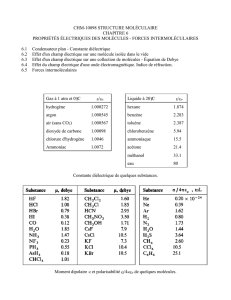
Relations entre Dynamique et Contraintes et

Quel rôle pour le hasard en biologie moléculaire ?
Il existe aujourd’hui une série d’arguments qui suggèrent des mécanismes probabilistes dans
le fonctionnement de la cellule (voir les articles de A. Paldi, S. Atamas et de J.J. Kupiec dans
le No ??). Une telle hypothèse heurte de front la vision traditionnelle qui impose un
déterminisme très fort aux phénomènes du vivant (voir l’article de J. Gayon). Bien que
l’expérimentation directe sur la nature soit la pierre angulaire de la méthode scientifique, la
simulation des processus naturels à l’aide d’ordinateurs est devenue un outil puissant
d’investigation mis à la disposition des chercheurs. Elle permet d’évaluer les conséquences
d’une hypothèse à n’importe quelle échelle (microscopique ou macroscopique) du système
étudié dans un cadre complètement maîtrisé. Cette approche permet d’aborder la question :
Est-ce que des cellules régies par des lois aléatoires peuvent donner naissance à des tissus
ordonnés ?
A notre échelle la grande majorité des phénomènes naturels sont régis par des lois
déterministes (lois de newton,…) alors que tous les corps sont faits d’atomes et de molécules
dont le comportement individuel microscopique est régi par la mécanique quantique dont le
caractère statistique a été largement vulgarisé. Même dans le cadre d’une théorie classique, la
notion de chaos conduit à décrire la dynamique de ces constituants à l’aide de probabilités.
Cela semble parfois paradoxal ou difficile à comprendre. En fait, lorsque nous étudions un
objet étendu (un gaz, de l’eau dans un verre, etc.) nous observons le comportement du grand
nombre de particules qui le composent. Les variations aléatoires des molécules se compensent
et laissent place à un effet moyen dont la variation dans le temps est extrêmement faible,
correspondant à un phénomène déterministe. C’est sur cette base que la physique statistique
réussit par exemple à définir les grandeurs thermodynamiques d’un gaz (Température,
Pression,…) à partir d’un modèle microscopique de molécules en mouvement.
Il est donc légitime de se demander si une telle dynamique probabiliste pourrait également
générer de l’ordre en biologie. Les enjeux sont évidemment énormes puisque jusqu’à présent
on y a éliminé le hasard et au contraire, fait appel à des concepts éminemment déterministes
tels que l’information ou le programme génétiques. Cependant, on ne peut discuter de
dynamique sans parler de contraintes. Tous les systèmes y sont soumis. Imaginez une bille qui
se déplace au hasard. Elle est toujours dans un environnement qui participe à l’orientation de
son mouvement. Si elle est placée entre deux murs parallèles très rapprochés elle se déplacera
dans la direction du couloir en rebondissant sur ces murs alors qu’elle est intrinsèquement
régie par le hasard. Ce que les biologistes appellent sélection correspond à ce qu’un physicien
appelle une contrainte. La première contrainte est environnementale. Il s’agit de la sélection
naturelle qui oriente l’évolution d’êtres vivants soumis au hasard des mutations. Mais, on peut
utiliser cette même logique à l’intérieur de la cellule. Il faut alors prendre en compte sa
structure sous tous ses aspects physico-chimiques qui deviennent autant de contraintes.
L’ADN peut lui-même être vu sous cet angle. Tous les résultats expérimentaux montrent que
certaines zones de l’ADN ont des corrélations très fortes avec certains caractères (phénotype)
de la cellule ; ce sont les gènes au sens classique. Ces régions de l’ADN peuvent donc être
envisagées comme des contraintes très fortes sur la structuration cellulaire qui serait
intrinsèquement probabiliste. Dans cette perspective, un gène est donc une gêne plutôt que
l’instruction déterministe du programme génétique.
Afin de démontrer la pertinence d’une dynamique aléatoire pour les systèmes biologiques,
nous avons modélisé des systèmes cellulaires extrêmement simples. La différentiation
cellulaire y est réglée par des règles stochastiques soumises à des contraintes équivalentes à la

sélection naturelle appliquée au niveau cellulaire. Dans ces modélisations, les cellules sont
immobiles et vivent sur une grille à deux dimensions. Elles peuvent être Rouge ou Verte, et ce
choix se fait par tirage au sort. C’est le côté probabiliste du modèle. Quand elles sont d’une
couleur donnée, elles secrètent (expression génétique) des molécules R ou V. Ces molécules
diffusent dans le milieu. La probabilité qu’une cellule rouge devienne verte, ou l’inverse,
dépend de la concentration locale en molécules R et V (rétroaction de la structure globale sur
le niveau local). De plus, chaque cellule se nourrit de molécules R ou V. C’est le côté
contraint (ou sélectif) du modèle. Si la cellule ne peut pas se nourrir, elle risque de mourir. Si,
la cellule survit, elle peut se diviser. Lors de la division, la cellule ‘‘sœur’’ va occuper une
case adjacente de la grille tirée au hasard parmi les cases libres.
Dans la situation où la probabilité pour qu’une cellule reste rouge est d’autant plus grande que
la concentration en molécules rouges est grande là où elle se trouve, ces cellules rouges
mangeant les molécules V, et réciproquement pour une cellule verte, nous avons observé
l’apparition de structures constituées de deux couches cellulaires rouges et vertes accolées
(voir figure). Ce type de structure en feuillets est très importante au cours de l’embryogenèse.
Contrairement à l’intuition commune, le hasard n’a pas d’effets désorganisateurs dans ce
système. Au contraire, il augmente la viabilité et la plasticité. Une analyse fine a démontré
que cet « organisme virtuel » est extrêmement dynamique ce qui le rend apte à s’adapter et à
construire de grandes structures de manière reproductible, comme c’est le cas des organismes
réels.
Tous ces résultats suggèrent que le vivant a intérêt à choisir une stratégie aléatoire. Ils
présentent des arguments scientifiquement tangibles en faveur d’un modèle de hasard-
sélection appliqué au comportement cellulaire. Bien évidemment, il s’agit d’un travail très
préliminaire qui demande la mise au point d’un programme de recherche à part entière tant
expérimental qu’à l’aide des outils de simulation informatique.
1
/
2
100%