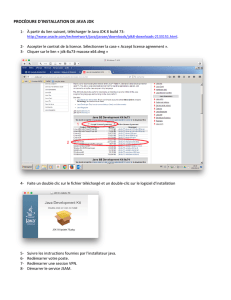
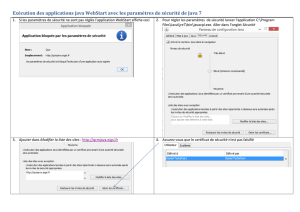
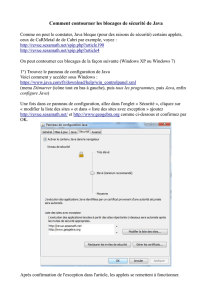
Revue et comparaison des différentes solutions

- 1 -
a
Revue et comparaison des différentes solutions
pour la programmation de pages Web dynamiques
Présenté par Giovanni Camponovo
en vue de l’obtention du
Diplôme postgrade en informatique et organisation
Année académique 2000-2001
Sous la direction du Prof. Benoît Garbinato
UNIVERSITÉ DE LAUSANNE
ÉCOLE DES HAUTES ÉTUDES COMMERCIALES
Institut d'informatique et organisation / BFSH1 / CH - 1015 Lausanne-Dorigny
Tél. (021) 692.34.00 / Fax (021) 692.34.05 / Internet e-mail : secretariat@inforge.unil.ch

- 2 -
0 Table des matières
0
Table des matières ............................................................................................................... 2
1
Sujet et objectifs du mémoire ............................................................................................. 3
2
Résumé.................................................................................................................................. 4
3
Introduction : les origines du Web..................................................................................... 6
3.1
Histoire de l’informatique [1-3] ...................................................................................................... 6
3.2
Histoire de l’Internet [4-5] .............................................................................................................. 7
3.3
Histoire du World Wide Web.......................................................................................................... 8
4
Le World Wide Web ......................................................................................................... 10
4.1
Architecture du World Wide Web................................................................................................. 11
4.2
URL (Uniform Resource Locator) ................................................................................................ 12
4.3
HTML (HyperText Markup Language) ........................................................................................ 14
4.4
HTTP (HyperText Transfer Protocol)........................................................................................... 16
4.5
L’évolution des besoins................................................................................................................. 18
5
Les pages statiques ............................................................................................................ 19
5.1
Limitations des pages HTML statiques......................................................................................... 21
5.1.1
Création préalable de chaque page............................................................................................ 21
5.1.2
Problèmes de mise à jour........................................................................................................... 22
5.1.3
Fusion du contenu et de la présentation .................................................................................... 22
5.1.4
Interactivité................................................................................................................................ 23
5.2
Avantages des pages HTML statiques .......................................................................................... 24
6
Les pages dynamiques....................................................................................................... 26
6.1
Solutions coté client ...................................................................................................................... 27
6.1.1
Applets Java .............................................................................................................................. 28
6.1.2
Active X .................................................................................................................................... 34
6.1.3
Javascript et VBscript................................................................................................................ 38
6.2
Solutions coté serveur ................................................................................................................... 43
6.2.1
CGI (Common Gateway Interface) ........................................................................................... 45
6.2.2
PHP (PHP Hypertext Preprocessor).......................................................................................... 48
6.2.3
ASP (Active Server Pages)........................................................................................................ 55
6.2.4
JSP (Java Server Pages) et Servlets Java................................................................................... 63
6.2.5
ColdFusion ................................................................................................................................ 69
7
Conclusions ........................................................................................................................ 73
8
Bibliographie...................................................................................................................... 83
8.1
Histoire de l’informatique et de l’Internet............................................ Erreur ! Signet non défini.
8.2
PHP................................................................................................................................................ 85
8.3
ASP................................................................................................................................................ 86
8.4
JSP................................................................................................................................................. 86
9
Annexes............................................................................................................................... 87
9.1
Annexe 1: Evolution de l‘ArpaNet / Internet – nombre de hôtes.................................................. 91
9.2
Annexe 1: Evolution du world wide Web..................................................................................... 92

- 3 -
1 Sujet et objectifs du mémoire
Ce travail de diplôme a pour objet l’exploration du domaine de la programmation des pages Web
dynamiques, dans le but de passer en revue et de comparer les principales solutions disponibles actuellement.
Ce travail n’a pas pour but d’effectuer une analyse exhaustive des toutes les solutions existantes, mais de
recenser un certain nombre de solutions représentatives en fonction de leurs caractéristiques.
Il doit satisfaire trois objectifs principaux:
• un objectif pédagogique qui consiste à définir qu’est-ce qu’une page Web dynamique et quel est son
intérêt;
• un objectif de recherche qui réside à analyser différentes solutions existantes pour la création des pages
dynamiques;
• un objectif pratique qui se concrétise dans la conception et la réalisation pratique d’un site utilisant des
pages dynamiques avec une des solutions étudiées.
Pour réaliser le premier objectif, il faut bien comprendre qu’est-ce que c’est une page Web dynamique et
quelle est son utilité en regard notamment à l’utilisation exclusive de pages statiques. L’approche choisie
consiste à définir la raison d’être des solutions étudiées en recensant les limitations des pages statiques par
rapport à l’évolution des besoins des différents acteurs impliqués (les utilisateurs, les programmeurs, les
graphistes) et en voyant comment l’utilisation de langages de programmation pour la création de pages
dynamiques peuvent y apporter une solution.
Le deuxième objectif consiste dans l’analyse des solutions existantes pour la création de pages dynamiques.
Le but est celui d’aboutir à une classification ou une cartographie de ces langages afin d’aider celui qui
voudrait mettre en œuvre un site dynamique à choisir la solution qui lui conviendrait le mieux.
Le troisième objectif est la conception et la réalisation pratique d’un site de commerce électronique en
utilisant un des langages faisant objet de l’étude. Le produit concret de cette partie est un site Web qui
construit ses pages de façon dynamique en fonction du contenu d’une base de données. Les fonctionnalités
principales du site sont la navigation à travers d’un catalogue d’articles, la recherche d’articles par mots clé,
la gestion d’un panier des achats, la possibilité de passer des ordres en ligne et la gestion de la base de
données, notamment pour ce qui est le contenu du catalogue et la gestion des ordres passées par les clients.

