Architecture des ordinateurs (par V. Vigneron)


Approche des blocs fonctionnels (Rappel)
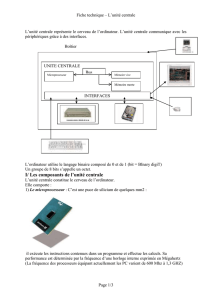
Unité de commande
UNITE CENTRALE MEMOIRE CENTRALE
Instructions
Unites de calcul
Unites d’echanges Peripheriques
Données
Figure 1 – Structure schématique d’un système informatique.
–L’Unité Centrale (UC)→Modèle de Von Neuman
–6=Pd’entités physiques, mais
– unité de traitement (microprocesseur)
– + la mémoire centrale
–L’Unité de Calcul (UAL)ou Unité Arithmétique et Logique = opérations arith-
métiques+logiques
–L’Unité de Commande : gère le bon déroulement des programmes en cours.
– reçoit l’instruction à réaliser
– réparti les ordres aux divers organes
– va chercher l’instruction suivante grâce à un registre (compteur ordinal 1).
–La Mémoire Centrale (MC): ensemble de cellules (de mêmes tailles, le mot
mémoire 2) où on range l’information
–L’Unité d’échange : gère les tranferts des informations entre l’unité centrale et
l’environnement du système informatique (disques durs, imprimantes, écran,. . . ).
–Les périphériques : très nombreux et variés.
– ceux qui émettent des info
– ceux qui en reçoivent
UAL+UC = Unité Centrale = unité de traitement = CPU (Central Processor Unit)
1. compteur ordinal=Compteur d’instructions
2. dont la taille varie selon le type de machine (8, 16, 32 bits,. . . ). Ces cellules sont repérées par leur adresse.
2 [email protected].fr

Unité Centrale de traitement
Un programme = suite d’instructions qui traitent des données
une instruction = opération élémentaire d’un langage de programmation = plus petit
ordre que peut comprendre un ordinateur.
1. Comment est constituée une instruction ?
2. Comment est-elle prise en charge ?
3. Comment est-elle exécutée ?
4. Comment évoluent les données ainsi traitées ?
Exemple : addition de la donnée Aavec la donnée B
basic Let C = A + B
cobol compute C = A + B
Assembleur Z80 ADD A,B
se traduit par la suite binaire 10000001.`
Large
On trouve toujours 2 parties
–ce qu’il faut faire comme action,
–avec quelles données la réaliser.
Les instructions sont représentées sous forme d’éléments binaires 0 ou 1.
Langage evolue (basic,cobol,pascal)
Compilateur
Assembleur
Langage non−evolue
(depend du
processeur : 68000,
80386,80486,...)
Instruction en binaire
0100011010101110
Microcommandes
Figure 2 – Transformation langage évolué →série binaire.
3 [email protected].fr

L’instruction se traduit dans l’UC par une suite ordonnée de commandes appelées
microcommandes 3.
ZONE OPERATION ZONE DONNEES
Ce qu’il faut faire Avec quoi le faire
–la zone opération : permet de savoir
–quelle opération elle doit réaliser
–quels éléments mettre en œuvre
ZONE DONNEES
Ce qu’il faut faire Avec quoi le faire
ZONE OPERATION
Code operation Code complementaire
–la zone adresse : contient l’adresse d’une zone de données. Exemple : l’adresse
FB80. Une des 2 adresses est une adresse implicite, souvent l’accumulateur.
3. Sur 1 octet →256 instructions différentes (jeu d’instruction).
4 [email protected].fr

L’unité de commande
rôle ?
– décode l’instruction en cours,
– lance les microcommandes aux composants, cherche la nouvelle instruction et re-
commence.
Composants de l’unité centrale :
– Le registre d’instruction : charge l’instruction à traiter
Code operation Zone adresse
Registre
d’etat
Microcommandes
Séquenceur Compteur ordinal
Decodeur
+1
Registre d’instruction
Figure 3 – Schéma simplifié de l’unité de commandes.
–le séquenceur : les microcommandes respectent une chronologie précise selon
le type d’instruction à exécuter. Cette "chronologie" est rythmée par un quartz
oscillant à une fréquence entre 20 et 1000 MHz. C’est le composant qui émet ces
microcommandes selon le code instruction de l’instruction
–le registre d’état : mémorise l’état des composants et l’historique des opérations
déjà exécutées, grâce à des indicateurs (flags ou drapeaux 4).
–le compteur ordinal : registre spécialisé chargé automatiquement par le système
lors du lancement d’un programme avec l’adresse mémoire de la première ins-
truction du programme à exécuter. A chaque fois qu’une instruction a été chargée
et s’apprête à être exécutée, ce compteur est incrémenté pour pointer sur l’adresse
de la prochaine instruction à exécuter.
4. Ce sont en fait des registres à bascules qui mémorisent des informations telles que retenue préalable, imparité, résultat nul, etc. . .
5 [email protected].fr
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
1
/
73
100%