Classification bayésienne non supervisée de données

Délivré par UNIVERSITE MONTPELLIER 2
Préparée au sein de l'école doctorale I2S
Et de l'unité de recherche UMR MISTEA
Spécialité : Biostatistique
Classification bayésienne non
supervisée de données fonctionnelles
en présence de covariables
Soutenue le 18/12/2014 devant le jury composé de :
Examinateur
Damien JUERYPrésentée par :
M. Jean-Michel MARIN, Université Montpellier 2
RapporteurM. Nicolas CHOPIN, ENSAE
RapporteurM. Pierre DRUILHET, Université Blaise Pascal
ExaminateurM. Denys POMMERET, Université d'Aix-Marseille
Directeur de thèseM. Christophe ABRAHAM, Montpellier SupAgro
Co-encadrante de thèseMme Bénédicte FONTEZ, Montpellier SupAgro


A mon épouse Lucie et toute ma vie.
A mes parents Norbert et Geneviève.
A ma sœur Séverine.


Résumé
Un des objectifs les plus importants en classification non supervisée est d’extraire des groupes
de similarité depuis un jeu de données. Avec le développement actuel du phénotypage où les
données sont recueillies en temps continu, de plus en plus d’utilisateurs ont besoin d’outils ca-
pables de classer des courbes.
Le travail présenté dans cette thèse se fonde sur la statistique bayésienne. Plus précisément,
nous nous intéressons à la classification bayésienne non supervisée de données fonctionnelles.
Les lois a priori bayésiennes non paramétriques permettent la construction de modèles flexibles
et robustes.
Nous généralisons un modèle de classification (DPM), basé sur le processus de Dirichlet, au
cadre fonctionnel. Contrairement aux méthodes actuelles qui utilisent la dimension finie en pro-
jetant les courbes dans des bases de fonctions, ou en considérant les courbes aux temps d’obser-
vation, la méthode proposée considère les courbes complètes, en dimension infinie. La théorie
des espaces de Hilbert à noyau reproduisant (RKHS) nous permet de calculer, en dimension in-
finie, les densités de probabilité des courbes par rapport à une mesure gaussienne. De la même
façon, nous explicitons un calcul de loi a posteriori, sachant les courbes complètes et non seule-
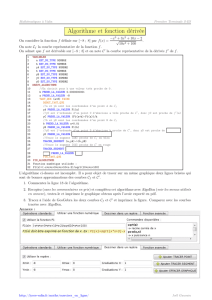
ment les valeurs discrétisées. Nous proposons un algorithme qui généralise l’algorithme "Gibbs
sampling with auxiliary parameters" de Neal (2000). L’implémentation numérique requiert le
calcul de produits scalaires, qui sont approchés à partir de méthodes numériques. Quelques ap-
plications sur données réelles et simulées sont également présentées, puis discutées.
En dernier lieu, l’ajout d’une hiérarchie supplémentaire à notre modèle nous permet de pou-
voir prendre en compte des covariables fonctionnelles. Nous verrons à cet effet qu’il est pos-
sible de définir plusieurs modèles. La méthode algorithmique proposée précédemment est ainsi
étendue à chacun de ces nouveaux modèles. Quelques applications sur données simulées sont
présentées.
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
1
/
124
100%