IMG - Bienvenue sur Catalogue des mémoires de projets de fin d

Mémoire de Projet de Fin d'Etudes
Sujet : Réalisation d’une interface Ethernet sur FPGA pour une
centrale d’acquisition basses températures rapide
Auteur : Fabien AUBERT
INSA de Strasbourg, Spécialité Génie Electrique
Tuteur entreprise : Daniel COMMUNAL
Tuteur INSA Strasbourg : Bertrand BOYER
Du 01/03/2011 au 29/07/2011
CEA GRENOBLE
17, rue des Martyrs
38054 Grenoble Cedex 9

PFE / Génie Electrique / Fabien AUBERT 2
REMERCIEMENTS
Avant de commencer ce rapport, je souhaite remercier Alain GIRARD, chef du SBT, de
m’avoir permis d’effectuer ce projet de fin d’études au Service des Basses Températures du
CEA Grenoble pendant cinq mois.
Je tiens à adresser mes plus vifs remerciements à mon maître de stage Daniel COMMUNAL,
pour m’avoir proposé un sujet aussi riche qu’intéressant, pour sa très grande disponibilité
ainsi que ses nombreux conseils.
Je remercie Patrick BONNAY, chef du groupe GEA, de s’être intéressé à mon travail et aux
problèmes auxquels j’étais confronté.
Je souhaite remercier :
- Christophe MARIETTE, pour ses conseils et remarques pertinentes.
- Anthony ATTARD et Guillaume FEGE, pour leur aide et explications sur la version actuelle
de la Centrale d'Acquisition ainsi que sur l'utilisation des logiciels Xilinx.
- Thierry JOURDAN, pour son aide et ses conseils sur tout ce qui touche au logiciel.
- Michèle MOUCOT, secrétaire du SBT, pour son implication dans toutes les démarches
administratives.
Je voulais également remercier l’ensemble du groupe GEA au sein duquel il règne une très
bonne ambiance.
Merci à Bertrand BOYER, tuteur enseignant de l'INSA, pour avoir suivi l’évolution de mon
projet de fin d’études.
Enfin, je remercie toutes les personnes qui se sont impliquées de près ou de loin dans le
déroulement de mon stage.

PFE / Génie Electrique / Fabien AUBERT 3
INTRODUCTION
J’ai effectué mon Projet de fin d’études au « Commissariat à l’Energie Atomique et aux
énergies alternatives » (CEA) de Grenoble dans le Groupe Electronique et Automatique
(GEA). Ce groupe figure au sein du Service des Basses Température (SBT) faisant partie de
l’Institut Nanoscience et Cryogénie (INAC).
Le Service des Basses Températures développe et utilise de l'instrumentation
spécifiquement adaptée à la cryogénie. Un projet de centrale d'acquisition pour les basses
températures (1 K à 300 K) est en cours de réalisation, une première partie concernant
l'acquisition et le traitement des mesures a été mise au point sur la base d'un composant
FPGA. Nous souhaitons maintenant intégrer la partie post-traitement et stockage des
données ainsi que la communication via le protocole Ethernet MODBUS TCP sur ce même
composant FPGA. Le but du stage est d'une part de synthétiser les composants réseau
nécessaires et d'autre part de développer le logiciel applicatif associé pour le processeur
embarqué dans ce FPGA.
La carte électronique de la centrale comporte 8 voies de mesure adaptées uniquement aux
capteurs à résistance. Le principe est de mesurer des tensions et des courants pour obtenir
une valeur de résistance qui est ensuite convertie en température. Dans l'état actuel des
choses, une carte processeur est couplée à plusieurs cartes de mesure. Elle se charge du
post-traitement des données, de leur stockage et de leur transfert via Ethernet.
Le but de mon stage est de développer une version mono-carte de ce système (8 voies
seulement). Cette autre version, dite « stand-alone » (autonome) est en quelque sorte une
version « allégée » qui comportera moins de capacités de traitement mais sera autonome et
moins chère. Elle vise à se passer de la carte réalisant le post-traitement des données et
l’interface Ethernet et de tout intégrer sur une seule et même carte, en se servant des
ressources non utilisées dans le FPGA. L’objectif est donc d'un côté, de récupérer les
mesures, les traiter (calculer les valeurs de résistance puis les convertir en température), les
stocker et d'un autre côté de les rendre disponibles sur le réseau via Ethernet. Un autre
aspect de mon projet est de répondre à certaines requêtes, permettre de modifier (à
distance) des paramètres du système sans avoir à reprogrammer le FPGA, transférer des
fichiers via TFTP, etc. Cet autre aspect n’était, à l’origine, pas prévu dans le sujet de mon
stage mais vu l’avancement, cette partie a aussi été traitée.
Mon travail consiste donc à réaliser une application comportant plusieurs tâches qui doivent
respecter des contraintes de temps réel (en particulier la tâche d’acquisition des mesures).
Dans ce rapport de nombreux termes techniques et acronymes sont utilisés dont une
définition est donnée dans le lexique, à la fin du mémoire.

