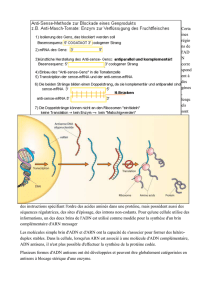
Les nanovirus, petits virus de plantes : similitudes et différences

revue
Les nanovirus, petits virus de plantes :
similitudes et différences avec les géminivirus
T. Timchenko
F. Bernardi
Institut des Sciences du végétal, CNRS,
91198 Gif-sur-Yvette
<taniat@isv.cnrs-gif.fr>
Résumé.La famille des Nanoviridae est divisée en deux genres, les Nanovirus
(qui infectent des plantes légumineuses) et les Babuvirus (qui infectent les
bananiers). L’information génétique des nanovirus est répartie sur plusieurs
molécules d’ADN circulaire simple brin de 1000 nucléotides environ. Ces
molécules sont encapsidées individuellement dans une particule icosaédrique et
codent chacune pour une seule protéine. Les nanovirus se répliquent dans le
noyau des cellules infectées selon un mécanisme de cercle roulant initié par la
protéine virale Rep. Ils comportent plusieurs molécules codant pour des protéi-
nes Rep hétérologues. Toutes les Rep d’un nanovirus donné sont fonctionnelles
et chacune initie la réplication de l’ADN par lequel elle est codée (autoréplica-
tion). Mais parmi toutes ces Rep, Master Rep est la seule protéine capable
d’induire la réplication des autres composants génomiques du virus (transrépli-
cation). L’infection artificielle en utilisant des molécules d’ADN viral cloné n’a
été mise au point que pour le nanovirus Faba bean necrotic yellows virus.
Mots clés :ADN simple brin, composants génomiques multiples, réplication,
mécanisme de cercle roulant
Abstract.Nanoviridae family comprises genus Nanovirus (viruses infecting
legume plants) and Babuvirus (viruses infecting banana plants). Nanovirus
genomes consist of multiple circular single-stranded DNAs of about 1kb each.
They are encapsidated individually in small icosahedral particles. Each DNA
molecule encodes only one protein. Nanoviruses replicate in the nucleus of
infected plants by a rolling-circle replication mechanism initiated by viral Rep
protein. Multiple DNAs encoding similar but clearly distinct Rep proteins have
been described for each nanovirus. All Rep proteins of a given nanovirus are
functional and each initiates replication of the DNA by which it is encoded
(auto-replication). Only the Master Rep protein is able to initiate replication of
other genome components (trans-replication). Induction of nanovirus disease by
cloned genome components was established only for Faba bean necrotic
yellows virus.
Key words:single-stranded DNA, multiple genome components, rolling-
circle replication
Le génome des virus peut être constitué d’un acide ribonu-
cléique (ARN) simple brin ou double brin, ou d’un acide
désoxyribonucléique (ADN) simple brin ou double brin. La
grande majorité des virus qui infectent les plantes possè-
dent un génome à ARN simple brin. Seuls quatre groupes
de virus de plantes possèdent un génome à ADN. Parmi
ceux-ci, on trouve les caulimovirus et les badnavirus avec
un génome composé d’une molécule d’ADN double brin, et
les géminivirus et nanovirus dont le génome est un ADN
simple brin circulaire [1]. Les géminivirus sont l’objet
d’études de plusieurs laboratoires depuis plusieurs dizaines
d’années ; en revanche, il existe peu de données sur les
nanovirus. Pour cette raison, nous présentons les données
Tirés à part : T. Timchenko
Virologie 2007, 11 : 27-42
doi: 10.1684/vir.2007.0046
Virologie, Vol. 11, n° 1, janvier-février 2007
27
Copyright © 2017 John Libbey Eurotext. Téléchargé par un robot venant de 88.99.165.207 le 24/05/2017.

sur les différents aspects de la multiplication des nanovirus
en les comparant avec les géminivirus.
