II-2 - Ceremade

1
2007 - 2008
Master MIAGE & DECISION
Spécialité : Informatique décisionnelle
PROJET DATAMINING
Recherche des profils patients dépassant la durée
normale de séjour au centre hospitalier de
Poissy-St Germain en Laye
Etudiants :
Alpha Oumar BAH
Aurel CRECIUN
Tuteur : Professeur Edwin DIDAY

2
S
SO
OM
MM
MA
AI
IR
RE
E
Sommaire __________________________________________________________________ 2
INTRODUCTION ________________________________________________________________ 3
Première Partie4:Présentation du datamining et du logiciel sodas ________________________ 4
1 - Objectifs généraux du DATAMINING ____________________________________________ 4
1-1 Caractéristiques et ouvertures l’analyse des données symboliques ______________________________ 4
1-2 Avantages des objets symboliques ______________________________________________________ 5
2- Etude de marché des outils Datamining ____________________________________________ 6
2-1 Panorama des outils existant sur le marché (Benchmark) _____________________________________ 6
2-2 Le logiciel SODAS (Symbolic Official Data Analysis System) ________________________________ 7
3- Description sommaire du mode opératoire _________________________________________ 9
3-1 Les principaux onglets de Sodas ________________________________________________________ 9
3-2 Sélection d’une base d’étude __________________________________________________________ 10
3-3 Choix des méthodes à appliquer _______________________________________________________ 10
Partie 2 : ETUDE STATISTIQUE _________________________________________________ 14
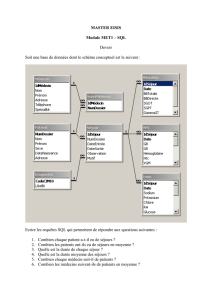
II –1 Présentation de l’étude ______________________________________________________ 14
II –1-1 Contexte de l’étude et présentation des données ________________________________________ 14
II –1-2 L’analyse ______________________________________________________________________ 16
1. DB2SO : extraction de données symboliques de la base de données relationnelles _______________ 16
II-2 Présentation des méthodes et résultats __________________________________________ 21
II-2 -1 Méthode View __________________________________________________________________ 21
a- Présentation de la méthode __________________________________________________________ 21
b. Mise en oeuvre de la méthode View ___________________________________________________ 22
II-2 -2 La méthode STAT _______________________________________________________________ 25
a- Présentation de la méthode STAT_____________________________________________________ 25
b. Mise en oeuvre de la méthode STAT __________________________________________________ 26
II-2 -3 La méthode DIV : Divisive Clustering on Symbolic Objects _______________________________ 30
a- Présentation de la méthode DIV ______________________________________________________ 30
b- Mise en oeuvre de la méthode DIV ___________________________________________________ 31
II-2-4 La méthode TREE : Decision Tree ___________________________________________________ 34
a-Présentation de la méthode TREE _____________________________________________________ 34
b-Mise en oeuvre de la méthode TREE __________________________________________________ 34
II-2-5. La méthode PYR : Pyramical Clustering on Symbolic Objects _____________________________ 35
a- Présentation de la méthode PYR ______________________________________________________ 35
b- Mise en oeuvre de la méthode PYR ___________________________________________________ 36
II-2-6 PCA : Principal Component Analysis _________________________________________________ 36
a- Présentation de la méthode PCA ______________________________________________________ 36
b. Mise en oeuvre de la méthode PCA ___________________________________________________ 37
II-2-7 La méthode DISS/MATCH _________________________________________________________ 39
a- Présentation de la méthode _______________________________________________________ 39
b-Mise en oeuvre de la méthode ________________________________________________________ 39
II-2-8 Les méthodes clustering (SCLUST) __________________________________________________ 40
a- Présentation de la méthode _______________________________________________________ 40
b- Mise en œuvre de la méthode ________________________________________________________ 40
II-2-9 La méthode de SYKSOM __________________________________________________________ 42
Conclusion_______________________________________________________________45

3
INTRODUCTION
Désormais, le Datamining est au coeur de toutes les préoccupations du monde des
affaires. C’est un processus qui permet de découvrir, dans de grosses bases de données
consolidées, des informations jusque là inconnues mais qui peuvent être utiles et lucratives et
d'utiliser ces informations pour soutenir des décisions commerciales tactiques et stratégiques.
Les approches traditionnelles de la statistique ont des limites avec de grosses bases de
données, car en présence de milliers ou de millions d’individus et de centaines ou de milliers de
variables, on trouvera forcément un niveau élevé de redondance parmi ces variables. Les
techniques de datamining interviennent et offrent des réponses à l’analyse de données
volumineuse et nous permettra d’extraire des informations intéressantes et apportent de
nouvelles connaissances jusque là inconnues, que les méthodes statistiques classiques n’ont pas
mit en avant.
L’exploitation de ces nouvelles informations peut présenter un intérêt pour analyser et
interpréter les comportements d’individus et ensemble d’individus. Les résultats obtenus
s’insérant dans un dispositif d’analyse globale permettent alors de dresser dans des plans
stratégiques ou politiques les axes d’effort à respecter.
Les techniques du datamining sont regroupées dans deux principales catégories :
Les méthodes descriptives qui visent à structurer et à simplifier les données issues de
plusieurs variables, sans privilégier l'une d'entre elles en particulier, il s’agit notamment
de l'analyse en composantes principales (ACP), l'analyse factorielle des
correspondances (AFC), l'analyse des correspondances multiples (ACM) et des
méthodes de classification automatiques.
Les méthodes explicatives qui visent à expliquer une variable à l'aide de deux ou
plusieurs variables explicatives, les principales méthodes utilisées dans les enquêtes sont
la régression multiple, l'analyse discriminante et la segmentation (arbres de décision).
L’analyse des données symboliques prend actuellement de plus en plus d’importance, comme
en témoigne le développement du logiciel spécifique SODAS. C’est ce logiciel qui va être
utilisé dans le cadre de ce projet afin d’extraire les données concentrées dans une base de
donnée relationnelle de type ACCESS, SQL Server, BO et d’y appliquer les principales
méthodes d’analyse proposées dans SODAS.
L’étude datamining que nous réaliserons ici porte sur la recherche des profils patients
qui dépassent la durée normale de séjour dans un centre hospitalier
Le présent rapport est constitué de deux parties. La première est une présentation
générale du datamining et du logiciel SODAS. La deuxième partie portera sur la présentation de
méthodes, l’analyse et l’interprétation des résultats obtenus.

