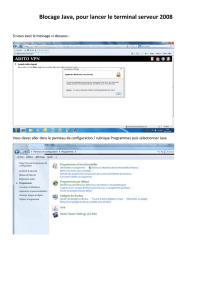
TP 2 - 10/10/2016

!"#

TP 2
Méthodologie Map/Reduce - programmation Hadoop plus avancée

$%&$
●'()*!++,%)%-+-%
●./)*)--0+%)1%)
+2+*)-*!%)%
●$+3-!-+-4+)*!++5!3!-!4+)
!)+-)-6
start-dfs.sh
start-yarn.sh
●!-+-4+)*!++5!3!-!4%++-0
++)6
start-hadoop

7)"-
●.-!4+%+2+*)-*-!)-
●8+-%)--)/)*21%)+--"-+(
)3+--0)*,"-%-2%+-
%--+21%)%)%3)-,20),2)
--)%
●'--+--!-,+,---))+29$8*
-")-!-)-
●.-!4%+%)*1+-%-2%!+-)-6
wget http://cours.tokidev.fr/bigdata/tp/graph_input.txt

:
7)"-
●.-!4%+%")"!-8;-
7;-<-%)",3,2+-)-0+-)
")*2%7-!4)-)4!
)-%,)
●.-!4%+++-")*-%-+-;-+)+--!
)*,1%)3%-+21%))-
.-!4)-%,))*)*-+)
)+"-+29$8
 6
7
8
9
10
6
7
8
9
10
1
/
10
100%