SI1-C02.T CPU

SI1-C02.T CPU.doc N2 - SIO-03
Francois Kieffer 18/09/2015 page 12/12
9 Sources et références
Ouvrages papier :
Technologies des ordinateurs et des réseaux, PA Goupille ; Dunod
Composition des ordinateurs, A Tannenbaum ; Dunod
Revues informatiques : octobre à novembre 2008
PCAssemblage et Hardware, Compétences micro, PC Expert
Sites web :
Constructeurs
http://www.intel.fr/content/www/fr/fr/processors/core/CoreTechnicalResources.html
http://ark.intel.com/
http://www.amd.com/us/products/desktop/processors/pages/desktop-processors.aspx
http://www.research.ibm.com/journal/rd/475/brooks.html
Ecoles
http://www.mines.inpl-nancy.fr/~tisseran/cours/architectures/
Journaux
http://techreport.com/
http://www.xbitlabs.com/articles/cpu/display/core2duo-preview_6.html
http://www.hexus.net/content/item.php?item=256&redirect=yes
http://www.hardware.fr/html/cat/2/
http://www.hardware.fr/articles/863-1/intel-core-i7-3770k-i5-3570k-ivy-bridge-22nm-test.html
http://www.presence-pc.com/actualite/AMD-Phenom-28343/
http://www.hardware.fr/articles/833-1/architecture-amd-bulldozer.html
http://www.hardware.fr/news/12122/amd-detaille-roadmap-2012-2013.html
Autres
http://www.computerhistory.org/microprocessors/index.shtml
http://www.commencamarche.net
http://chip-architect.com/
http://arstechnica.com/hardware/news/2006/04/core.ars/
http://www.ginjfo.com/actualites/composants/processeurs/ivy-bridge-et-haswell-des-puces-core-aux-tdp-de-10-
watts-maximum-des-2013-20120912

SI1-C02.T CPU.doc N2 - SIO-03
Francois Kieffer 18/09/2015 page 11/12
8 Synthèse des architectures modernes
Marques
Celeron = entrée de gamme ; Xeon = serveurs ; Atom : matéreil mobile sauf Core M pour ultrabooks
Architectures multicœur Intel
Année Nom Archi Sous
architectures
Nom
Core
nbCore/
thread
Gravure Caches Bande
Passante
(Go/s)
socket
2006 Merom Core 1 65nm L4=4Mo 6,4 LGA775
2007 Penryn Core2 1 45nm L2=6 à
12Mo
12,8 LGA775
2008 Nehalem
Atom
Bloomfield,
Lynnfield,
Clarsfield
Core
i, I7 2/1 45nm L3, 8Mo
(4*2Mo) 25 LGA1366
2009 Westmere Gulftown,
Clarckdale,
Arrandale
I7, i5,
i3
2/2 32nm Nc LGA2011,
LGA1155
2010/12 Sandy bridge Ivy Bridge 2-4-6-8/2 32->22nm L2=512Ko,
L3=16Mo Nc LGA1155
2013/2014 Haswell 2-8/2 22->16nm ?
2015/16 Skylake 16->14nm
Taille i7 : 13*18,9 mm ; Sources : PC Expert n°191 Novembre 2008 ; *www.wikipedia.fr
Architectures AMD, AMD64 Core
Année Nom ,
architecture
Code
Cœur Gravure Cache (Mo) Intérêts Socket (support)
2006 K8,
Brisbane, Windsor, SledgeHammer
2 65 L1=64Ko/c,
L2=512Ko/c,
L3=2Mo
contrôleur DDR2, bus
externe "Hyper
transport".
2007 K10,
Barcelona
(opteron)
Phenom quad-core, triple-core,
Athlon (anc. Dual-core)
Sempron
2-4 65 L1=64Ko/c,
L2=512Ko/c,
L3=6Mo
(2*3Mo)
2008 K10,
Shanghaï
Phenom / correctif B3 (TLB) Phenom
xx50
Athlon, Sempron
4 32-40nm F+, AM2+, AM3
2011 Bobcat L1=32Ko,
L2=512Ko
2012 FX
Bulldozer,
Trinity, Brazos, Hondo
Vishera (Core Piledriver)
4 à 8 28nm L3=8Mo AM2+, AM3
2013 FX,
Kaveri, Kabini, Temash
StreamRoller, Jaguar cores
2 à 4 contrôleur DDR3 Dual
channel, bus externe
I/O "Hyper transport"
*4 canaux
AM3+
Sources : www.presence-pc.com, www.chip-architect.com ; la visiblité des générations est moins
bonnes chez AMD

