memoire de magister theme - Université d`Oran 1 Ahmed Ben Bella

République Algérienne Démocratique et Populaire
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université d’Oran
Faculté des Sciences
Département d’Informatique
MEMOIRE DE MAGISTER
Option : Informatique et Automatique
THEME :
E
XTRACTION
A
UTOMATIQUE DES
C
ONNAISSANCES A PARTIR DES
D
ONNEES
:
E
TUDE DE CAS DES DONNEES ORGANISEES
Présenté par : Mr BENAMINA Mohamed
Soutenu devant les membres du jury :
Mr B. BELDJILALI Professeur à l’Université d’Oran
Président
Mr D. BENHAMAMOUCHE Professeur à l’Université d’Oran
Examinateur
Mr K. BOUAMRANE Maître de conférences à l’Université d’Oran
Examinateur
Mr B. YAGOUBI Maître de conférences à l’Université d’Oran
Examinateur
Mr B. ATMANI Maître de conférences à l’Université d’Oran
Rapporteur
2007-2008

Introduction générale
1
Introduction Générale
The most incomprehensible thing about the world
is that it is at all comprehensible.
—Albert Einstein
Donner un sens à toute l’information contenue dans les bases de données (BD) est
un défi pour les chercheurs en informatique. La notion de découverte de
connaissances dans les bases de données est en général appréciée sous sa forme
“brutale” de fouille des données (FD, “Data Mining”). L’extraction de
connaissances à partir des données (ECD) a été définie comme l’extraction, à
partir des données, d’une information implicite, inconnue auparavant et
potentiellement utile [Fra 92]. Ceci signifie que ce domaine présente un intérêt
commun pour les chercheurs en apprentissage symbolique automatique (ASA),
automatisation de la découverte, statistiques, BD, acquisition de connaissances,
visualisation des données et systèmes experts.
On s’intéresse à la découverte de connaissances, on a donc besoin de techniques
d’exploration des données (de façon supervisée ou non) pour trouver des formes
“intéressantes” qui aident à expliciter une information auparavant cachée dans les
données. Les problèmes fondamentaux de la découverte de connaissances sont
donc : la représentation des connaissances, la sélection des attributs, la prise en
compte des données manquantes, bruitées et rares, la découverte de formes
“intéressantes”, “utiles” ou encore “surprenantes”. Ce processus n’est pas une
exploitation pure et simple, mais un processus compliqué [Bra 94]. On peut dire
que l’extraction de connaissances se fait en trois étapes principales. La première
est la segmentation des données (appelée aussi fenêtrage) pour sélectionner le
meilleur endroit où travailler dans la base. La deuxième étape est le nettoyage des
données durant lequel les données brutes sont mises sous une forme telle qu’on
puisse les analyser par des algorithmes statistiques ou issus de l’ASA. Cette
étape, quoique peu spectaculaire, est cruciale car elle souligne les traits
importants et élimine les traits secondaires. La troisième étape correspond à
l’interprétation des restes éparpillés découverts sur le site, c’est-à-dire à
l’unification de chacune des découvertes en un modèle cohérent. Disposer de
plusieurs modèles et choisir le mieux adapté aux données est aussi une étape
capitale. Le but de toutes les techniques existantes, ASA, Statistiques, Analyse de
Données (AD) et Réseaux Neuronaux (RN), mais aussi Systèmes de gestion des
BD (SGBD) et Systèmes de Visualisation est évidemment d’aider l’utilisateur à
utiliser ses données et ainsi tous peuvent prétendre qu’ils essayent depuis toujours
de résoudre les mêmes problèmes que l’ECD. Ils ont cependant été construits par
des communautés scientifiques très différentes, pour de très bonnes raisons. Avec
des préoccupations si différentes, il est tout à fait normal que les six domaines
scientifiques ci-dessus aient évolué dans des directions différentes. La première
difficulté de l’ECD est qu’elle exige une utilisation coordonnée de ces six
domaines scientifiques. On ne peut pas sérieusement prétendre qu’il faut
“simplement les assembler”. En particulier, ils ont choisi des représentations des
connaissances qui rendent compte de différents aspects de la réalité et qui sont
presque impossibles à réconcilier sans perdre ce qui fait la force du domaine
concerné.

