par Apprentissage Symbolique Automatique

REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE
MINISTERE DE L’ENSEIGNEMENT SUPERIEUR
ET DE LA RECHERCHE SCIENTIFIQUE
UNIVERSITE D’ORAN ES-SENIA
FACULTE DES SCIENCES
DEPARTEMENT D’INFORMATIQUE
MEMOIRE
Présenté par
Melle Chérifa BOUDIA
Pour obtenir
LE DIPLOME DE MAGISTER
Spécialité Informatique
Option : Informatique et Automatique
Intitulé :
Soutenu le : à la salle de conférences de la faculté des sciences
Devant les membres du jury:
M. M. K. RAHMOUNI Professeur, Université d’Oran, ES-Sénia, Algérie
(Président)
M. A. BENYETTOU Professeur à l’USTO Mohamed Boudiaf, Oran, Algérie
(Examinateur)
M. A. LEHIRECHE Maître de Conférence, Université de Sidi-bel-abbes, Algérie
(Examinateur)
M. K. BOUAMRANE Docteur, Université d’Oran, ES-Sénia, Algérie
(Examinateur)
M. B. BELDJILALI Professeur, Université d’Oran, ES-Sénia, Algérie
(Rapporteur)
M. B. ATMANI Chargé de cours, Université d’Oran, ES-Sénia, Algérie
(Rapporteur)
Étude et mise en pratique d’une démarche
de modélisation (UML)
par Apprentissage Symbolique Automatique

2

Lécriture dune telle page nest pas une tâche aisée. Bien sûr, des noms viennent
immédiatement à lesprit; mais combien danonymes ou doubliés ont, indirectement,
contribué à cette thèse ? Difficile à dire, dautant plus quen la matière, la subjectivité est
reine. Que ceux et celles que je nai pas nommés reçoivent lexpression de toutes mes
pensées.
Tout dabord, je remercie le grand Dieu qui ma inspiré le courage et la patience
pour terminer ce travail. Bien évidemment, une mention spéciale revient à M. Bouziane
Beldjilali et M. Baghdad Atmani de luniversité dOran, davoir accepté dencadrer cette
thèse et mavoir accueilli au sein de léquipe, ils mont apporté bien plus que la compétence
scientifique nécessaire pour obtenir ce magister, leur disponibilité, leur écoute, leurs
conseils avisés et leur grande humanité font deux des personnes que jai en profonde
estime.
Je tiens aussi à remercier chaleureusement les examinateurs de ce travail, M. A.
BENYETTOU de l’USTO_MB, Oran, M. A. LEHIRECHE de luniversité de SBA, et M. K.
BOUAMRANE de luniversité dOran, qui ont accepté de se plonger dans cet écrit malgré
leur emploi du temps assurément chargé. La pertinence de leurs questions et la qualité de
leurs rapports mhonorent sincèrement.
Je remercie également M. M. K. RAHMOUNI, qui ma fait le plaisir daccepter de
présider le jury.
Je remercie les doctorants, les enseignants, les post-graduants et tous les employeurs
du département depuis le directeur aux simples employeurs, qui ont également contribué
à ce travail, par leur simple présence et lambiance excellente quils ont su créer.
Mes amis, sont pour beaucoup dans lachèvement de ce travail de longue haleine,
Mme H. Dahmani, Mme Z. Benhadjla et Mme S. Saichi. Je les remercie pour des jours et des
jours découte, des aventures inoubliables. Je pense à Tahia Adnane, ma vieille amie pour
nos nombreux rencontres au cybercafé et discussions multilingues, son écoute et son sens
de lhumour infini que Dieu te protège.
Et bien sûr, mes galantes salutations vont à ma famille, qui a toujours eu confiance
en moi, et ma soutenu dans les moments difficiles : mon père, Kada Boudia, ma mère,
Nedjar Fatiha, ainsi que ma sur Saliha, mes frères, Mohamed, Yacine et Adel. Merci
être restés unis dans toute cette aventure.
Merci à toutes et à tous…