Structure taxonomique des familles
Nanoviridae et Geminiviridae
Les nanovirus ont précédemment été considérés comme
des circovirus de plantes [2-6] et constituaient un genre non
assigné Nanovirus [7]. Récemment, ils ont été classifiés
comme la famille des Nanoviridae [8]. La famille des
Nanoviridae est divisée en deux genres, les Nanovirus et les
Babuvirus. Les Nanovirus infectent des plantes légumineu-
ses (dicotylédones) et sont représentés par le Faba bean
necrotic yellows virus (FBNYV), le Milk vetch dwarf virus
(MDV) et le Subterranean clover stunt virus (SCSV). Le
Banana bunchy top virus (BBTV), qui infecte des musa-
cées (Musa spp), des plantes monocotylédones, est le seul
représentant du genre Babuvirus [8]. Tous les nanovirus
induisent des chloroses, l’enroulement des feuilles, le na-
nisme et la mort prématurée des plantes infectées. Ils sont
transmis par différentes espèces de pucerons de façon per-
sistante et ne se répliquent pas dans l’insecte [9, 10]. Plu-
sieurs espèces de pucerons colonisant des légumineuses,
eg. Aphis fabae, A. cracivora, Acyrthosiphon pisum, trans-
mettent les représentants des Nanovirus. Le BBTV est
transmis par une seule espèce de puceron colonisant les
bananiers, Pentalonia nigronervosa. Il est présent dans les
pays produisant des bananes, en Asie, dans la région Paci-
fique et en Afrique, le SCSV est présent en Australie, le
MDV au Japon et le FBNYV en Asie occidentale, en
Afrique du Nord et de l’Est et en Espagne [8].
L’information génétique des nanovirus est répartie sur plu-
sieurs (jusqu’à 12) molécules d’ADN circulaire simple brin
de 1000 nucléotides (nt) environ (figure 1). Ces molécules
sont encapsidées individuellement dans une particule ico-
saédrique (18-20 nm) et codent chacune, à une exception
près, pour une seule protéine [8].
C. Virus non assigné
:
CFDV
ORF1 (Rep)
ORF3 (CP)
5
1
42
3
6
Composants additionnels para-rep
(ex. FBNYV)
ADN-N
(NSP)
C1
(Rep1)
C7
(Rep7)
C9
(Rep9)
C11
(Rep11)
ADN-U1
(U1)
ADN-U2
(U2)
ADN-U4
(U4)
B. Genre Babuvirus
:
BBTV
Composants génomiques
Composants additionnels para-rep
S1
(RepS1)
S2
(RepS2)
W1
(RepW1)
W2
(RepW2)
CR-SL
ADN-R
(M-Rep
& U5)
CR-M
ADN-N
(NSP)
ADN-U3
(U3)
ADN-S
(CP)
ADN-C
(Clink)
ADN-M
(MP)
A. Genre Nanovirus
:
FBNYV, MVDV, SCSV
Composants génomiques
CR-SL
ADN-R
(M-Rep)
CR-II
ADN-S
(CP)
ADN-C
(Clink)
ADN-M
(MP)
Figure 1. Organisation du génome des nanovirus. Les huit composants génomiques identifiés pour l’ensemble des virus de genre
Nanovirus, six composants génomiques identifiés pour les virus de genre Babuvirus, ainsi que les composants additionnels para-rep sont
présentés (Aet B, respectivement). À l’intérieur de chaque cercle est présenté le nom du composant correspondant et, entre parenthèses,
le nom de la protéine codée. Les flèches en gras indiquent la position et la taille du cadre ouvert de lecture (l’ORF) correspondant. Pour
les virus du genre Nanovirus, les noms des composants additionnels para-rep codant pour les différentes protéines Rep sont présentés
seulement pour le FBNYV. Au sommet de chaque cercle, dans la région non codante, le point avec une barre verticale représente la
structure potentielle tige-boucle et la boîte noire représente une région d’homologie entre les composants génomiques, CR-SL (common
region-stem loop). Une boîte jaune représente une région secondaire d’homologie, appelée CR-M (major common region)etCR-II
(second common region) pour les Babuvirus et Nanovirus, respectivement [29,87]. Une large barre au-dessus de certains composants
indique que ce composant particulier n’a pas été nécessaire pour le développement des symptômes, quand les autres sept composants
du FBNYV ont été inoculés dans V. faba. Aucun des composants ADN-C, N et U4, entre crochets, n’est nécessaire, et seul l’ensemble des
cinq composants qui restent, ADN-R, S, M, U1 et U2 a été capable d’induire les symptômes de la maladie (explication dans le texte). C)
Organisation du génome du virus non assigné CFDV. Les flèches représentent les ORF (de 1 à 6), les fonctions des protéines codées sont
établies seulement pour l’ORF1 (Rep) et l’ORF 3 (CP). D’après Rohde [6]. Rep : protéine initiatrice de réplication ; M-Rep : Master Rep ;
CP : protéine de capside ; MP : protéine de mouvement ; Clink : protéine participante dans la régulation du cycle cellulaire ; NSP : protéine
navette ; U1 à U4 : protéines avec des fonctions inconnues.
revue
Virologie, Vol. 11, n° 1, janvier-février 2007
28
Copyright © 2017 John Libbey Eurotext. Téléchargé par un robot venant de 88.99.165.207 le 24/05/2017.

