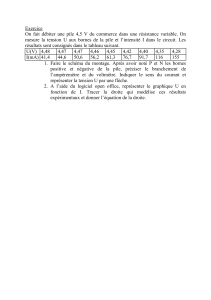
3. Du langage au programme

17/09/02 18:44
DEUG Première Année
1996 Jacques Guizol
3. Du langage au programme
3.1. Avant propos.
3.2. Le langage Assembleur.
3.3. Analyse lexicale, Automates.
3.4. Analyse syntaxique.
3.5. Introduction à la programmation.
#XCPVRTQRQU
3.1.1. La problématique.
Dans le paragraphe 1.5 nous avons introduit de façon conjointe les notions
d’instruction machine, de micro-instruction, d’assembleur, de compilateur et
d’adressage. Nous allons ici éclaircir un peu ce micmac afin d’y voir un peu plus
clair et pour finalement arriver à assimiler totalement l'illustration suivante :
Niveau des micro-instructionsNiveau des commandes
électroniques
Niveau des instructions machine
Niveau des instructions
en langage évolué
Utilisateur
Langage de
programmation
Programme
source Code
objet
Librairies
Traducteur
Editeur
de liens Code
translatable Code
exécutable
Chargeur
Micro
Code
Micro
Machine
Commandes
Editeur
de texte
Séquenceur

Page 3.2 © Jacques Guizol
Nous ne reviendrons pas sur la partie basse du schéma, c’est à dire le niveau le plus
rudimentaire (micro-instructions et commandes) qui a été traité au §1.5. Certes il y
aurait encore beaucoup de choses à dire, mais cela pourra se faire plus tard.
Rappelons simplement que ces commandes permettent des opérations de transferts de
données (de registre à registre ou entre mémoire et registre). Elles permettent également de
mettre en œuvre les échanges avec l’extérieur (entrées sorties). Par ailleurs, nous avons
déjà dit que la machine disposait de circuits spécialisés dans l’unité de calcul (UAL)
pour effectuer diverses opérations arithmétiques (addition, soustraction, division,
multiplication) et logiques (union, intersection, négation, exclusion), ainsi que des opérations
diverses sur registres (décalage et incrémentation de registres, contrôle de séquence, tests), etc.
Chacun de ces circuits doit pouvoir être sollicité via une commande. Ce catalogue
des opérations que commande et gère la CPU constitue le répertoire ou le jeu des
«opérations de la machine». Ce répertoire qui peut être assez ressemblant d’une
machine à une autre de même catégorie, présente néanmoins quelques petites
différences qui suffisent à le rendre spécifique de la machine qui en dispose. Mais la
plus grande spécificité réside dans son codage…
3.1.2. L’instruction machine.
…Ce codage est effectué très simplement : ayant la liste exhaustive de toutes les
«opérations de la machine» regroupées par type, on les numérote. Le numéro alloué
devient alors le code opération. Le lien entre code et sémantique opératoire est
totalement spécifique de la CPU et donc de son constructeur (par exemple, les proces-
seurs Intel et Motorola disposent tous deux de l’opération d’addition, mais le code correspondant est
différent).
-KQO@EOLKOKJO@KJ?aLNeOAJP@Q?K@AKLeN=PKENA0QAB=QPEHN=FKQPAN
• Les opérations arithmétiques et logiques nécessitent pour la plupart 2
opérandes ; de même, les opérations de transfert de données.
• Une opération une fois effectuée, son résultat va pouvoir être stocké à une
adresse donnée.
• Une fois l’opération achevée, il va falloir déterminer la prochaine à
effectuer par une adresse d’enchaînement.
En fonction de ces remarques, l’instruction dans son entier pourrait être codée de la
façon suivante :
Code
opératoire Adresse
1er opérande Adresse
2ème opérande Adresse
résultat
Adresse
prochaine
opération
Effectivement, un tel codage a pu être utilisé sur certaines machines. Aujourd’hui,
les capacités mémoire étant de plus en plus importantes, les adresses réclament de
plus en plus de bits. Si on multiplie le nombre d’adresses à coder, on obtient un code
de l’instruction réclamant systématiquement * plusieurs mots mémoire avec pour
conséquence un gaspillage de l’espace mémoire et une multiplication des accès pour
réaliser le traitement dans la CPU. D’où un ralentissement de l’exécution et des
performances médiocres.