4
Table des matières.............................................................................................................................1
Introduction générale........................................................................................................................4
1Introduction......................................................................................Erreur ! Signet non défini.
2Positionnement...............................................................................Erreur ! Signet non défini.
2.1 Présentation générale..........................................................Erreur ! Signet non défini.
2.2 Objectifs.....................................................................................Erreur ! Signet non défini.
3Travaux connexes..........................................................................Erreur ! Signet non défini.
3.1 Apprentissage Automatique..............................................Erreur ! Signet non défini.
3.2 UML ..............................................................................................Erreur ! Signet non défini.
4Conclusion.........................................................................................Erreur ! Signet non défini.
1Introduction.................................................................................................................................21
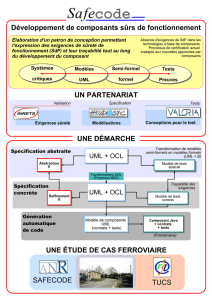
2UML : Développement orienté objet................................................................................21
2.1 Concepts de modélisation UML..................................................................................21
2.2 Modèles et notations en UML......................................................................................22
2.2.1 Diagrammes UML.....................................................................................................22
2.2.2 Vues de modélisation.............................................................................................24
2.2.3 Méta-modèle...............................................................................................................25
2.3 Processus de développement itératif......................................................................25
3Démarches...................................................................................................................................26
3.1 Cas d’utilisation.................................................................................................................26
3.2 Architecture logicielle......................................................................................................27
3.3 Cycle de vie itératif et incrémental..........................................................................27
4Sélection d’une méthode.......................................................................................................28
5Critères d’évaluation ...............................................................................................................28
5.1 Qualité de l’architecture logicielle.............................................................................29
5.1.1 Réutilisabilité..............................................................................................................29
5.1.2 Modifiabilité.................................................................................................................29
5.1.3 Traçabilité ....................................................................................................................29
5.2 Qualité du processus de développement..............................................................29
5.2.1 Pouvoir de vérification...........................................................................................30
5.2.2 Compréhensibilité ....................................................................................................30
5.2.3 Facilité d’utilisation..................................................................................................30
5.2.4 Pouvoir d’expression...............................................................................................30

5
6Aspects avancés en UML.......................................................................................................31
6.1 Aspects dynamiques........................................................................................................31
6.2 Histoires des utilisateurs et Programmation extrême.....................................32
6.3 UML et la description d’architectures logicielles ................................................33
6.4 UML : le chemin vers l’unification des processus..............................................34
7Le modèle UML obtenu est-il correct ?...........................................................................35
8Présentation d’OCL...................................................................................................................36
8.1 Le paquet UML-OCL.........................................................................................................36
8.2 Limitations et défauts d’OCL.......................................................................................37
8.3 Approches existantes : Méta-modèles UML et OCL intégrés.......................37
9Conclusion....................................................................................................................................38
1Introduction.................................................................................................................................40
2Apprentissage automatique.................................................................................................40
2.1 Apprentissage connexionniste....................................................................................41
2.2 Apprentissage symbolique ...........................................................................................42
2.2.1 Naissance de l'ASA et état de l'art...................................................................44
2.2.2 Les étapes du processus de l’ECD....................................................................46
2.2.2.1 Prétraitement des données.............................................................................46
2.2.2.2 Traitement des données...................................................................................51
2.2.2.3 Validation.................................................................................................................52
2.2.3 Arbre de décision......................................................................................................52
2.2.3.1 Mode de fonctionnement..................................................................................53
2.2.3.2 Les Systèmes fondés sur les Arbres de Décision..................................53
2.2.3.3 Finalités sur les Arbres de Décision.............................................................56
2.2.3.4 Avantages de linduction par graphes dinduction................................56
2.2.4 Les algorithmes génétiques.................................................................................57
2.2.4.1 Mode de fonctionnement..................................................................................58
2.2.4.2 Apprentissage des AG........................................................................................58
2.2.4.3 Finalités sur les algorithmes génétiques...................................................59
2.2.5 Raisonnement basé sur les cas : CBR............................................................59
2.2.5.1 Mode de fonctionnement..................................................................................59
2.2.5.2 Finalités sur le Raisonnement Fondé sur des Cas................................59
3Sipina..............................................................................................................................................60
3.1 Méthode SIPINA................................................................................................................60
3.1.1 Le choix du critère...................................................................................................60
3.1.2 Fixation du paramètre λ........................................................................................61
3.1.3 Fixation de la contrainte d'admissibilité........................................................62
3.1.4 Prise en compte des attributs continus .........................................................63
3.1.5 Éléments de construction de graphes d'induction....................................64
3.1.6 Passage de la partition Si à la partition Si+1 ................................................66
3.2 Algorithme SIPINA...........................................................................................................69
4Conclusion : quelle est la méthode choisie ?...............................................................70
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
1
/
126
100%