Le Coconut foliar decay virus (CFDV) est placé dans la
famille Nanoviridae
comme virus non assigné [8]. Il
infecte les arécacées. Mis à part la similitude des particules
virales du CFDV avec celles des nanovirus (particule
icosaédrique de 20 nm) et la petite taille de sa molécule
d’ADN (1291 nt, constituant ainsi l’un des plus petits
génomes viraux de plantes), le CFDV est assez différent des
nanovirus FBNYV, SCSV, MDV et BBTV du point de vue
de l’organisation de son génome. La seule molécule
d’ADN simple brin circulaire, associée à la maladie induite
par le CFDV, porte six cadres ouverts de lecture (ORF)
réparties sur le brin viral (V, qui est encapsidé) et complé-
mentaire (C) synthétisé lors de l’infection [6] (figure 1C).
De ce point de vue, le CFDV ressemble donc plus à un
géminivirus ou à un virus de la famille Circoviridae.La
famille des Circoviridae regroupe les virus animaux dont le
génome est constitué par une seule molécule d’ADN sim-
ple brin circulaire d’environ 2000 nt (avec des gènes situés
sur le brin viral et sur le brin complémentaire) qui est
encapsidée dans des particules icosaédriques de 20 nm
[11, 12].
L’information génétique des géminivirus est concentrée sur
une ou deux molécules d’ADN circulaire simple brin d’envi-
ron 2500 à 3000 nt avec des gènes situés sur le brin viral et sur
le brin complémentaire [13]
. Chaque molécule est encapsi-
dée individuellement dans un icosaèdre double « géminé »
de taille 22 x 38 nm. La famille des Geminiviridae est
divisée en quatre genres : Mastrevirus, Curtovirus, Topo-
cuvirus et Begomovirus sur la base de leur insecte vecteur
(différentes espèces de cicadelles pour les trois premiers
genres et une mouche blanche (ou aleurode) Bemisia tabaci
pour les Begomovirus), de la gamme d’hôte et de la struc-
ture génomique [13] (figure 2). Les virus des genres Mas-
trevirus, Curtovirus et Topocuvirus ont une seule molécule
d’ADN. Les virus du genre Begomovirus possèdent une ou
deux molécules d’ADN. Nous allons mentionner plus tard
quelques géminivirus, comme les bégomovirus, l’African
casava mosaic virus (ACMV),leTomato leaf curl virus
(ToLCV), le Tomato yellow leaf curl virus (TYLCV), le
Tomato golden mosaic virus (TGMV), le Cabbage leaf
curl virus (CaLCuV) et les mastrévirus Wheat dwarf virus
(WDV) et Maize streak virus (MSV).
LIR
V1 (MP)
V2 (CP)
V3 (MP)
C4 V2
C2
IR
V1
(CP)
C3 (REn) C3
ADN B
AV2 (MP)
AV1 (CP)
AC3 (REn)
ADN A
C4
AC2 (TrAP)
AC1
(Rep)
CRA
ADN β
βC1
(βC1)
Rep (Rep)
ADN 1
BV1
(NSP)
BC1
(MP)
V1 (CP)
V2 (MP)
C4
C2
V2
IR
C1
(Rep)
C1
(Rep)
C1
(RepA)
SIR
C1:C2
(Rep)
C2
Mastrévirus Curtovirus Topocuvirus
Bégomovirus
CRB
+
(+)
Figure 2. Organisation du génome des géminivirus. Les géminivirus sont classés en quatre genres, d’après Stanley [13]. Le génome des
bégomovirus peut être constitué soit par une seule molécule d’ADN, soit cette molécule (ADN A) est associée à l’ADNB ou à l’ADNbet
l’ADN1, ce qui est indiqué par un symbole (+) avec des flèches correspondantes. Les flèches à l’intérieur des cercles représentent les
ORF, leurs noms reflètent la position sur le brin viral (V) ou complémentaire (C), le nom des protéines correspondantes est présenté entre
parenthèses. Le point avec une barre verticale représente la structure tige boucle. Rep : protéine initiatrice de réplication ; CP : protéine
de capside ; MP : protéine de mouvement ; NSP : protéine navette ; TrAp : transcription activator protein ; REn : replication enhancer
protein ;bC1 : facteur de pathogenèse) ; IR : intergenic region ; LIR : long intergenic region ; SIR : small intergenic region ; CRA et CRB :
common region, correspondent à la région intergénique homologue entre les molécules A et B pour les bégomovirus bipartites.
