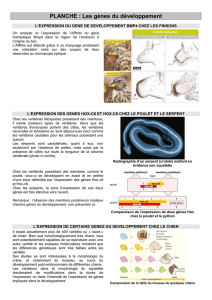
Prise en compte des connaissances du domaine dans l`analyse

AVERTISSEMENT
Ce document est le fruit d'un long travail approuvé par le jury de
soutenance et mis à disposition de l'ensemble de la
communauté universitaire élargie.
Il est soumis à la propriété intellectuelle de l'auteur. Ceci
implique une obligation de citation et de référencement lors de
l’utilisation de ce document.
D'autre part, toute contrefaçon, plagiat, reproduction illicite
encourt une poursuite pénale.
Contact : ddoc-theses-contact@univ-lorraine.fr
LIENS
Code de la Propriété Intellectuelle. articles L 122. 4
Code de la Propriété Intellectuelle. articles L 335.2- L 335.10
http://www.cfcopies.com/V2/leg/leg_droi.php
http://www.culture.gouv.fr/culture/infos-pratiques/droits/protection.htm

D´epartement de formation doctorale en informatique ´
Ecole doctorale IAEM Lorraine
UFR Sciences & Technologies
Prise en compte des connaissances du
domaine dans l’analyse
transcriptomique : Similarit´e
s´emantique, classification fonctionnelle
et profils flous.
Application au cancer colorectal.
TH`
ESE
pr´esent´ee et soutenue publiquement le 15 D´ecembre 2011
pour l’obtention du
Doctorat de l’universit´e Henri Poincar´e – Nancy 1
(sp´ecialit´e informatique)
par
Sidahmed Benabderrahmane
Composition du jury
Pr´esident : Am´ed´eo Napoli Directeur de recherche, CNRS, Loria, Nancy.
Rapporteurs : Youn`es Bennani Professeur, LIPN Universit´e Paris-Nord.
Christine Froidevaux Professeur, LRI Universit´e Paris-Sud.
Examinateurs : Charles Auffray Directeur de recherche, CNRS, Paris.
Maude Pupin Maitre de conf´erence, LIFL Universit´e de Lille.
Samy Tindel Professeur, U. Henri Poincar´e IECN, Nancy.
Olivier Poch Directeur de recherche, CNRS, Strasbourg.
Marie-Dominique Devignes Charg´ee de recherche, CNRS, Loria, Nancy.
Invit´e(e) : Malika Smail-Tabbone Maitre de conf´erence, U. Henri Poincar´e, Loria, Nancy.
Laboratoire Lorrain de Recherche en Informatique et ses Applications — UMR 7503

Mis en page avec la classe thloria.

Remerciements
Je voudrais tout d’abord remercier M. Younès Bennani et Mme Christine Froidevaux pour
leur disponibilité et d’avoir accepté de juger ce manuscrit.
Je remercie aussi M. Charles Auffray, M. Samy Tindel, Mme Maude Pupin d’avoir accepté de
participer au jury de cette thèse.
Je tiens à remercier également M. Amedeo Napoli qui m’a donné l’occasion de faire partie de
son équipe d’Orpailleurs, de m’avoir soutenu dans les moments difficiles, Grazie mille Amedeo.
Je remercie aussi M. Olivier Poch mon co-directeur de thèse, Wolfgang Raffelsberger et Hoan
Ngoc Nguyen de leurs précieux échanges et enseignements en bioinformatique.
Je n’oublierai jamais M. Antoine Tabbone, qui m’a transféré un certain mail. Si je suis en train
d’écrire cette page dans ce manuscrit, c’est grâce à ton click Antoine.
Je suis trés reconnaissant à l’INCa et la ligue contre le cancer de m’avoir accordé la bourse de
thèse et la convention complémentaire qui m’a permis matériellement de poursuivre ma formation
et de réaliser tous ces travaux. Merci aussi à Sébastien Retter pour son aide dans les justificatifs
et les contrats.
J’en profite pour remercier aussi toutes les personnes qui travaillent dans le service des étrangers
à la préfecture de Meurthe et Moselle, à l’Office d’immigration (OFII) de Metz et de Nancy, ainsi
qu’à l’inspection de travail de Vandoeuvre.
Je tiens à ne pas oublier tous ceux qui ont partagé leur quotidien avec moi au Loria, j’ai passé
des moments agréables avec vous. Je pense à Nizar, Birama, Emmanuel, Renaud (allez le PSG,
staghfir-allah, allez l’OM), Jean-François (merci pour les conseils info), Houari, Yahia, Elias,
Chedy (people of Gaza we are with you), Mohamed, Yakoub, Tarek, Bilel, Sofiane, Fares, Hamza,
Yacine, Adam, Ibrahim,...
Je remercie aussi tous mes amis d’enfance en Algérie, Abdelmouneim, Jamal, Ali, Boucif, Dino,
Abdelaziz, Abdallah, Abdli, Boumedien, Said, Djillali, Boubakar et tous les autres amis. Rendez-
vous, l’été prochain incha’allah, à la plage Hafer-Jmel.
Je remercie tous les membres des familles Benabderrahmane, Mekami et Slimani. Merci pour
votre soutien. Merci mon père pour ton encouragement. Merci ma mère, je n’oublierai jamais
quand tu gâchais ton sommeil pour me réveiller. Vous restez dans mon coeur.
Merci à chaque personne qui m’a enseigné une lettre, de l’école primaire jusqu’à maintenant.
Last but not least, Malika et Marie-Dominique, je n’arrive pas à trouver les mots justes pour
vous remercier de votre soutien, de votre accompagnement, de vos conseils, de vos enseignements
tant scientifiques qu’humains. Je garderai cela en mémoire. Thanmirt Malika, et merci du fond
du coeur Marie-Dominique.
i

ii
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
1
/
206
100%