PFE / Génie Electrique / Fabien AUBERT 4
RESUME
Réalisation d'une interface Ethernet sur FPGA pour une centrale
d'acquisition basses températures rapide
Le Service des Basses Températures du CEA de Grenoble développe et utilise de
l'instrumentation spécifiquement adaptée à la cryogénie. Un projet de centrale d'acquisition
pour les basses températures (1 K à 300 K) est en cours de réalisation, une première partie
concernant l'acquisition et le traitement des mesures a été mis au point sur la base d'un
composant FPGA.
L'objectif est maintenant d'intégrer la partie post-traitement et stockage des données ainsi
que la communication via le protocole Ethernet MODBUS/TCP/IP sur ce même composant
FPGA.
Le projet consiste d'une part à synthétiser les composants nécessaires et d'autre part à
développer le logiciel applicatif associé, pour le processeur embarqué dans ce FPGA. Il faut
pour cela réaliser une application comportant plusieurs tâches qui doivent respecter des
contraintes de temps réel (en particulier la tâche d’acquisition des mesures).
Development of an Ethernet interface on a FPGA for a fast low
temperatures data logger
Service of Low Temperatures of the CEA Grenoble develops and uses instrumentation
specifically tailored to cryogenics. A data logger for low temperatures (1 K to 300 K) is in
progress, a first part concerning the acquisition and processing steps has been developed
based on an FPGA.
The goal is now to integrate the part of the project concerning post-processing and data
storage as well as communication via the Ethernet protocol Modbus / TCP / IP on the same
FPGA.
The project consists in synthesizing the necessary components and developing the
application associated software, for the embedded processor in the FPGA. This requires an
application with multiple tasks that must meet real time constraints (especially the acquiring
measurements task).

PFE / Génie Electrique / Fabien AUBERT 5
SOMMAIRE
REMERCIEMENTS ....................................................................................................................... 2
INTRODUCTION .......................................................................................................................... 3
RESUME ...................................................................................................................................... 4
1 Présentation de l’entreprise .............................................................................................. 7
1.1 Historique .................................................................................................................... 7
1.2 Chiffres (2010) et activité ............................................................................................ 7
1.3 Le CEA de Grenoble ..................................................................................................... 8
1.4 Le service des basses températures (SBT) ................................................................... 9
2 Introduction du sujet ........................................................................................................ 11
2.1 La centrale d’acquisition de température ................................................................. 11
2.1.1 Contexte ............................................................................................................. 11
2.1.2 Principales spécifications de la CABTR ............................................................... 12
2.1.3 Fonctionnement et problématique .................................................................... 13
2.2 Principe de fonctionnement général ......................................................................... 15
2.2.1 Acquisition et mise en forme des signaux.......................................................... 15
2.2.2 Conversion des mesures de tension et courant ................................................. 16
2.2.3 Stockage et transfert des données .................................................................... 17
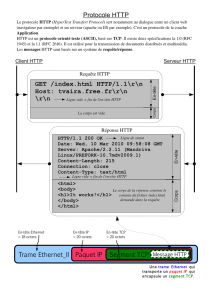
2.3 Protocoles de communication ................................................................................... 17
2.3.1 TCP/IP et OSI....................................................................................................... 17
2.3.2 Le protocole Modbus TCP .................................................................................. 19
3 Développement de la partie matérielle ........................................................................... 21
3.1 Réalisation d’une carte d’interface Ethernet pour le prototype ............................... 21
3.2 Environnement de travail .......................................................................................... 24
3.3 Mise en place d’un système multitâches temps réel ................................................ 25
3.3.1 Ordonnancement des tâches ............................................................................. 25
3.3.2 Accès aux données ............................................................................................. 26
4 Développement de la partie logicielle ............................................................................. 28
4.1 Architecture du système............................................................................................ 28
4.2 Initialisation ............................................................................................................... 30
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
1
/
52
100%