revue
Virologie, Vol. 11, n° 1, janvier-février 2007
29
Copyright © 2017 John Libbey Eurotext. Téléchargé par un robot venant de 88.99.165.207 le 24/05/2017.

Organisation du génome et fonctions
des protéines codées par les gémini
et nanovirus
Les protéines des nanovirus ainsi que leurs fonctions ont été
identifiées par homologie avec celles des géminivirus. Pour
cette raison, nous présentons d’abord brièvement les don-
nées concernant les géminivirus. Une ou deux molécules
d’ADN des géminivirus codent pour un nombre très limité
de protéines (figure 2).
La protéine Rep (replication associated protein) est la
seule protéine virale indispensable pour la réplication du
virus correspondant. Chez les géminivirus, à l’exception
des mastrévirus, Rep est codée par l’ORF C1. Chez les
mastrévirus, le gène codant la protéine Rep contient un
intron et la protéine Rep est exprimée à partir d’un transcrit
épissé (C1 : C2). Le transcrit non épissé C1 sert pour
l’expression de la protéine RepA [14]. De ce fait, les
protéines Rep et RepA des mastrévirus ont environ
200 acides aminés (aa) identiques en domaine N-terminal.
Les autres protéines codées par les géminivirus sur le brin
viral sont la protéine de capside (CP) et la protéine de
mouvement (MP). Les mastrévirus ne codent que pour les
quatre protéines mentionnées.
Chez les autres géminivirus, on trouve trois autres ORF, C2,
C3 et C4. Chez les bégomovirus la protéine codée par C2,
TrAP (transcription activator protein), transactive l’ex-
pression des gènes situés sur le brin viral. Pour certains
bégomo et curtovirus, elle joue aussi un rôle de facteur de
pathogenèse dans certaines plantes hôte et un rôle de sup-
presseur du phénomène de régulation d’expression des
gènes appelé silencing. La protéine REn (replication en-
hancer protein), codée par le cadre ouvert de lecture C3 des
bégomo et curtovirus, augmente le taux de réplication de
l’ADN viral. La protéine codée par C4 chez les curto et
bégomovirus est déterminante pour les symptômes de la
maladie et participe dans la suppression du silencing.Le
rôle des protéines codées par C2, C3 et C4 des topocuvirus
reste mal élucidé. La protéine codée par l’ORF V2 des
curtovirus est impliquée dans la régulation du taux relatif de
l’ADN simple brin/double brin [13].
La plupart des bégomovirus sont bipartites (le génome est
composé de deux molécules d’ADN, ADN A et ADN B),
mais certains bégomovirus de l’Ancien Monde ne possè-
dent qu’une seule molécule d’ADN (bégomovirus mono-
partites). LesADNA etADN B possèdent une similitude de
séquence dans la région de l’origine de réplication d’envi-
ron 200 nt [13].
Les bégomovirus de l’Ancien Monde (mono et bipartites)
codent sur le brin viral pour la protéine CP (l’ORFV1/AV1)
qui encapside l’ADN viral et peut être impliquée dans le
mouvement du virus, et la protéine MP (l’ORF V2/AV2)
qui est aussi impliquée dans le mouvement du virus [15,
16]. Les bégomovirus bipartites du Nouveau Monde ne
possèdent pas l’ORF AV2. Dans les cellules de plantes, la
molécule ADN A de bégomovirus bipartite seule peut être
répliquée et produit les virions, mais elle a besoin d’ADN B
pour l’infection systématique. L’ADN B des bégomovirus
bipartites code pour deux protéines qui assurent le mouve-
ment du virus, en plus des protéines CP et MP codées par
l’ADN A. Ce sont la protéine MP et la protéine NSP (nu-
clear shuttle protein), codées sur le brin complémentaire
(l’ORF BC1) et sur le brin et viral (l’ORF BV1), respecti-
vement [17, 18].
