Télécharger

BCPST1 16-17 INFORMATIQUE TP N° 11
1ère partie : Utilisation de fichiers csv
Un fichier csv (coma separated values) est un fichier contenant du texte, formé de données séparées par
des virgules. Il peut par exemple servir à exporter des données stockées dans une feuille de calcul d'un
tableur vers un script Python.
1) Création d'un fichier csv à partir d'un tableur ( Openoffice.Calc, LibreOffice.Calc, Excel 2013)
1ère étape : choix du séparateur décimal :
Avant de créer un fichier csv à partir d’un tableur, il faut veiller à ce que le séparateur décimal utilisé soit
différent de la virgule, car celle-ci va servir de séparateur entre les données contenues dans les différentes
cellules des tableaux.
Ouvrir une feuille de calcul avec le tableur choisi, et enregistrer un nombre décimal avec une virgule
dans une cellule, et un nombre décimal avec un point dans une autre. Si le nombre s'affiche dans la partie
droite de la cellule, on a utilisé le séparateur décimal correspondant au paramétrage de l'application.
Si ce n'est pas le point, il faut modifier ce paramétrage.
Avec Openoffice.Calc (resp. LibreOffice.Calc):
Dans le menu Outils, choisir Options, dans l'arborescence, choisir Paramètres linguistiques, puis
Langues; dans la boîte de dialogue, dans "Langue pour paramètres linguistiques" (resp. "Paramètres
locaux") choisir Anglais (R-U) et cocher la case touche séparateur de décimales "identique au paramètre
linguistique". (Ne pas modifier la langue pour interface utilisateur). Cliquer sur OK.
Avec EXCEL 2013 : Menu Fichier, Options avancées : décocher la case « Utiliser les séparateurs
systèmes » et dans la case "séparateur décimal", remplacer la virgule par le point.
Vérifier ensuite que le séparateur décimal est bien le point dans la feuille de calcul.
Exemple :
Ouvrez le fichier rongeurs_colonne.ods. Vérifiez que le séparateur décimal est bien le point.
2e étape : création du fichier csv
Enregistrez ce fichier dans le répertoire dans lequel vous allez enregistrer votre script python, en
choisissant comme extension csv. (Il reste affiché dans le tableur mais la mise en forme en donne une idée
trompeuse)
3e étape :Visualisation du résultat : Fermez ce fichier dans le tableur puis, depuis le répertoire, faites un
clic droit dessus, choisissez Ouvrir avec et sélectionnez un éditeur de texte pour visualiser le fichier csv
(ou bien lancez un éditeur de texte et ouvrez le fichier depuis cet éditeur). Observez le résultat.
2) Lecture et extraction de données d'un fichier csv avec Python.
Attention :
- le script Python qui lira le fichier csv devra être dans le même répertoire que ce dernier
(si ce n'est pas le cas il faudra spécifier son chemin d'accès lors de l'ouverture)
- avec Pyzo, lors du premier lancement du script, il faudra utiliser la commande "Exécuter en tant que
script", ou "démarrer le script" afin que le répertoire de travail soit identifié (sinon le fichier à lire ne
sera pas trouvé si on ne précise pas le chemin d'accès)
Pour lire un fichier csv en python, on doit importer le module csv.
La fonction reader de ce module permet de parcourir les lignes du fichier sans les stocker en mémoire.
Si on souhaite garder les lignes en mémoire, on peut les stocker dans une liste au fur et à mesure qu'elles
sont lues. On peut aussi choisir de ne stocker qu'une partie des lignes, ou une partie des données de
chaque ligne.
Exemple :
1) Exécuter le script lecture_ecriture_rongeurs_ac.py et observer le résultat.
2) Compléter le script pour créer et faire afficher :
- un tableau numpy X contenant uniquement les tailles observées, codées comme flottants.
- un vecteur numpy Eff contenant uniquement les effectifs, codés comme entiers.

