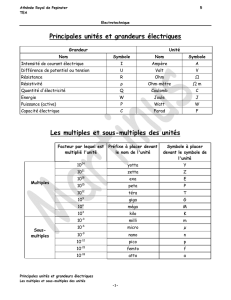
1. theorie de l`information

Théorie de l'information 3
ème
année ENSIL
Vahid Meghdadi 2008/2009
1
1. T
HEORIE DE L
'
INFORMATION
1
1.1. Introduction
La théorie de l'information essai de répondre à deux questions essentielles sur l'analyse et la
synthèse des systèmes de télécommunication :
- Supposons un générateur d'informations, quel est le débit de l'information en sortie du
générateur ?
- Supposons un canal de transmission bruité, quel est le débit maximal de transfert de
l'information à travers ce canal ?
Dans ces deux questions, il existe des mots à définir. D'abord, nous distinguons deux types de
source : analogique et discrète. Un microphone est une source d'informations analogique
produisant un signal analogique en amplitude et en temps. Une source d'information discrète
produit des symboles (ou des lettres comme un clavier). La sortie est une chaîne (ou une
séquence) de symboles. La sortie d'une source d'information analogique peut être transformé
en symboles discrets moyennant un échantillonnage et une quantification.
Dans le cours de la théorie de l'information, nous traitons les sources discrètes à cause de leur
importance en télécommunication numérique.
Une source discrète de l'information dispose d'un ensemble (souvent appelé alphabet) des
symboles (ou des lettres). Elle choisit un symbole dans cet ensemble (suivant une règle
connue par la source) et l'envoie en sortie. Nous avons finalement une séquence des symboles
à des instants discrets.
Un dé par exemple, choisit le symbole à sortir dans l'ensemble de {1, …, 6}. Une séquence
possible peut être {1,5,4,1,2,4,1,1}. La question essentielle est la suivante : quel est le
montant de l'information émise par cette source ? Et ensuite, quelle unité de mesure choisit-on
pour l'information ?
La théorie de l'information est basée principalement sur les travaux de Claud Shannon en
1948. Il établit la limite théorique de performance pour les systèmes de télécommunication. Il
démontre qu'on peut atteindre cette limite "mythique" utilisant des codes correcteurs d'erreur
performants. Il a fallu des dizaines d'années pour approcher à ces limites fixées il y a presque
un demi-siècle. Ce n'est qu'en 1993 que nous avons pu nous approcher de cette limite grâce à
l'invention de turbo code.
Nous essayons dans le cadre de ce cours, de présenter les principes de la théorie de
l'information. La deuxième partie de cours est destiné à présenter le codage de source et de
canal pour maximiser le débit de l'information transmis sur un canal donné.
1
Références : K. Sam Shanmugam, "Digital and Analog Communication Systems", John Wiley & sons 1979
Simon Haykin, "Communication systems", 3
rd
edition, John Wiley & sons, 1994