On va donc essayer de réduire le plus possible la taille de ce codage.
Nous avons vu qu’une technique consiste à maintenir en permanence l’adresse de la
prochaine instruction à exécuter dans un registre : le Compteur Ordinal. En
conséquence, l’adresse d’enchaînement devient inutile.
* Chaque instruction ainsi normalisée disposera des 4 arguments, même s’il n’y a qu’un opérande, s’il est
inutile de stocker le résultat intermédiaire, etc.

Du langage au programme Page 3. 3
Si l’on suppose que les circuits à 2 opérandes de l’UAL ont tous une de leurs entrées
reliée au registre accumulateur, on résout simultanément deux problèmes :
1) au pire, un seul des deux opérandes doit être adressé ;
2) lors d’un enchaînement de calculs, les résultats intermédiaires étant
conservés dans l’accumulateur, leur sauvegarde en mémoire est inutile.
Ainsi nous économisons encore le codage de 2 informations sous réserve d’un éven-
tuel pré-chargement de l’accumulateur par le 1er opérande (pour débuter un calcul) et
d’une possibilité de sauvegarde de l’accumulateur à une adresse mémoire (pour
ranger le résultat final d’un calcul).
Donc finalement, il ne reste plus que le code opératoire et un espace permettant de
coder l’adresse d’un argument. Concernant l’adresse, nous avons vu au §1.5.2
qu’elle pouvait revêtir plusieurs formes. Il va donc falloir coder le mode d’adressage
choisi. En définitive, nous obtenons le code instruction machine qui a cette allure :
Code
opératoire Mode
d'adressage
Codage opérande selon M. adressage
....
.GNCPICIG#UUGODNGWT
Le but n’est pas ici de présenter l’assembleur spécifique de telle ou telle machine,
mais de dire ce que c’est, de présenter ses avantages et ses limites “ergonomiques”
et de l’associer à ses deux compères (l’éditeur de lien et le chargeur) que nous allons
découvrir et dont le rôle est devenu nécessaire dès lors que le dialogue avec la
machine a pu s’établir autrement qu’en langage machine.
3.2.1. Un immense progrès aujourd’hui galvaudé.
Nous venons de définir ce qu’était une instruction machine. Toujours en référence à
notre schéma de départ, que trouve-t-on à ce niveau ?… Ou plutôt, posons la ques-
tion autrement ! En fonction de nos connaissances, que peut-on faire à ce niveau ?
On peut faire exécuter des programmes certes, mais à quel prix !!?… Il va falloir les
écrire en langage machine… une suite interminable de 0 et de 1 mêlant codes
opératoires, modes d’adressage, adresses (relatives, immédiates, absolues,… ), codes de
registres, bref quelque chose d’incompréhensible.
"KIIAOE?AH=JAOQBBEO=EPL=OH=@EBBE?QHPe@AIEOA=QLKEJP@AREAJPABBN=U=JPA
5KQO=FKQPAVQJAEJOPNQ?PEKJQJAILH=?AIAJP@AOPEJeaNA?ARKENQJNeOQHP=P
PKQPAOHAO=@NAOOAOOKJPa?D=JCAN?=NPKQP=ePe@e?=He$BBN=U=JPFARKQO
@EO "YAOP @ENA OYEH AOP BNeMQAJP @Y=RKEN @AO ANNAQNO PNdO OKQRAJP JKJ
@E=CJKOPEMQeAO$P=HHAVHAONAPNKQRAN@=JO?AB=PN=OEJ@AO?NELPE>HA
5KQOL=OOAVRKPNALNKCN=IIAaQJ?KHHdCQA,AN?E!A=Q?=@A=Q2YEHRAQP
?D=JCANHAIKEJ@NAZEKP=[>KJFKQNH=FKQEOO=J?A0Q=J@KJLAJOAMQY=Q@e>QP
HYEJBKNI=PEMQA?YeP=EPcaKJOA@AI=J@A?KIIAJPHAOEJBKNI=PE?EAJOKJPLQOA
NALNK@QENAAPB=ENA@AOeIQHAO
Effectivement, la programmation en langage machine a vite cédé la place au langage
d’assemblage ou assembleur. L’assembleur est en fait un langage très pauvre
puisqu’il se situe au même niveau que le langage machine *. D’ailleurs, le lien très
étroit qui existe entre le langage d’assemblage et le langage machine le rend
dépendant de la machine et de son processeur. Mais il a l’énorme avantage de
* Une instruction assembleur correspond exactement à une instruction machine.