SI1-C02.T CPU.doc N2 - SIO-03
Francois Kieffer 18/09/2015 page 10/12
Path interconnect, AMD possède l'équivalent),
- L3 intégré, L4 parfois soudé sur la CM, la capacité des caches augmente régulièrement
- Hyperthreading : chaque cœur est capable de traiter 2 instructions élémentaires (processus
(linux)=thread (Intel/microsoft))
- Modes turbo : extinction plus ou moins profonde des cœurs non utilisés, Noter que certains
journaux info font état d'un gain non significatif dans le mode turbo, voire des pertes de perf
(PC Expert),
- partage des unités de calcul entre le cœurs = trubo intelligent (=? Overclocking automatique)
(AMD Cluster Multi-threading),
- Bus interne entre les cœurs,
- Intégration de contrôleurs graphiques sur le Die : 1 ou 2 lignes PCI-Xpress *16
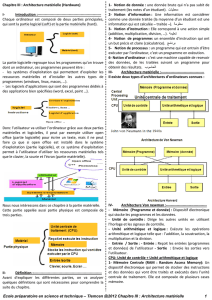
7 Conclusion : critères de choix

SI1-C02.T CPU.doc N2 - SIO-03
Francois Kieffer 18/09/2015 page 9/12
5 Améliorations logiques
Réordonnancement des instructions (ooo)
Exemple de réordonnancement des types d'instruction. Soit le cœur de processeur suivant:
Les traitements (ALU), instructions (SSE) et calcule (FPU) qui peuvent de dérouler simultanément sont
de même couleur :
Original Donnera ooo
ALU1 ALU1
ALU2 FPU1
FPU1 SSE1
SSE1 ALU2
ALU3 SSE2
SSE2 FPU2
SSE3 ALU3
FPU2 SSE3
FPU3 FPU3
5 cycles 3 cycles
6 Architecture multicœur, la multiplication des traitements parallèles
6.1.1 Historique
Etapes importantes de la guerre Intel/AMD
2005 Intel Pentium D : 2 caches L2, partage via FSB, AMD Stagne avec le K6
2006 Les premiers multi cœur, RAM DDR1.
Intel Core2 (monocore) puis Core2 duo, L2 partagée sans passer par le FSB
AMD K8 est meilleur
2007 RAM DDR2
Intel core2 Quad, 2caches L2, pas de L3 (erreur du Pent.D)
AMD K10 Dual Core, Phenom quadri cœur natif, L3 partagé par couple de cœur
2008++ Novembre : Intel contre-attaque : ajout d'unités d'échange supplémentaires : architectures Nehalem,
Lynnfield ou ClarsField, Westmere (Gulftown, Clarckdale et Arrandale) puis Sandy Bridge (Ivy Bridge)
Le FSB disparaît, le processeur intègre différents dispositifs de communication :
- Contrôleur mémoire, DMA (le retour) avec mémoire DDR2 puis DDR3 multi canal (intel : Quick
Port 0
Port 1
Port 2
P
ort 3
ALU
FPU
SSE
Store

SI1-C02.T CPU.doc N2 - SIO-03
Francois Kieffer 18/09/2015 page 8/12
4 Les améliorations matérielles réelles
CISC, RISC et SSE : jeux d'instructions câblées
CISC (
angl. Complex instruction set computer
)
RISC (
angl. Reduced instruction set computer
)
En 2008, il existe les jeux :
- MMX (multimédia, 08/01/1997, 57 instr.), Versions Intel, AMD et Cyrix
- 3DNow! (1997, 21 instr.), v1 puis 2
- SSE (1999, P3, 70 instr.) apparition d'instructions spécifiques pour FPU,
- SSE2 (2000, P4),
- SSE3 (2004/2005, 13 instr.),
- SSE4 (27/09/06, 54 instr., sous versions 1, 2, a), disparition des instructions MMX.
- SSE5 (10/2011, 170 instr.), différentes versions selon marque (AMD/Intel)
Exemple d'instructions
ADD X86 Addition
Move X86 Déplacement d'une "donnée" d'un "registre" à un autre.
ADDSS SSE Addition de nombres scalaires
MONITOR SSE2 Contrôle et optimisation du Multi-threading
ROUNDPS SSE4 Arrondi sur nombre en virgule flottante
COMPD SSE5 Compare Vector Double-Precision Floating-Point
Pipeline (à remplir)
ICI, découpage exemple d'une instruction en plusieurs instructions plus petites :
- instruction fetch, chargement de l'instruction dans le processeur (3 cycles pour l'exécution de
la lecture de la mémoire),
- instruction decode, décodage et conversion de l'instruction,
- execute, éxecution,
- memory access, lecture en mémoire,
- write back, écriture des résultats en mémoire (trois cycles pour l'exécution de l'écriture).
Rappel : on utilise 3 cycles pour l'exécution de l'échange en mémoire :
N° Instr Cycles
1 2 3 4 5 6 7 8 9 10 11 12
1 R1=mem[R0]
2 R3=R1+R2
3 R4=R4+1
4 R6=R5-6
 6
7
8
9
10
11
12
6
7
8
9
10
11
12
1
/
12
100%