Certains géminivirus encapsident aussi des molécules
d’ADN plus petites (de taille d’environ la moitié du gé-
nome), qui sont des molécules d’ADN DI (defective inter-
fering), desADN satellites et desADN satellite-like. Tandis
que les ADN DI sont dérivés de l’ADN du virus, (formés
par délétions), les ADN satellites et satellite-like ont des
séquences très différentes de celle de l’ADN du virus ou
helper virus avec lequel ils sont associés [19].
D’après la nomenclature récente, les satellites sont des
agents subviraux qui ont une séquence nucléotidique subs-
tantiellement différente de celle du helper virus et ne
possèdent pas de gènes codant pour les protéines partici-
pant dans leur réplication. Il y a deux classes de satellites :
les virus satellites et les acides nucléiques (ADN ou ARN)
satellites. Le virus satellite code pour une protéine structu-
rale qui encapside son génome, mais il dépend du helper
virus pour la réplication. Les acides nucléiques satellites
soit encodent une protéine non structurale, soit n’encodent
aucune protéine et sont encapsidés par la protéine CP du
helper virus [20]. Pour leur multiplication, les satellites
dépendent donc du helper virus. Les molécules satellite-
like ressemblent aux satellites, mais elles codent pour une
fonction nécessaire pour le virus et sont considérées
comme faisant partie du génome du virus avec lequel elles
sont associées [20].
Le premier satellite décrit pour les géminivirus a été
ToLCV-sat (682 nt seulement). Une autre molécule,
l’ADNb(d’environ 1 300 nt), a été trouvée associée avec
un nombre croissant des bégomovirus monopartites.
ToLCV-sat et ADNbont une similitude très restreinte avec
leur helper virus localisée dans la région de réplication. En
ce qui concerne les ADN DI et ToLCV-sat, ils ne sont pas
nécessaires pour les symptômes, tandis que l’ADNbpos-
sède un ORFbC1 qui est un déterminant de pathogenèse du
helper virus avec lequel il est associé [19]. Pour cette
raison, l’ADNba été récemment reclassé comme ADN
satellite-like [19] et non comme ADN satellite [20].
Une autre molécule d’ADN a été découverte associée avec
le complexe géminivirus/ADNb, c’est l’ADN1. Elle ne
possède pas d’homologie avec un helper-virus, code pour
une protéine Rep et peut se répliquer en l’absence du
helper-virus [19]. De ce point de vue, l’ADN1 n’est pas un
revue
Virologie, Vol. 11, n° 1, janvier-février 2007
30
Copyright © 2017 John Libbey Eurotext. Téléchargé par un robot venant de 88.99.165.207 le 24/05/2017.

ADN satellite ou satellite-like, il ne dépend du helper virus
que pour son encapsidation et son mouvement dans et entre
les plantes. D’ailleurs, il n’a pas été mentionné et classé
dans le dernier rapport de l’ICTV [20]. Il n’est pas néces-
saire pour la maladie, mais il affecte le niveau d’accumula-
tion de l’ADNbassocié à certains géminivirus [19].
Un nombre variable de molécules d’ADN associées à la
maladie a été trouvé pour les nanovirus (figure 1). Chaque
composant, à l’exception de l’ADN-R de BBTV, possède
un seul ORF sur le brin viral. Pour chaque nanovirus,
plusieurs (deux à cinq) molécules d’ADN codant pour des
protéines Rep ont été décrites (rep-composants), dont une
codant pour M-Rep (Master Rep) (ADN-R, voir ci-
dessous). Ces protéines Rep ont des séquences divergentes
avec des domaines conservés spécifiques pour les protéines
initiatrices de la réplication par mécanisme de cercle rou-
lant (RCR) [21] (figure 3). Seul l’ADN-R de BBTV pos-
sède un petit ORF codant pour une protéine U5 de fonction
inconnue chevauchant l’ORF codant pour M-Rep (en cadre
de lecture « frame+2»)[22].