Page 3.4 © Jacques Guizol
disposer de codes mnémoniques pour les opérations (ADD, SUB, MP, DIV, MOVE,… ), de
directives de déclaration (une table est totalement définie en une ligne d’assembleur qui indique
un nom symbolique (adresse), le type de ses éléments (octet, mot, double mot) et le nombre de ces
éléments) et surtout, il offre la possibilité de désigner adresses, variables, noms de
registres, etc. sous une forme symbolique.
Au final, bien que l’écriture d’un programme en assembleur ne représente pas
nécessairement une partie de plaisir, elle s’avère “incomparablement plus” agréable
qu’en langage machine. D’ailleurs, l’assembleur est toujours d’actualité et même si
certains ricanent en parlant des “fêlés de l’assembleur” il n’en reste pas moins vrai
que si certaines portions d’un logiciel sont particulièrement utilisées, on aura tout
intérêt à les écrire en assembleur pour bénéficier de la meilleure optimisation
possible.
4JABKEO?ALNKCN=IIAe?NEPAJH=JC=CA=OOAI>HAQNEHB=QP@KJ? HAPN=@QENA AJ
H=JC=CAI=?DEJA0QEOYAJ?D=NCA
L’assembleur !
Oui, en fait le langage lui-même et son traducteur ont le même nom !
D>KJ"YAOPO=JO@KQPA?AMQAHYKJ=LLAHHAQJ=>QO@AH=JC=CA
La traduction va avoir pour effet, à partir du programme source, de générer un
programme objet (comme la publicité et la presse de pacotille traduisent la femme source en
femme objet).
3.2.2. L’éditeur de liens.
Ce programme objet produit est rarement complet ; il est improbable qu’il puisse se
suffire à lui-même. Certaines directives ou certaines opérations permettent de faire
le lien avec des informations extérieures.
Ainsi un programme va être constitué d’un regroupement de plusieurs modules de
provenances diverses :
• Un programme gagnera en clarté s’il est découpé en “ morceaux” chacun
ayant une fonction propre. Ainsi le programme principal se résumera à la
réservation de place pour les données communes aux divers “ morceaux”
et aux appels de ceux-ci, aux endroits désirés, grâce à une instruction
regroupant une code spécifique et un argument adresse. Ces “ morceaux”
de programme sont appelés sous-programmes.
• Etant donné qu’il est inutile que chacun réinvente à chaque instant le fil à
couper le beurre, un programme va aussi faire appel à toute une batterie
de fonctions particulières rassemblées dans des librairies (fonctions mathéma-
tiques, statistiques, de traitement de chaînes de caractères, etc.).
• Enfin, systématiquement, tout programme utilisateur fait appel à des
“ morceaux” d’un programme particulier : le logiciel système. C’est le cas
dès que le programme doit opérer des opérations d’entrée-sortie avec un
quelconque périphérique ; c’est aussi le cas si le programme fait appel à
des primitives graphiques, audio ou autres ; c’est encore le cas si une
erreur fatale se produit en cours d’exécution.
Mises à part les routines systèmes, tous ces petits morceaux pris ici ou là sont en fait
sous la forme de code objet. Chacun ayant été traduit séparément, les adresses et
références internes supposent une adresse origine en 0. Quant aux références
externes, appel à des sous-programmes, à des parties de librairies, elles demeurent
non résolues.

