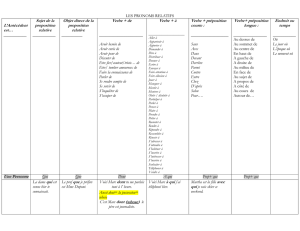
l`apprentissage de l`attachement des PPs

Mettre tout ça ensemble
corpus et annotation
fréquence et proportions
n-grammes
expressions régulières
perl

Le problème
PP modifieur du nom ou du verbe?
J’ai vu l’homme avec les jumelles
J’ai vu l’homme avec le chapeau
Je mange la pizza avec la fourchette
Je mange la pizza au fromage
Je mange la pizza avec une bière

Pourqoui faut-il resoudre ce problème?
Le 70% des erreurs de construction de structure syntaxique
pendant une analyse automatique sont des erreurs d’attachement
de PP.
Donc, si on ameliorait la performance de la resolution de ce
problème, toute l’analyse serait bien meilleure.

Comment faut-il resoudre ce problème?
J’ai vu l’homme avec les jumelles
J’ai vu l’homme avec le chapeau
Je mange la pizza avec la fourchette
Je mange la pizza au fromage
Je mange la pizza avec une bière
Y-a-t-il des régularités visibles qui distinguent entre
attachement au nom et attachement au verbe?
• L’information lexicale, quels mots sont utilisés dans la
phrase, est cruciale.

Attachment du PP: méthode manuelle
1. Recolte d’un petit corpus d’exemples de PPs avec la distinction
entre modifieur du nom ou modifieur du verbe. En général, par
introspection ou récolte non-systematique des données
observationnelles
2. Création des règles régissant les différences entre ces deux cas
de figure par observation jusqu’à couverture des toutes les
données observées
3. Implantation d’un système et extension aux exemples qui
n’avaient pas été prévus
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
1
/
31
100%