Théorie de l'information 3
ème
année ENSIL
Vahid Meghdadi 2008/2009
2
1.2. Mesure de l'information
1.2.1. Information contenue dans un message
Une source d'informations produit des messages. Pendant un message, la source sélectionne
de manière aléatoire (aléatoire vu du système de transmission) un symbole dans l'ensemble
des symboles qu'elle a à sa disposition.
On peut considérer par exemple la météo comme une source d'informations. Imaginez qu'elle
essaye de prévoir le temps de demain à Brest. L'ensemble des symboles contient les mots
comme "pluvieux", "ensoleillé", nuageux", "avec éclairci", …. Imaginez de plus que c'est
l'automne et demain c'est un dimanche! Alors lesquelles de ces informations ci-dessous porte
plus d'information :
1. Chaud et ensoleillé
2. Pluvieux
3. Il neigera
Il est clair que ces trois possibilités ne portent pas le même montant d'informations. La
deuxième n'a que très peu d'information car "c'est normal" qu'il pleut en automne à Brest. La
première et la troisième phrases par contre, contiennent plus d'informations car leur
probabilité de réaliser est peu. C'est à dire qu'il y a une relation directe entre la probabilité de
l'occurrence et le montant de l'information. En théorie de l'information, notre interprétation
sur chaque message est indépendant de la quantité de l'information générée par la source!
Par exemple si on vous dit les numéros gagnant de Loto de la semaine prochaine, la quantité
de l'information est indépendante du montant à gagner.
Nous essayons maintenant d'inventer une relation mathématique pour quantifier l'information.
Supposons qu'une source d'informations émet un des q messages possibles m
1
, m
2
, …, m
q
.
avec les probabilités de réalisation p
1
, p
2
, …, p
q
. (p
1
+p
2
+…+p
q
=1). Par intuition, on sait que
l'information portée par k
ième
message ( I(m
k
) ) doit être inversement proportionnelle à p
k
.
L'autre critère par intuition est que quand p
k
tend vers 1, la quantité de l'information tend vers
zéro. On sait aussi que I(m
k
) est toujours positif. C'est à dire :
I(m
k
) > I(m
j
) si p
k
< p
j
I(m
k
)
0 quand p
k
1
I(m
k
) >0 quand 0<p
k
<1
Avant de trouver une fonction satisfaisant toutes ces contraintes, nous allons imposer une
autre. Si nous avons deux messages indépendants, l'information contenue dans les deux est la
somme de l'information de chacun. Cette nouvelle contrainte est parfaitement justifiée par
l'intuition. Une fonction logarithmique satisfait toutes les requis ci-dessus. Ainsi nous
définissons le montant de l'information contenue dans un message qui se produit avec une
possibilité p
k
comme suit :
I(m
k
)=log(1/p
k
)

Théorie de l'information 3
ème
année ENSIL
Vahid Meghdadi 2008/2009
3
L'unité de mesure dépend de la base de la fonction logarithme. Si on prend la base 2, l'unité
sera "bit" (pour Binary digIT).
Exemple :
Une source met en sortie un des 5 symboles possibles dans chaque intervalle de
symbole. La probabilité de réalisation de chaque symbole est donnée ci-dessous :
P
1
=1/2, P
2
=1/4, P
3
=1/8, P
4
=1/16, P
5
=1/16
Calculer le contenu de l'information concernant chaque message (symbole).
Solution : I(m
1
)=log(1/(1/2))=1 bit
I(m
2
)=log(1/(1/4))=2 bits
I(m
3
)=log(1/(1/8))=3 bits
I(m
4
)=log(1/(1/16))=4 bits
I(m
5
)=log(1/(1/16))=4 bits
1.2.2. Entropie
Les messages produits par des sources d'informations sont des séquences de symboles. Du
point de vue des systèmes de télécommunication, un message est composé des symboles
individuels. Nous avons vu que l'information portée par un symbole peut varier suivant sa
probabilité de l'occurrence. Nous sommes donc amenés à définir l'information moyenne
portée par chaque symbole dans un message. L'autre point est que la dépendance des
symboles dans un message peut changer la valeur totale de l'information. Par exemple, on sait
que dans un télex, le "Q" et souvent suivi par un "U". Alors, les symboles individuels ne sont
pas indépendants. Dans ce cas, l'information totale n'est plus égale à la somme des
informations de chaque symbole.
Imaginons que nous avons une source qui émet un des M symboles possibles s
1
, s
2
, …, s
M
, et
de manière indépendante. Les probabilités correspondant sont p
1
, p
2
, …, p
M
. Dans un message
long contenant N symboles nous avons en moyenne Np
1
fois le symbole s
1
, Np
2
fois le
symbole s
2
et ainsi de suite. Le montant de l'information concernant le symbole s
i
est donc
Np
i
log
2
(1/p
i
). Le contenu total de l'information dans le message est égal à :
bitspNppNpI M
iii
M
iiitotale ∑∑ == −== 12
12log)/1(log
L'information moyenne par symbole s'obtient en divisant l'information totale du message par
le nombre de symboles :
symbolebitspp
N
I
HM
iii
totale /)/1(log
12
∑
=
==
L'information moyenne par symbole s'appelle l'entropie de la source. Ceci veut dire que
"normalement nous recevons H bits d'information par symbole dans un message long".