Du langage au programme Page 3. 5
C’est l’éditeur de liens (linker) qui va organiser tous ces modules, résoudre les
références externes pour enfin produire un code translatable.
Données P
Programme
principal
0
λPAppel SP1
Appel SP2
Appel fonction F2
Appel fonction F4
....
.
....
.
...
...
...
t
P
-1
Données SP2
0
Appel fonction F3
....
.
λ
SP2
t
SP2
-1
....
.
Sous-programme
SP2
Définitionfonct. F1
Définitionfonct. F2
λF1
0
...
....
.
...
λF2
t
L1
-1
Module de
librairie L1
Appel SP2
Appel fonction F1
...
...
...
Données SP1
λ
SP1
0
t
SP1
-1
Sous-programme
SP1
Définitionfonct. F3
Définitionfonct. F4
λF3
0
Module de
librairie L2
...
...
λF4 ...
t
L2
-1
Editeur
de liens
Vers tL1+tL2+λSP1
Vers tL1+tL2+tSP1+λSP2
Vers λF2
Vers tL1+λF4
Vers tL1+tL2+tSP1+λSP2
Vers λF1
Vers tL1+λF3
Définitionfonct. F1
Définitionfonct. F2
Définitionfonct. F3
Définitionfonct. F4
λF1
λF2
tL1
tL1+tL2
tL1+tL2+λSP1
tL1+tL2+tSP1+λSP2
tL1+tL2+tSP1+tSP2+λP
tL1+tL2+tSP1+tSP2+tP-1
0
tL1+λF3
tL1+λF4
tL1+tL2+tSP1
tL1+tL2+tSP1+tSP2
... ........ ...... ... ...... ............. ..
.... ..... ......
Données SP1
Données SP2
Données P
Dans la figure ci-dessus, est présenté l’exemple d’un
program
me P comportant deux sous-program
mes SP1 et
SP2 et faisant appel, soit directement, soit au travers de
ses sous-program
mes, à deux modules de librairies.
Chaque “ morceau” ayant été traduit est donc en code
machine, ses adresses étant référencées par rapport à son
propre début
(adresse 0)
. L’éditeur de lien, lors de la
construction du code
translatable, va, à partir de l’origine
(au départ, le programme principal)
, considérer une à une les
références non résolues et rechercher la définition corres-
pon
dante dans les fichiers indiqués par l’utilisateur.
Une
fois celle-ci trouvée, le fichier la contenant est ajouté à la
suite de ceux précédemment trouvés comme cela est
montré dans la figure ci-contre.
A l’issue de ce traitement, tous les modules sont donc
réunis dans un seul fichier commençant à l’adresse 0 et
toutes les références ont été résolues relativement à celle-
ci et en fonction de l’ordre d’insertion des divers modules
dans le fichier global.
Par exemple, l’appel du sous-programme SP2 dans SP1
sera traduit par une instruction comportant l’adresse de
lancement de SP2,
λ
SP2
. Comme ce module a été chargé
après les 2 librairies et SP1, donc à l’adresse t
L1
+t
L2
+t
SP1
,
l’adresse sera en fait tL1+tL2+tSP1+λSP2.
#=JOH=@eJKIEJ=PEKJ@Q?K@ALNK@QEPL=NHYe@EPAQN@AHEAJ=LL=N=gPHAMQ=HEBE?=PEB
ZPN=JOH=P=>HA[ 0QA OECJEBEAPEH +A ?K@A LNK@QEP JYAOPEH L=O @ENA?PAIAJP
ATe?QP=>HA
Nous avons bien précisé que le code objet produit débutait à l’adresse 0 et toutes les
références internes étaient calculées en fonction de cela. Or, lorsque le programme
va être chargé en mémoire centrale pour être exécuté, il le sera à une adresse
quelconque. Donc toutes les références devront être translatées. C’est cette dernière
opération que doit encore subir le translatable pour devenir exécutable.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
1
/
43
100%