Réduire les accès à la mémoire

1
Architectures haute-performance et
embarquées
Evolutions des architectures versus
autres contraintes
Nathalie Drach
Equipe ASIM
Laboratoire d’Informatique de Paris 6 (LIP6)
Université de Pierre et Marie Curie

2
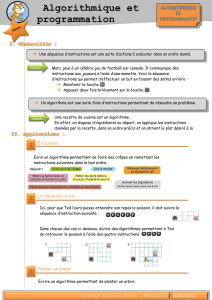
Définitions
Embedded Processor (EP) :
processeur embarqué, processeur
enfoui, processeur spécifique.
General-purpose Processor (GP) :
processeur généraliste, des PC aux
stations haute-performance,
dimmensionnement.
Processeur embarqué = Système
embarqué = processeurs + applications +
OS = indissociables.
Système embarqué : système inclus
(embarqué) dans un système plus large et
son existence comme « ordinateur » n’est
pas apparente.
Différences : applications, volume de production (marché) et
contraintes d’utilisation.
Similitudes : architectures et applications émergeantes.

3
Applications
GP : applications bureautiques, applications
scientifiques.
EP : produits de consommation courante, équipements
audio-vidéo de la maison, portables, systèmes
multimédia, consommables électroniques,
périphériques, infrastructures de communications,
systèmes de contrôle, ...

4
Marché
GP représente -
1% de tous les
processeurs
vendus chaque
année (~ 100
millions de GP).
$30B
$7.9B/27%
$5.7B/19%
$10B/33%
8-bit
micro
16-bit
micro
DSP
32-bit
micro $5.2B/17%
$1.2B/4%
32 bit DSP
EP représente
99% des ventes!
Ominiprésence
ì... the New York Times has estimated
that the average American comes into
contact with about 60 microprocessors
every day....î [Camposano, 1996]
Latest top-level BMWs contain over 100
micro-processors [Personal
communication]

5
Consommation/dissipation,
Côut,
Taille du code,
Temps réel,
Fiabilité, sécurité, flexibilité, ...
Performance versus délai de propagation.
La performance, mais aussi…
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
1
/
88
100%