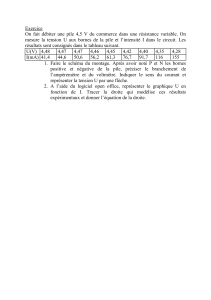
TP : Parallélisme de tâches - RunTime

TP : Parallélisme de tâches
PRCD PG 305
Olivier AUMAGE
http://runtime.bordeaux.inria.fr/oaumage/
L’objectif de ce TP est d’étudier la parallélisation par threads puis par tâches
d’un algorithme « simple ».
L’algorithme quicksort est un algorithme de tri rapide. Nous proposons ici de le pa-
ralléliser à l’aide de threads.
1 L’algorithme quicksort
Nous commençons ici par écrire une version séquentielle de l’algorithme qui servira
de référence pour la suite du TP.
– Écrire en C un algorithme quicksort standard (récursif) qui travaille sur un tableau
d’entiers (int) de taille paramétrable, et généré aléatoirement.
–Vérifier que votre algorithme fonctionne correctement avant de passer à la suite !
– En faire un benchmark :
– Faire une boucle pour effectuer le quicksort sur des tableaux de taille croissante
(en progression géométrique).
– Mesurer les temps d’exécution de l’algorithme pour chaque taille de la progres-
sion géométrique.
– Tracer la courbe de temps en fonction de la taille à l’aide de gnuplot.
2 Parallélisation triviale de quicksort avec les PThreads
(POSIX threads)
Chaque niveau de récursion de l’algorithme donnant lieu à deux appels récursifs tra-
vaillant indépendamment sur deux sous-parties disjointes de la portion de tableau trai-
tée, ces appels récursifs se prêtent tout naturellement à une parallélisation par threads.
– Remplacer chaque appel récursif par une création de thread. Que faut-il protéger
par un mutex ? N’oubliez pas les pthread_join adéquats ! Vérifiez que le résul-
tat est toujours correct.
1

– Mesurer les performances et tracer les courbes. Conclusion?
3 Optimisations
– Jusqu’à quelle taille de données la parallélisation précédente fonctionne-t-elle ?
Pourquoi ? Que se passe-t-il alors?
– Nous allons borner le nombre de threads par deux méthodes et les comparer :
1. Modifiez votre programme pour ne créer un thread pour l’appel récursif que
pour les premiers niveaux de récursion (jusqu’à un niveau nréglable). Com-
bien de threads sont actifs simultanément en fonction de n? Quelles valeurs
de nvous semblent pertinentes ?
2. Modifier votre programme pour décider de créer un thread ou non selon le
nombre de threads actuellement en cours d’exécution, i.e. ne pas créer de
thread au-delà d’une certaine borne msur le nombre de threads actifs. Quelles
valeurs de mvous semblent pertinentes ?
– Évaluer et comparer le comportement de ces deux versions optimisées. Laquelle
équilibre le mieux la charge ? Laquelle est la plus efficace ? Pourquoi ?
– Pour obtenir un bon parallélisme, vous semble-t-il nécessaire de créer un thread
pour chacun des deux appels récursifs du quicksort ? Justifiez. Adaptez le code en
conséquence.
4 Gestion des tâches « à la main »
Nous allons dorénavant gérer le parallélisme à grain fin manuellement, en n’uti-
lisant les threads que pour enchainer des tâches de manière itérative sur chacun des
processeurs.
4.1 Mise au point
L’idée générale est de mettre en place une pile de travail, consitutée d’un empilement
de tâches. Il s’agit de la méthode habituelle de transformation d’un code récursif en
code itératif.
Dans cette pile de travail, chaque tâche est une description d’un travail à faire, tra-
vail qui serait effectué par un appel récursif à la fonction quicksort dans la version
récursive. Plutôt que de réaliser un appel récursif directement (version séquentielle ré-
cursive) ou de créer un thread (version récursive multi-thread), un appel récursif devient
un empilement d’une tâche sur la pile de travail.
Un thread de travail (le thread principal, dans un premier temps) est constitué d’une
boucle qui dépile une tâche, la traite, et continue jusqu’à ce que la file soit vide.
2