4
PREMIERE PARTIE
PRESENTATION DU DATAMINING ET DU LOGICIEL SODAS
1 - OBJECTIFS GENERAUX DU DATAMINING
Les progrès de la technologie informatique dans le recueil et le transport de données font
que dans tous les grands domaines de l’activité humaine, des données de toutes sortes
(numériques, textuelles, graphiques…) peuvent maintenant être réunies et en quantité souvent
très importante.
Les systèmes d’interrogation des données, qui n’étaient autrefois réalisables que via des
langages informatiques nécessitant l’intervention d’ingénieurs informaticiens de haut niveau,
deviennent de plus en plus simples d’accès et d’utilisation.
Résumer ces données à l’aide de concepts sous-jacents (une ville, un type de chômeur,
un produit industriel, une catégorie de panne …), afin de mieux les appréhender et d’en extraire
de nouvelles connaissances constitue une question cruciale. Ces concepts sont décrits par des
données plus complexes que celles habituellement rencontrées en statistique. Ces données sont
dites « symboliques », car elles expriment la variation interne inéluctable des concepts et sont
structurées.
Dans ce contexte, l’extension des méthodes de l’Analyse des Données Exploratoires et
plus généralement, de la statistique multidimensionnelle à de telles données, pour en extraire
des connaissances d’interprétation aisée, devient d’une importance grandissante.
L’analyse porte sur des « atomes », ou « unités » de connaissances (les individus ou
concepts munis de leur description) considérés au départ comme des entités séparées les unes
des autres et qu’il s’agit d’analyser et d’organiser de façon automatique.
1-1 Caractéristiques et ouvertures de l’analyse des données
symboliques
Par rapport aux approches classiques, l’analyse des données symboliques présente les
caractéristiques et ouvertures suivantes :
Elle s’applique à des données plus complexes. En entrée elle part de données
symboliques (variables à valeurs multiples, intervalle, histogramme, distribution de probabilité,
de possibilité, capacité …) munies de règles et de taxonomies et peut fournir en sortie des
connaissances nouvelles sous forme d’objets symboliques présentant les avantages qui sont
développés supra :
Elle utilise des outils adaptés à la manipulation d’objets symboliques de
généralisation et de spécialisation, d’ordre et de treillis, de calcul d’extension,
d’intention et de mesures de ressemblances ou d’adéquation tenant compte des
connaissances sous-jacentes basées sur les règles de taxonomies ;
Elle fournit des représentations graphiques exprimant, entre autres, la variation
interne des descriptions symboliques. Par exemple, en analyse factorielle, un objet
symbolique sera représenté par une zone (elle-même exprimable sous forme d’objet
symbolique) et pas seulement par un point ;

5
1-2 Avantages des objets symboliques
Les principaux avantages des objets symboliques peuvent se résumer comme suit :
Ils fournissent un résumé de la base, plus riche que les données agrégées habituelles
car ils tiennent compte de la variation interne et des règles sous-jacentes aux classes
décrites, mais aussi des taxonomies fournies. Nous sommes donc loin des simples
centres de gravité ;
Ils sont explicatifs, puisqu’ils s’expriment sous forme de propriétés des variables
initiales ou de variables significatives obtenues (axes factoriels), donc en termes
proches de l’utilisation ;
En utilisant leur partie descriptive, ils permettent de construire un nouveau tableau
de données de plus haut niveau sur lequel une analyse de données symboliques de
second niveau peut s’appliquer ;
Afin de modéliser des concepts, ils peuvent aisément exprimer des propriétés
joignant des variables provenant de plusieurs tableaux associés à différentes
populations. Par exemple, pour construire un objet symbolique associé à une ville,
on peut utiliser des propriétés issues d’une relation décrivant les habitants de chaque
ville et une autre relation décrivant les foyers de chaque ville.
Plutôt que de fusionner plusieurs bases pour étudier ensuite la base synthétique
obtenue, il peut être plus avantageux d’extraire d’abord des objets symboliques de
chaque base puis d’étudier l’ensemble des objets symboliques ainsi obtenus ;
Ils peuvent facilement être transformés sous forme de requête sur une Base de
Données.
Ils peuvent donc propager les concepts qu’ils représentent d’une base à une autre
(par exemple, d’un pays à l’autre de la communauté européenne, EUROSTAT ayant
fait un grand effort de normalisation des différents types d’enquête
sociodémographiques).
Alors qu’habituellement on pose des questions sous forme de requête à la base de
données pour fournir des informations intéressant l’utilisateur, les objets
symboliques formés à partir de la base par les outils de l’analyse des données
symboliques permettent à l’inverse de définir des requêtes et donc de fournir des
questions qui peuvent être pertinentes à l’utilisateurs.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
1
/
46
100%