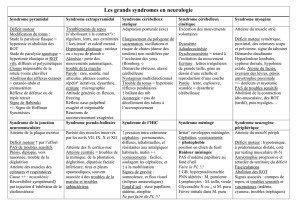
On dispose d’un robot mobile, le Koala, qui est le grand frère du Khepera :
il fait environ 30 cm de long et 25 cm de large (voir Figure 1, à gauche). Il
dispose de 16 capteurs infrarouges, similaires à ceux du Khepera, mais de plus
longue portée. De ces capteurs, on tire, grâce à des fonctions déterministes,
deux variables qui décrivent la direction Dir et la proximité P rox de l’obstacle
le plus proche.
Le Koala est piloté par ses vitesses de rotation V rot et de translation V trans.
Comme il est plus gros, on peut l’équiper d’une « tête » et d’un « oeil » : une
caméra est posée sur une petite plate-forme motorisée, qui tourne de gauche à
droite. On note θcet angle à un instant donné. La caméra est fournie avec
un logiciel de traitements d’images en temps réel, qui permet de trouver, dans
4

Figure 1: A gauche : photo du robot Koala. A droite : le logiciel de traitement
d’images utilise les couleurs des pixels pour identifier les objets, grâce aux zones
contiguës de couleur homogène. Ici, la balle (rouge) est détectée à la position
X= 30, Y = 25 (à droite et en haut).
l’image, où se trouve un objet d’une couleur donnée. Par exemple, on peut
savoir la position X, Y dans l’image, du centre d’un objet rouge (voir Figure 1,
à droite).
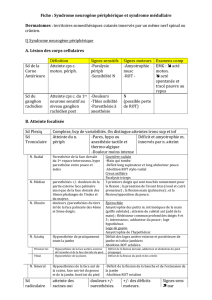
Dans cet exercice, on contrôle le Koala en utilisant le Programme Bayésien
π, dont une partie est montrée Figure 2. On y voit les domaines de définition
des variables utilisées, la décomposition et les formes paramétriques. Tous les
paramètres étant fixés, il n’y a pas de phase d’apprentissage. Les questions et
inférences sont discutées dans les questions, ci-dessous.
Les domaines des variables sont tous discrets. Les trois variables X,θet
V rot représentent des orientations ; Xest une orientation par rapport à la
direction de la caméra, et θet V rot, par rapport à l’axe central du robot. Dans
tous les cas, une valeur négative indique « à gauche », 0 indique « au centre /
droit devant », et une valeur positive indique « à droite ». Les bornes inférieures
et supérieures pour ces variables sont différentes : les fonctions f1et f2servent
à faire les changements de repères adéquats.
La variable P rox décrit la proximité d’un obstacle, qui varie entre 0, pour un
objet très loin, et 15 pour un objet très proche. Enfin, la vitesse de translation
V trans vaut entre 0 lorsque le robot n’avance pas et 10 lorsque le robot avance
à vitesse maximum.
Dans le Programme Bayésien π, on remarque que le terme P(V trans |P rox)
est défini de différentes manières, selon la valeur de P rox. Lorsque il y a un
objet très proche (P rox ≥10), la loi de contrôle sur V trans est une gaussienne
très piquée, centrée sur la valeur 0. En conséquence, le robot n’avance pas. Dans
le cas contraire, si un objet est loin (P rox < 10), la gaussienne sur V trans est
centrée sur une valeur élevée (8) : en conséquence, le robot avance à grande
vitesse.
Question 1 : Dessinez le réseau bayésien correspondant au Programme Bayé-
sien π.
5
 6
7
8
9
6
7
8
9
1
/
9
100%