Pour l’instant, un seul thread exécute le travail, mais nous ne perdons pas de vue que
l’objectif est qu’à terme il y en ait plusieurs.
– Définir une structure de données struct job_s décrivant une tâche (les para-
mètres d’un appel récursif) à effectuer ainsi que les fonctions nécessaires pour
manipuler une pile d’élements struct job_s.
– Adapter votre quicksort pour remplacer les appels récursifs par un empilement de
tâche.
– Comment gère-t-on la dépendance entre les tâches ?
– Comment initialise-t-on la pile ? Comment détecte-t-on la fin du quicksort ?
4.2 Optimisation de la récursion terminale
Avant de passer à une version multiprocesseur, nous allons appliquer quelques op-
timisations de base :
– Chaque tâche génère la plupart du temps deux nouvelles tâches ; or la première
d’entre elles sera dépilée immédiatement. Est-il utile de l’empiler alors que l’on
sait qu’elle sera immédiatement dépilée ? Adapter le code en conséquence.
– Mesurer le temps d’exécution et évaluer le gain. Comparer avec la version sans op-
timisation, les versions récursives multi-thread, et la version séquentielle. Conclu-
sions ?
5 Passage au multi-thread
Il s’agit maintenant d’ajouter d’autres threads noyau dans le programme de façon à
observer (on l’espère !) une accélération sur une machine multi-processeur.
5.1 Pile de travail commune
– Ajouter un thread noyau (pthread) qui consomme des tâches sur la pile de travail.
– Comment gère-t-on les dépendances? La tâche prête à exécuter est-elle forcém-
ment celle en sommet de pile ?
– Mesurer et comparer les performances obtenues sur une machine mono-processeur
et en SMP. Essayez au moins avec 1, 2, et 4 threads. Conclusions ?
5.2 Une pile de travail par thread
La version précédente souffre d’un grave problème de contention pour l’accès à la
pile de travail unique. Ce problème sera d’autant plus grave qu’il y aura plus de threads
noyau. Une solution consiste en l’utilisation de piles locales.
– Modifiez la version précédente pour que chaque thread soit doté de sa propre pile
de travail locale.
3

– Ajouter le vol de travail : quand la pile locale d’un thread est vide, il va vérifier chez
les autres s’il y a encore du travail et en « vole » le cas échéant.
– Évaluer le gain de performance apporté par cette méthode.
6 Continuations
Il ne faut pas confondre la notion de pile de travail d’un thread utilisée ci-dessus,
qui est une liste de tâches à réaliser, avec la notion de pile processeur du thread, qui est
la zone mémoire où un thread stocke ses données locales et les variables locales des
fonctions qu’il exécute.
Or, lorsque un thread T exécute une tâche t1 qui elle-même génère une autre tâche t2,
si t1 doit attendre la fin de t2 pour réaliser un traitement, t1 consomme des ressources
mémoire dans la pile processeur du thread T car précisémment, t1 ne peut terminer tant
que t2 n’est pas terminée.
Dans le cas de l’algorithme quicksort, le problème ne se pose pas étant donné que la
tâche mère réalise l’intégralité de son traitement avant sa ou ses tâches filles. En revanche
pour un algorithme tel que le calcul naïf de la suite de Fibonacci, une tâche mère doit
attendre la fin de l’exécution de ses tâches filles pour calculer la somme de leur résultats.
Si de nombreuses tâches se retrouvent ainsi en attente, le volume de ressources mémoire
ainsi bloquées sur la pile processeur de T peut devenir considérable, et même induire
un débordement de celle-ci.
Pour éviter ce phénomène, on peut recourir au concept de continuation. Une conti-
nuation est une tâche qui se substitue à la tâche mère d’un couple de tâche mere/tâche
fille et qui sera exécutée après la fin de la (ou des) tâche(s) fille(s). La tâche mère ainsi de-
barassée de sa responsabilité peut libérer ses ressources allouées sur la pile processeur
sans attendre la fin de la tâche fille et retourner immédiatement.
Ce mécanisme est notamment disponible avec la bibliothèque de multithreading
“Intel Threading Building Blocks” (TBB). En vous inspirant de la description de ce mé-
canisme appelé Continuation Passing en TBB et décrit dans le document tutoriel de TBB
à la section 10, implémentez et testez ce mécanisme sur l’algorithme naïf de Fibonacci.
4
1
/
4
100%