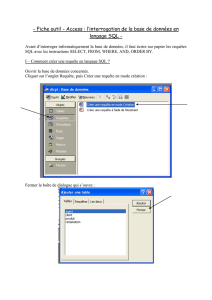
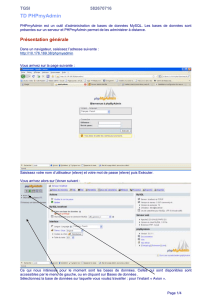
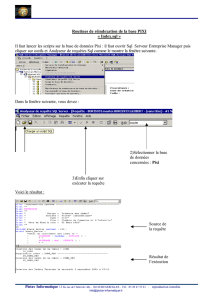
cours de bases de donnees

Cours de bases de données
Philippe Rigaux
19 juin 2003


TABLE DES MATIÈRES
3
Table des matières
1 Introduction 7
2 Présentation générale 9
2.1 Données, Bases de données et SGBD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Que doit-on savoir pour utiliser un SGBD? . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.1 Définition du schéma de données . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.2 Les opérations sur les données . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.3 Optimisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.4 Concurrence d’accès . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Le plan du cours . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
I Modèles et langages 15
3 Le modèle Entité/Association 17
3.1 Principes généraux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.1 Bons et mauvais schémas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.2 La bonne méthode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Le modèle E/A: Présentation informelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3 Lemodèle........................................... 21
3.3.1 Entités, attributs et identifiants . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3.2 Associations binaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3.3 Entités faibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3.4 Associations généralisées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.4 Avantage et inconvénientsdu modèle E/A . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4 Le modèle relationnel 33
4.1 Définition d’un schéma relationnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.2 Passage d’un schéma E/A à un schéma relationnel . . . . . . . . . . . . . . . . . . . . . . 35
4.2.1 Règles générales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2.2 Retour sur le choix des identifiants . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2.3 Dénormalisation du modèle logique . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3 Le langage de définition de données SQL2 . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3.1 Types SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3.2 Création des tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3.3 Contraintes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3.4 Modification du schéma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.4 Exercices ........................................... 50

TABLE DES MATIÈRES
4
5 L’algèbre relationnelle 53
5.1 Les opérateurs de l’algèbre relationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.1.1 La sélection, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.1.2 La projection, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.1.3 Le produit cartésien, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.1.4 L’union, ...................................... 57
5.1.5 La différence, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5.1.6 Jointure, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5.2 Expression de requêtes avec l’algèbre . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.2.1 Sélection généralisée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.2.2 Requêtes conjonctives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2.3 Requêtes avec et . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.3 Exercices ........................................... 62
6 Le langage SQL 65
6.1 Requêtes simples SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.1.1 Sélections simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.1.2 La clause WHERE ................................... 68
6.1.3 Valeurs nulles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.2 Requêtes sur plusieurs tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.2.1 Jointures ....................................... 70
6.2.2 Union, intersection et différence . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.3 Requêtes imbriquées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.3.1 Conditions portant sur des relations . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.3.2 Sous-requêtes correllées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.4 Agrégration.......................................... 74
6.4.1 Fonctions d’agrégation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.4.2 La clause GROUP BY ................................ 75
6.4.3 La clause HAVING .................................. 76
6.5 Mises-à-jour . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.5.1 Insertion ....................................... 76
6.5.2 Destruction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.5.3 Modification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
6.6 Exercices ........................................... 77
7 Schémas relationnels 79
7.1 Schémas............................................ 80
7.1.1 Définition d‘un schéma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
7.1.2 Utilisateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
7.2 Contraintes et assertions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
7.3 Vues.............................................. 83
7.3.1 Création et interrogation d’une vue . . . . . . . . . . . . . . . . . . . . . . . . . 83
7.3.2 Mise à jour d’une vue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
7.4 Triggers ............................................ 85
7.4.1 Principes des triggers ................................. 85
7.4.2 Syntaxe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
7.5 Exercices ........................................... 87
8 Programmation avec SQL 89
8.1 Interfaçage avec le langage C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
8.1.1 Un exemple complet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
8.1.2 Développement en C/SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
8.1.3 Autres commandes SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
8.2 L’interface Java/JDBC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95

TABLE DES MATIÈRES
5
8.2.1 Principes de JDBC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
8.2.2 Le plus simple des programmes JDBC . . . . . . . . . . . . . . . . . . . . . . . . 97
8.2.3 Exemple d’une applet avec JDBC . . . . . . . . . . . . . . . . . . . . . . . . . . 98
II Aspects systèmes 103
9 Techniques de stockage 105
9.1 Stockage de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
9.1.1 Supports ....................................... 106
9.1.2 Fonctionnement d’un disque . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
9.1.3 Optimisations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
9.1.4 Technologie RAID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
9.2 Fichiers ............................................ 115
9.2.1 Enregistrements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
9.2.2 Blocs ......................................... 117
9.2.3 Organisation d’un fichier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
9.3 Oracle............................................. 123
9.3.1 Fichiers et blocs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
9.3.2 Les tablespaces .................................... 127
9.3.3 Création des tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
10 Indexation 131
10.1 Indexation de fichiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
10.1.1 Index non-dense . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
10.1.2 Index dense . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
10.1.3 Index multi-niveaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
10.2L’arbre-B ........................................... 137
10.2.1 Présentation intuitive . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
10.2.2 Recherches avec un arbre-B+ . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
10.3Hachage............................................ 142
10.3.1 Principes de base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
10.3.2 Hachage extensible . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
10.4 Les index bitmap ....................................... 146
10.5 Indexation dans Oracle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
10.5.1 Arbres B+ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
10.5.2 ArbresB ....................................... 149
10.5.3 Indexation de documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
10.5.4 Tables de hachage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
10.5.5 Index bitmap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
11 Évaluation de requêtes 153
11.1 Introduction à l’optimisation des performances . . . . . . . . . . . . . . . . . . . . . . . 154
11.1.1 Opérations exprimées par SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
11.1.2 Traitement d’une requête . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
11.1.3 Mesure de l’efficacité des opérations . . . . . . . . . . . . . . . . . . . . . . . . . 155
11.1.4 Organisation du chapitre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
11.2 Algorithmes de base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
11.2.1 Recherche dans un fichier (sélection) . . . . . . . . . . . . . . . . . . . . . . . . 157
11.2.2 Quand doit-on utiliser un index? . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
11.2.3 Le tri externe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
11.3 Algorithmes de jointure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
11.3.1 Jointure par boucles imbriquées . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
11.3.2 Jointure par tri-fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
1
/
224
100%