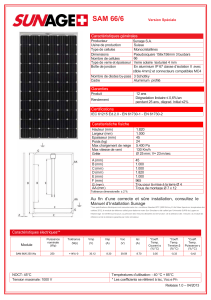
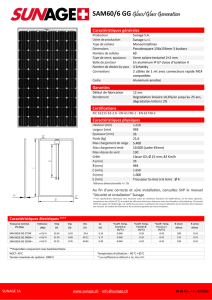
Système d`information décisionnel sur les interactions

Syst`eme d’information d´ecisionnel sur les interactions
environnement-sant´e : cas de la Fi`evre de la Vall´ee du
Rift au Ferlo (S´en´egal)
Fanta Bouba
To cite this version:
Fanta Bouba. Syst`eme d’information d´ecisionnel sur les interactions environnement-sant´e : cas
de la Fi`evre de la Vall´ee du Rift au Ferlo (S´en´egal). Bio-informatique [q-bio.QM]. Universit´e
Pierre et Marie Curie - Paris VI, 2015. Fran¸cais. <NNT : 2015PA066461>.<tel-01292576>
HAL Id: tel-01292576
https://tel.archives-ouvertes.fr/tel-01292576
Submitted on 31 Mar 2016
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-
entific research documents, whether they are pub-
lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destin´ee au d´epˆot et `a la diffusion de documents
scientifiques de niveau recherche, publi´es ou non,
´emanant des ´etablissements d’enseignement et de
recherche fran¸cais ou ´etrangers, des laboratoires
publics ou priv´es.

Université Pierre et Marie Curie
Université Cheikh Anta Diop de Dakar
Ecole Doctorale Informatique, Télécommunication et Electronique
Unité de Modélisation Mathématique et Informatique des Systèmes Complexes
Système d’information décisionnel sur les interactions
environnement-santé
Cas de la Fièvre de la Vallée du Rift au Ferlo (Sénégal)
Par Fanta BOUBA
Thèse de doctorat en Informatique
Dirigée par Christophe CAMBIER et Samba NDIAYE
Présentée et soutenue publiquement le 25 Septembre 2015
Devant le jury composé de :
Christophe Cambier Maitre de Conférences UPMC Directeur de Thèse Nord
Samba Ndiaye Maitre de Conférences UCAD Directeur de Thèse Sud
Maguelonne Teisseire Directrice de recherche IRSTEA Examinateur
Jacques André Ndione Directeur de recherche CSE Examinateur
Ousmane Sall Maitre de Conférence UT Examinateur
Jean-Daniel Zucker Directeur de recherche IRD Président
Mathieu Roche (nord) Chercheur CIRAD Rapporteur
Cheikh Talibouya Diop Maitre de conférences UGB Rapporteur

"Connaître profondément pour agir !"
SID sur les interactions environnement-santé ii

Dédicaces
A ma famille, je ne suis rien sans vous, je n’existe qu’à travers vous.
A ma grand-mère et mon père qui resteront à jamais mes modèles de générosité, de
pardon et de travail.
C’est l’histoire d’une fratrie de 5 filles et 3 garçons ... cette histoire a commencé en 1975
et cette histoire continue allègrement avec la grâce de DIEU.
iii

Remerciements
Je suis particulièrement reconnaissante envers Alassane BAH qui a été à l’origine de
ce travail. En effet, il n’a ménagé aucun effort pour me mettre en contact avec toute l’équipe
encadrante, pour me trouver un sujet assez proche de mes aspirations mais également
pour m’aider à bénéficier de ma bourse d’études.
Je remercie Jean-Daniel ZUCKER pour avoir bien voulu présider ce jury mais surtout
pour ces remarques, lors de mon évaluation à mi-parcours, qui m’ont permis de mieux
m’approprier mon travail de recherche.
J’exprime également mes remerciements aux rapporteurs de cette thèse, Cheikh Tali-
bouya DIOP et Mathieu ROCHE, pour le temps accordé à lire et à commenter ce document.
J’espère pouvoir mettre à profit leurs corrections et remarques en vue de m’améliorer dans
mes prochains travaux de recherche.
Je remercie Ousmane SALL qui a accepté de faire partie de ce jury. Merci pour sa
réactivité malgré les délais très serrés.
Je tiens à remercier mon directeur de thèse Christophe CAMBIER qui a tenu durement
la laisse durant ces dernières années malgré les conditions de ma thèse qui ne correspon-
daient pas toujours à sa vision du doctorant.
Mes remerciements s’adressent également à mon directeur de thèse Samba NDIAYE
pour la confiance accordée malgré les nombreuses périodes d’instabilité. Merci d’avoir su-
pervisé ce travail.
Un merci particulier à Jacque-André NDIONE qui a tenu à m’accompagner aussi bien
dans mes activités de recherche que dans ma vie sociale. Il a toujours pris son temps pour
me mettre en rapport avec les experts métiers, pour me donner des cours à la fois sur la
maladie de la FVR et les facteurs environnemenatux. Il a veillé régulièrement à ce que je
sois dans les meilleurs conditions morales en particulier durant les moments de doute.
Un grand merci à Maguelonne TEISSEIRE qui a été la carte mère de cette thèse. Elle
a mis à ma disposition son environnement de travail, son équipe mais également toute
son expertise pour m’accompagner aussi bien dans les concepts théoriques que dans la
mise en oeuvre pratique. Merci de vous être autant investie et m’avoir soutenue pendant
les périodes difficiles.
Merci également à tous les experts métiers, qui ont bien voulu nous recevoir pour des
entretiens, pour le recueil de données mais aussi pour la restitution de certains résultats.
Je remercie vivement toute l’équipe TETIS et particulièrement Lilia COUNIENC, Mickael
FABREGUE, Guilhem MOLLA, Hugo ALATRISTA SALAS pour leur sympathie et leur pré-
cieuse aide.
iv
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
1
/
117
100%