Théorie de l'information 3
ème
année ENSIL
Vahid Meghdadi 2008/2009
4
Exercice :
Calculer l'entropie d'une source qui émet 3 symboles A, B et C avec des probabilités
1/2, 1/4 et 1/4.
Exercice, entropie d'une source binaire sans mémoire :
Une source émet soit un soit zéro avec des probabilités P
1
=P et P
0
=(1-P).
-
Calculer l'entropie de cette source.
-
Tracer l'entropie de la source en fonction de P. Pour quelle valeur de P cette
entropie est maximale ? Quelle est cette valeur maximale ?
remarque :
En général, pour une source émettant ses symboles choisis dans un ensemble de
M élément, l'entropie est maximale si tous les symboles sont équiprobables et indépendants.
On définit le débit d'informations, la somme des informations émises par seconde. Avec cette
définition pour une source à entropie H et le débit de r
s
symboles par seconde, le débit de
l'information émise par cette source est :
R=r
s
H bits/sec
Exercice :
Une source d'information émet un des 5 symboles possibles toutes les milli-secondes.
Calculer l'entropie de la source et le débit de l'information.
1.2.3. Modèle statistique de Markoff pour les sources d'informations
Nous supposons toujours qu'une source d'informations émet un symbole (choisi dans son
alphabet) toutes les T
s
secondes. La source va émettre des symboles suivant une probabilité
qui dépend des symboles précédents et aussi du symbole en question. Une telle source
appelée la source de Markoff peut être exprimée comme suit :
1.
Juste avant de générer un nouveau symbole, la source est dans un des n états possibles. A
chaque émission d'un symbole, la source change son état disons de i à j. La probabilité de
transmission est égale à p
ij
. Cette probabilité dépend
uniquement
de l'état initial i et de
l'état final j. De plus cette probabilité reste constante dans le temps.
2.
En changeant l'état, la source émet un symbole. Ce symbole dépend uniquement de l'état
initial et la transition i
j.
3.
Soit s
1
, s
2
, …, s
M
l'alphabet et X
1
, X
2
, …, X
k
, … la séquence des variables aléatoires
représentant les symboles émis aux instants 1, 2, …, k, … . La probabilité que le symbole
X
k
soit égal à s
q
dépend des symboles précédemment émis. C'est à dire que s
q
est émis
avec la probabilité conditionnelle ci-dessous:
P(X
k
=s
q
|X
1
, X
2
, …, X
k-1
)
4.
L'influence de la séquence X
1
à X
k-1
peut être résumée dans l'état dans lequel la source se
trouve juste avant l'envoi du symbole X
k
, à savoir S
k
. Alors, la probabilité ci-dessus peut
être écrite :
P(X
k
=s
q
|X
1
, X
2
, …, X
k-1
)=P(X
k
=s
q
|S
k
)

Théorie de l'information 3
ème
année ENSIL
Vahid Meghdadi 2008/2009
5
Ceci veut dire que toute l'histoire de la source se résume dans l'état dans lequel elle se
trouve.
5.
Pour le premier symbole la source est dans un des n états possibles avec les probabilités
P
1
(1), P
2
(1), …, P
n
(1). Nous avons donc
1)1(
1=
∑
=
n
ii
P
6.
Si la probabilité que le système (la source) soit dans l'état j au début du k
ième
intervalle est
P
j
(k), on a :
∑
=
=+ n
iijij pkPkP 1)()1(
Nous pouvons présenter cette expression sous forme matricielle. Supposons
P
(k) un
vecteur colonne avec les éléments P
i
(k) et
Φ
une matrice n×n avec (i,j)
ième
élément égal à
P
ij
. On a :
)()1( kk
T
PΦP=+
La matrice
Φ
s'appelle la matrice de probabilité de transition pour un processus Markoff.
La processus est stationnaire si )()( kk
T
P
Φ
P=
pour k=1.
Les sources d'informations dont la sortie peut être modélisée avec un processus stationnaire
Markoff, s'appellent les source stationnaire de Markoff.
Les sources Markoff sont généralement présentées par un graphe qui montre les états, les
transitions et les probabilités correspondant.
Exercice :
Pour le schéma ci-dessous
-
calculer la matrice des transitions
-
calculer la probabilité que la source émet le message "AB"
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
1
/
23
100%