Nous allons appeler composants « non-rep » l’ensemble
des molécules d’ADN des nanovirus codant pour des pro-
téines autres que Rep (figure 1). Il s’agit des composants
codant pour une protéine structurale de capside (ADN-S)
[23, 24], une protéine Clink qui participe dans la régulation
du cycle cellulaire (ADN-C) [25], une protéine de mouve-
ment (ADN-M) [26], une protéine NSP (nuclear shuttle
protein) (ADN-N)[26] qui ont été identifiés pour tous les
nanovirus. Des composants codant pour des protéines dont
la fonction reste inconnue (ADN-U1 à ADN-U4) n’ont été
décrits que pour certains nanovirus [8] (tableau 1).
La comparaison de séquences des cinq protéines codées par
lesADN identifiés pour tous les quatre nanovirus, ADN-M,
- init.
pRB RCR
int.
+ enh.
+ enh.
+ enh.
+ init.
+ init.
pRB int.
YxxK LxCxE GxxxxGKT/S
YxxK LxCxE
YxxK pRB int. GxxxxGKT/S
YxxK GxxxxxGKT/S
LxCxE
F-box
41 kDa Rep
de mastrévirus
30 kDa RepA
de mastrévirus
40 kDa Rep
de bégomovirus
16 kDa REn
de bégomovirus
33 kDa Rep
de nanovirus
20 kDa Clink
de nanovirus
Figure 3. Structures des protéines des géminivirus et nanovirus
impliquées dans la réplication et/ou la régulation du cycle cellu-
laire. Les protéines sont présentées par les barres horizontales
avec des domaines ou des acides aminés conservés indiqués à
l’intérieur. YxxK indique la tyrosine qui catalyse le clivage de l’ADN
et une lysine conservée, pRB int. ou LxCxE sont les motifs
impliqués dans les interactions avec la protéine du rétinoblastome,
pRB. GxxxxGKT/S est une séquence conservée impliquée dans
l’activité ATPase. Le motif conservé dans le domaine N-terminal
des protéines initiatrices de réplication selon un mécanisme de
cercle roulant (RCR) est indiqué comme boîte noire, les barres
dans Clink indiquent la position du motif F-box. Les
symboles + et −indiquent si la protéine interagit ou pas avec pRB.
Le rôle de protéines dans la réplication (RCR) est indiqué comme
init. pour initiation ou enh. (enhancer) pour augmentation.
Tableau 1.Identifiants des séquences des ADN des nanovirus dans la banque de données GenBank
ADN FBNYV MDV SCSV BBTV
C
a
Numéro
d’accès
C Numéro
d’accès
C Numéro
d’accès
C Numéro
d’accès
R 2 AJ132180 11 AB027511 8 AJ290434 1 S56276
S 5 AJ132183 9 AB009046 5 U16734 3 L41574
C 10 AJ132179 4 AB000923 3 U16732 5 L41578
M 4 AJ132182 8 AB009027 1 U16730 4 L41575
N 8 AJ132186 6 AB000925 4 U16733 6 L41577
U1 3 AJ132181 5 AB000924 7 U16736 ni
U2 6 AJ132184 7 AB000926 ni ni
U3 ni ni ni 2 L41576
U4 12 AJ749902 AB255373 ni ni
para-rep 1 X80879 1 AB000920 2 U16731 W1 L32166
7 AJ132185 2 AB000921 6 U16735 W2 L32167
9 AJ132187 3 AB000922 S1 AF216221
11 AJ005968 10 AB009047 S2 AF216222
Les noms des ADN des nanovirus d’après la nouvelle nomenclature [8, 44] sont indiqués dans la première colonne. Le terme « para-rep » est appliqué à
l’ensemble des molécules des nanovirus codant les protéines Rep autres que Master Rep. Le dendrogramme phylogénétique de leurs séquences est très
complexe [47, 87]. Pour cette raison, les ADN para-rep sont présentés dans le tableau sans regroupement en classes comme ADN para-rep 1, ADN para-rep
2, etc. ni : non identifié.
a
Les colonnes C présentent les noms historiquement attribués pour le nanovirus indiqué, ces noms sont encore utilisés dans certaines publications.
revue
Virologie, Vol. 11, n° 1, janvier-février 2007
31
Copyright © 2017 John Libbey Eurotext. Téléchargé par un robot venant de 88.99.165.207 le 24/05/2017.
 6
7
8
9
10
11
12
13
14
15
16
6
7
8
9
10
11
12
13
14
15
16
1
/
16
100%