Introduction générale
2
Définition :
L’ECD est un nouveau domaine de recherche. Par rapport à ses domaines parents,
elle est caractérisée par le fait qu’elle extrait des connaissances pertinentes
(“intéressantes” dans la terminologie US) et intelligibles à partir des données en
utilisant (aussi) des techniques inductives et où toutes données fournies par
l’utilisateur peuvent être fouillées. Son but est de mesurer la pertinence et
l’intelligibilité de la connaissance engendrée. L’état actuel de l’art n’illustre
encore qu’incomplètement cette définition puisqu’il y a très peu de systèmes
d’ECD existants et capables de mesurer la pertinence et l’intelligibilité. Le succès
même des logiciels existants montre que l’espoir d’améliorer l’ECD selon ces
directions n’est pas du tout chimérique.
Notre définition utilise trois termes eux-mêmes mal définis : connaissance,
intelligible et pertinent. Essayons de montrer comment ils sont définis en ECD.
La connaissance en ECD peut alors être définie comme une phrase d’un langage
formel permettant de modifier le comportement d’un agent (de préférence : de
l’améliorer). Une connaissance pertinente est telle que :
1- sa valeur de vérité est assez élevée
2- on sait comment l’utiliser
3- elle s’accorde bien aux buts de l’utilisateur.
Il faut bien avouer que la pertinence est encore presque complètement définie par
l’utilisateur, dans l’état actuel de l’art de l’ECD, sauf dans les travaux précurseurs
de Piatetsky-Shapiro [Pia 94] et de Bhandari [Bha 92]. Enfin, une connaissance
est dite intelligible quand elle est exprimée dans le langage de l’utilisateur et avec
la sémantique de l’utilisateur. Nous n’incluons pas dans notre définition, au
contraire de [Fay 96], le fait que la connaissance découverte devrait être implicite
dans les données et auparavant inconnue. Cela limite les buts de l’utilisateur qui
pourrait, par exemple, être heureux (ce serait une forme spéciale d’intelligibilité)
de retrouver quelque chose qu’il connaissait déjà.
Enfin, l’usage des nouvelles connaissances découvertes peut être une contribution
dans la réalisation des Systèmes Experts. En effet, le coût de réalisation d’un
Système Expert, en utilisant des techniques traditionnelles d’acquisition des
connaissances, à partir d’experts humains, constitue un obstacle à son utilisation
et à sa large diffusion. Une solution à ce problème est de concevoir des
programmes informatiques capables d’apprendre et de découvrir leurs propres
connaissances, et ce, partant de cas pratiques (exemples). Dans ce type de
système, l’expertise n’est plus fournie par l’expert humain, mais doit être
construite à partir de données dont on dispose sur le domaine.
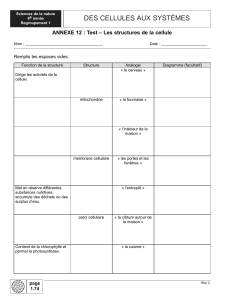
Les Phases De L’ECD :
Le Processus Cross Industry Standard Process for Data Mining, ou CRISP-DM, était
un projet pour développer des outils neutres et d’industrie pour modéliser l’ECD [Cri
06]. Le concept de CRISP-DM a été conçu par DaimlerChrysler (puis Daimler-Benz),
SPSS (puis ISL), et NCR, en 1996 et a évolué sur plusieurs années, construit autour
de l’expérience de différentes compagnies industrielles, des engagements de
consultants, ainsi que des exigences d'utilisateurs spécifiques. Bien que la plupart des
ECD aient été, traditionnellement, à base d’efforts personnels de conception et
d'implémentation de spécialistes hautement qualifiés, ils ont, pourtant, souffert
d’épuisement de budget et de dépassement de délai de réalisation. CRISP-DM a eu

