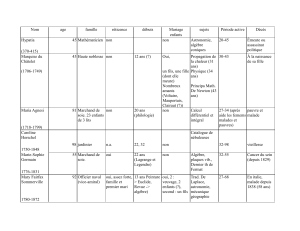
Algèbre linéaire Applications à la modélisation des données


Sommaire
1Introduction
2Analyse du problème
Approche générale
Approche statistique
Moindres carrés
3Ajustement linéaire
Régression linéaire
Cas linéaire général
La qualité du fit
4Cas Non-Linéaire
Généralités
Méthode du gradient conjugué
5Qualité de l’ajustement : cas général
MNCS — Noé Lahaye (UPMC) Algèbre linéaire 12 mars 2013 2 / 37

Sommaire
1Introduction
2Analyse du problème
Approche générale
Approche statistique
Moindres carrés
3Ajustement linéaire
Régression linéaire
Cas linéaire général
La qualité du fit
4Cas Non-Linéaire
Généralités
Méthode du gradient conjugué
5Qualité de l’ajustement : cas général
MNCS — Noé Lahaye (UPMC) Algèbre linéaire 12 mars 2013 2 / 37

Sommaire
1Introduction
2Analyse du problème
Approche générale
Approche statistique
Moindres carrés
3Ajustement linéaire
Régression linéaire
Cas linéaire général
La qualité du fit
4Cas Non-Linéaire
Généralités
Méthode du gradient conjugué
5Qualité de l’ajustement : cas général
MNCS — Noé Lahaye (UPMC) Algèbre linéaire 12 mars 2013 2 / 37

Sommaire
1Introduction
2Analyse du problème
Approche générale
Approche statistique
Moindres carrés
3Ajustement linéaire
Régression linéaire
Cas linéaire général
La qualité du fit
4Cas Non-Linéaire
Généralités
Méthode du gradient conjugué
5Qualité de l’ajustement : cas général
MNCS — Noé Lahaye (UPMC) Algèbre linéaire 12 mars 2013 2 / 37
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
1
/
48
100%