BCPST1 16-17 INFORMATIQUE TP N°11 (suite)
3) Création d'un fichier csv avec Python
Exemple : dans le script précédent, créer un vecteur Freq contenant les fréquences.
Décommenter les instructions suivantes pour créer un nouveau fichier csv contenant les tailles et les
fréquences.
4) Lecture d'un fichier csv avec LibreOffice et Excel
Avec LibreOffice : lorsqu'on ouvre un fichier csv avec le tableur, une boîte de dialogue s'ouvre pour
choisir les paramètres d'importation. Cocher la virgule comme séparateur de données numériques.
Normalement les données doivent s'afficher correctement dans les cellules.
Avec Excel : lancer d'abord le tableur, ouvrir un nouveau classeur. Dans l'onglet Données du ruban,
choisir Fichiers texte. Une boîte de dialogue s'ouvre; sélectionner le fichier csv choisi et cliquer sur
importer; la fenêtre de l'assistant d'importation apparaît; choisir le type de fichier Délimité, l'origine du
fichier (pour éviter les problèmes d'encodage) et la virgule comme séparateur, vérifier que le résultat
est satisfaisant dans l'aperçu.
2e partie : exemple de statistique univariée continue
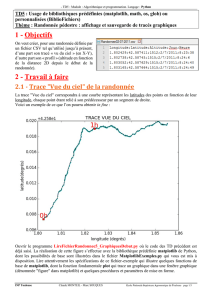
On a mesuré sur un échantillon de moules le rapport R= masse utile / masse brute, exprimé en %.
(Source : http://math.agrocampus-ouest.fr/infoglueDeliverLive/enseignement/support2cours/donnees )
On a réparti les observations en classe d'amplitude 5% :
Les données sont stockées dans le fichier moules_groupees.csv.
1) Créer un script python et importer csv, numpy et matplotlib.pyplot
2) Lire le fichier moules_groupees.csv et stocker ses lignes dans une liste L. Faire afficher L.
3) Créer à partir de cette liste :
– un vecteur numpy Bornesinf qui contient les bornes inférieures des classes (ai),
– un vecteur numpy Eff qui contient les effectifs;
Créer ensuite un vecteur X qui contient les milieux des classes (xi).
Faire afficher ces trois vecteurs.
4) Définir une fonction stats prenant comme arguments des vecteurs X et Eff contenant les milieux des
classes et les effectifs d'une distribution statistique continue quelconque et retourne :
le nombre p de classes, la taille n de l'échantillon, la moyenne observée de la statistique, sa variance
observée ainsi que son écart-type observé. (Placer cette fonction avant le bloc principal)
Créer des variables globales p, n, mX, SX2, SX et leur affecter les valeurs retournées par la fonction
stats appliquée aux variables globales X et Eff de ce script.
Faire afficher les valeurs de p, n, mX, SX.
5) Créer un vecteur numpy Freq contenant les fréquences des classes.
Ajouter une instruction de fermeture de toutes les figures existantes et créer une figure appelée
'frequences'.
Créer l'histogramme des fréquences de la distribution de R à l'aide de la fonction bar (les rectangles
ayant pour largeur l'amplitude des classes, et pour hauteur les fréquences)
Sur la même figure ajouter le polygone des fréquences, c'est-à-dire la ligne brisée joignant les points
de coordonnées (xi, fi).
6) Créer un vecteur numpy Freqcum contenant les fréquences cumulées des classes (f 'i), et un vecteur
Bornessup contenant les bornes supérieures de classes (ai+1)
7) Créer une nouvelle figure appelée "frequences cumulees".
Représenter (sur le même graphique) l'histogramme des fréquences cumulées (fonction bar) et la
courbe cumulative des fréquences, c'est-à-dire la ligne brisée qui joint les points de coordonnées
(a1, 0), (a2, f '1),…, (ai+1, f 'i),…(ap+1,f 'p).
Ajouter des droites "horizontales" permettant de lire sur le graphique la médiane et les quartiles de la
distribution étudiée.
1
/
2
100%