Introduction générale
3
comme but de murir plus rapidement et à des prix moindres les ECD. Puisque les
ECD ayant suivi des processus ad hoc ont tendance à être moins fiables et moins
flexibles, en standardisant les phases de l’ECD par intégration et par validation des
meilleures pratiques des experts de divers secteurs industriels, ces ECD pourraient
devenir fiables et flexibles.
On devrait noter que le succès d’un ECD dépend essentiellement des données
disponibles et de leur qualité. Dans l'ensemble, mettre le plus grand accent sur les
conditions actuelles et futures d'analyse de données pendant la conception d’un ECD
peut considérablement réduire l'effort futur de data mining. La modélisation et
l’organisation pauvres de données posent de sérieux défis aux ECDs.
Tel qu’illustré par la figure 1, CRISP-DM [Cri 06] présente un ECD, durant un cycle,
avec six phases distinctes. Il illustre les taches associées à chaque phase ainsi que les
relations entre les phases et les taches. Comme la plupart des standards, CRISP-DM
ne prétend pas couvrir chaque relation entre les phases et les taches, puisque ceci
dépend des objectifs du projet, de l’expérience et des besoins de l'utilisateur, et des
particularités des données. Il est fortement probable que le mouvement entre les
différentes phases prédéfinies puisse être exigé. Les flèches sur la figure indiquent les
relations les plus communes et les plus importantes entre les phases.
L’ECD [Hor 07] lui-même forme typiquement un continuum comme indiqué par le
cycle externe de la figure 1. Une fois qu'une solution a été déployée, de nouvelles
questions émergent, rapportant ainsi, grâce à leur solution, plus d’exploitation et de
raffinement de la solution existante, améliorant ainsi la qualité du résultat. Avec
chaque itération dans l’ECD, la qualification et l'expérience aident à améliorer les
efforts conséquents.
Figure 1. Le processus CRISP-DM avec ses six phases
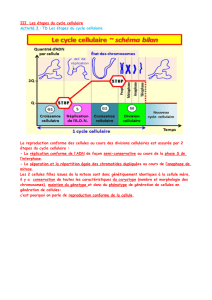
L’integration de l’ECD au sein d’un système conduit à la figure 2
[Hor 07]
.
Les phases principales d’un ECD sont : la préparation des données (Data
Understanding), le prétraitement (Data Preparation), la fouille de données
(Modeling) proprement dite (étape centrale de l’ECD) et enfin la validation
(Evaluation) des modèles ainsi élaborés.
Business
Understanding
Data
Understanding
Data
Preparation
Modeling
Evaluation
Deployment
Data

Introduction générale
4
Figure 2.Architecture software intégrant le Data Mining
Les étapes de préparation des données portent sur l’accès aux données en vue de
construire des tables bidimensionnelles. En fonction du type des données (e.g.
numérique, symbolique), des méthodes de pré-traitements mettent en forme les
données, les nettoient, traitent les données manquantes et sélectionnent les
attributs ou les individus lorsque ceux-ci sont trop nombreux : choix des attributs
les plus informatifs dans le premier cas, échantillonnage dans le second cas. Cette
phase est importante puisque c’est elle qui va conditionner la qualité des modèles
établis lors de la fouille de données. En effet, ces choix ont pour objectif de faire
émerger l’information contenue au sein de cette masse de données.
Le prétraitement, et en particulier la phase de sélection des données est une phase
cruciale [Atm 07a]. En effet, c’est du choix des descripteurs et de la connaissance
précise de la population que va dépendre la mise au point des modèles de
prédiction. L’information nécessaire à la construction d’un bon modèle de
prédiction peut être disponible dans les données, mais un choix inapproprié de
variables ou d’échantillons d’apprentissage peut faire échouer l’opération. Cette
étape de mise en forme dépend fortement de la nature du domaine traité et a pour
principe de sélectionner des descripteurs, ou encore des variables exogènes. Cette
représentation est généralement nécessaire pour pouvoir utiliser les méthodes de
fouille de données opérant sur des tables bidimensionnelles.
La fouille de données fait appel principalement aux disciplines de l’intelligence
artificielle, de la statistique et de l’analyse de données. Elle s’effectue
généralement sur des tables bidimensionnelles, et se décompose essentiellement
en trois grandes familles de méthodes : descriptives, de structuration, et
explicatives (cf. chapitre 1, §1.3.3).
L’objectif de la mise en œuvre des techniques de fouille de données est d’aboutir
à des connaissances opérationnelles. Ces connaissances sont exprimées sous
forme de modèles plus ou moins complexes : une série de coefficients pour un
modèle de prévision numérique, des règles logiques du type Si Condition alors
Operational
Data Stores
Data
Warehouse
A
p
plications
Web
Call
Center
Mobile
Management
Data Mart
Application Server
Data Mining Tool
Data Mining Engine
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
1
/
96
100%