- 4 -
2 Résumé
La dernière décennie a été témoin d’une évolution dans les usages des individus avec le développement de
besoins et exigences toujours plus importantes. Parmi les besoins qui se sont le plus développés, on peut citer
les besoins de communication, d’individualisme, de mobilité, d’ubiquité, de rapidité et d’échanges de biens
et d’informations à niveau mondial.
Cette évolution a été à la fois la cause et l’effet de phénomènes tels que la globalisation de l’économie et
l’évolution technologique, en particulier dans le domaine de la communication et de l’informatique. Le
développement et la démocratisation des réseaux informatiques, notamment avec l’apparition du World
Wide Web, a été un des éléments importants de cette évolution.
Avec la croissance du Web et l’arrivée de nouvelles technologies, les attentes de ses utilisateurs, à l’égar des
sites Web se sont développés énormément. Aujourd’hui on s’attend de plus en plus à des sites complets,
interactifs et mis à jour très rapidement, utilisant des technologies de pointe et offrant toujours plus de
fonctionnalités. Dans ce cadre, la technologie initiale basée sur l’utilisation de pages statiques commence à
faire ressentir ses limitations. Pour répondre à ces nouvelles exigences, des programmeurs ont développé des
solutions permettant la création de pages de façon dynamique. Ces solutions ont toutes en commun le fait de
se baser sur des langages de programmation dans lesquels spécifier les instructions pour créer les pages et de
donner la possibilité de séparer le contenu des pages de la façon dont le contenu va être mis en forme et
présenté à l’utilisateur.
Bien que leur apparition soit assez récente, ces dernières solutions ont été rapidement adoptées par un grand
nombre de sites. Même s’il semblerait que la majorité des pages est encore aujourd’hui formée de pages
statiques, leur proportion est toujours en train de diminuer au profit des pages construites à la volée. En effet
ces dernière présentent un certain nombre d’avantages qui en font une solution envisageable, surtout pour les
grands sites et ceux qui veulent offrir des fonctionnalités d’interaction avec leurs utilisateurs. Ces solutions
ont aussi quelques limitations, surtout liées à la plus grande complexité de développement et traitement, qui
en limitent l’adoption, en particulier pour les petits sites.
Ce travail est censé analyser les solutions représentatives disponibles à l’heure actuelle pour générer les
pages de façon dynamique et d’en présenter les avantages et limitations par rapport à l’utilisation de pages
statiques.
Le présent mémoire est structuré de la façon suivante:
La section précédente présente les objectifs du mémoire.
Cette section présente un bref résumé du sujet du mémoire et en présente la structure.
La section 3 de ce travail est consacrée à une introduction historique qui servira à bien définir le contexte
d’apparition et d’évolution du World Wide Web et des pratiques de programmation de pages dynamiques.
Cette introduction doit permettre de comprendre les raisons qui ont porté à son émergence, en montrant
notamment qu’elle constitue une réponse à l’évolution des besoins et des attentes des différents acteurs
concernés et qu’elle permet de surmonter les limitations et les problèmes posés par l’utilisation de pages
Web statiques, qui deviennent de plus en plus contraignantes au fur et mesure de cette évolution.
La section 4 est dédiée à la définition du World Wide Web et à l’explications des mécanismes fondamentaux
qui en caractérisent le fonctionnement et qui sont communs à toute solution pour la création de pages Web,
soit statique ou dynamique.
La section 5 est centrée sur les pages statiques. Leur mode de fonctionnement est expliqué et leurs avantages
et limitations sont passés en revue. L’évolution des besoins est également prise en compte afin de permettre
de mieux comprendre pourquoi les limitations liées à ce type de pages ont porté à la recherche de solutions
alternatives, tels les solutions de programmation de pages dynamiques.

- 5 -
La section 6 est consacrée à l’étude et à la comparaison des différentes solutions disponibles à ce jour pour la
programmation de pages dynamiques. Après avoir expliqué qu’est-ce qu’une page Web dynamique et avoir
présenté les principes généraux de fonctionnement sous-jacent aux pages dynamiques, les différentes
solutions qui sont l’objet du mémoire sont présentées et analysées.
La section 7 présente les conclusions de l’étude sous forme d’un récapitulatif des éléments trouvés dans la
comparaison des différentes solutions et se concrétise dans un tableau synoptique présentant les différents
langages et les cas-type d’utilisation.
La section 8 est formée par une bibliographie commentée, structurée par sections thématiques, d’ouvrages et
articles auxquels ce document fait référence et auxquels se référer pour en savoir plus sur un thème
particulier.
La section 9 est le glossaire des termes techniques.
La section 10 est consacré à la partie pratique de ce travail, avec la présentation de l’application de
commerce électronique développée.
Ce document utilise les conventions suivantes:
• les renvois aux ouvrages présentés la bibliographie sont faits en utilisant le symbole [x] où x
représente le numéro de la référence dans la bibliographie;
• l’explication des termes techniques, dont la première utilisation est formatée en italique et suivie par
un astérisque (mot*), est faite dans le glossaire.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
1
/
99
100%