Architecture matérielle des systèmes informatiques

Directrice de publication : Valérie Brard-Trigo
Les cours du Cned sont strictement réservés à l’usage privé de leurs destinataires et ne sont pas destinés à une utilisation collective. Les personnes
qui s’en serviraient pour d’autres usages, qui en feraient une reproduction intégrale ou partielle, une traduction sans le consentement du Cned,
s’exposeraient à des poursuites judiciaires et aux sanctions pénales prévues par le Code de la propriété intellectuelle. Les reproductions par
reprographie de livres et de périodiques protégés contenues dans cet ouvrage sont effectuées par le Cned avec l’autorisation du Centre
français d’exploitation du droit de copie (20, rue des Grands Augustins, 75006 Paris).
BTS Informatique de gestion – 1re année
Pacôme Massol
Architecture matérielle des
systèmes informatiques
Cours 2

8 3017 TG PA 00
3
Sommaire
Séquence 10 : L’unité de traitement (la rapidité de calcul) 5
Séquence 11 : L’unité de traitement (la mémoire centrale) 17
Atelier 7 : L’unité de traitement 27
Séquence 12 : L’unité de traitement (les bus) 33
Séquence 13 : Le contrôle d’erreur 45
Atelier 8 : Le contrôle d’erreur 57
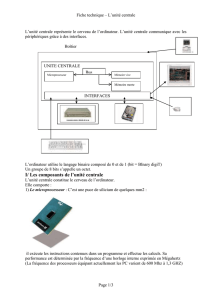
Séquence 14 : Les interfaces 63
Séquence 15 : Les périphériques d’entrée 73
Séquence 16 : Les périphériques de sortie 87
Séquence 17 : Les mémoires de masse 101
Séquence 18 : Les serveurs 125
Atelier 9 : Étude du marché informatique 137

8 3995 TE PA 02
5
Séquence 10
L’unité de traitement
(la rapidité de calcul)
Durée approximative : 1 heure
L’argumentaire classique des fabricants de microprocesseur est de vendre tou-
jours plus « de puissance ». Que recouvre cette notion ? Comment détermine-
t-on la puissance d’un processeur ? Quelles technologies sont proposées pour
améliorer cette puissance ? Nous tentons de répondre à ces questions dans cette
séquence.
u Objectif
À la fin de cette séquence, vous saurez quelles technologies sont mises en œuvre dans
les processeurs afin d’améliorer la rapidité de calcul.
Que faire si je bloque ?
Reportez-vous aux livres déjà cités. De nombreux sites Internet proposent des explica-
tions sur ces notions. Consultez également les sites des fabricants de microprocesseurs.
u Contenu
1. Évaluer la rapidité de calcul ............................................................... 6
2. Optimiser le cycle d’instruction ........................................................ 7
3. Exécuter des instructions simultanément .................................... 8
3A. Architecture superscalaire ........................................................................... 8
3B. HyperThreading ............................................................................................ 8
3C. Architecture multicore ................................................................................. 9
4. Augmenter la taille des opérations ................................................ 9
5. Optimiser les accès mémoire ........................................................... 10
6. Diminuer le jeu d’instructions pour gagner de la place ....... 11
7. Intégrer un coprocesseur ................................................................... 11
8. Un cas réel : le Pentium 1 .................................................................. 12
u QCM d’auto-évaluation ..................................................................... 15

8 3995 TE PA 02
6
Séquence 10
1. Évaluer la rapidité de calcul
Pour déterminer la « puissance » d’un processeur, on évalue le nombre d’opérations
qu’il peut traiter par seconde. Cela se chiffre généralement en millions ou milliards
d’opérations par seconde. Les principales unités sont :
– le MIPS : million d’instructions par seconde
– le MFLOPS : million d’opérations sur les nombres flottants1 par seconde.
Ces indicateurs sont intéressants mais ils sont quelque peu « bruts ». Ils reflètent bien la
rapidité de calcul d’un processeur mais pas celle d’un ordinateur qui est un ensemble de
composants. Des outils plus sophistiqués produisent des indices calculés à partir d’une
simulation d’utilisation « normale » de l’ordinateur (par exemple, temps pour recalculer
une page de tableur, pour consulter une base de données, nombre d’images affichées
par seconde pour un jeu en 3D, etc.). De nombreux indices existent : SPEC CPU2006
(www.spec.org), 3Dmark (www.futuremark.com), etc.
Exercice 84
Recherchez sur Internet un comparatif de la puissance des derniers processeurs Intel et AMD.
Analysez-le.
Nous allons maintenant faire un tour d’horizon des procédés mis en œuvre par les
constructeurs pour améliorer la rapidité de calcul de leurs produits. Certes, on peut
augmenter la fréquence de l’horloge, ainsi le cœur du microprocesseur (le séquenceur)
fonctionnera plus vite. Mais c’est limité : une augmentation de la fréquence entraîne
un échauffement important du composant. En réduisant la taille des transistors qui le
composent on peut diminuer l’échauffement mais on augmente le coût de fabrication…
Les fabricants recherchent donc d’autres possibilités.
å Nombre à virgule. Cette unité est un bon indicateur car les calculs sur les nombres à virgules
sont généralement plus lents car plus complexes que les calculs sur les nombres entiers.

L’unité de traitement (la rapidité de calcul)
8 3995 TE PA 02
7
2. Optimiser le cycle d’instruction
Nous avons vu que le cycle d’exécution d’une instruction est découpé en tâches. Par
exemple, sur le CNED86, nous avons distingué 5 tâches :
– R.I. = Recherche de l’Instruction en mémoire centrale ;
– D.I. = Décodage de l’Instruction ;
– R.O. = Recherche des Opérandes en mémoire centrale ;
– X.I. = eXécution de l’Instruction ;
– S.R. = Stockage du Résultat en mémoire centrale.
Exemple : observons l’exécution d’un programme comportant deux instructions 1 et 2 :
R. I.1D.I.1R.O.1X.I.1S.R.1R.I.2D.I.2R.O.2X.I.2S.R.2
Figure 1 : traitement des instructions en séquence
Si l’on suppose que chaque tâche coûte 1 unité de temps, les deux instructions sont trai-
tées en 10 unités de temps. On constate que, par exemple, l’utilisation du décodeur n’est
pas optimale : il ne fonctionne que pendant deux unités de temps et ne fait rien pendant
les huit autres. C’est inadmissible ! Heureusement, on a trouvé un moyen de mieux faire
travailler ce petit fainéant. Il s’agit du pipeline.
Le principe du pipeline consiste à commencer le traitement de l’instruction suivante
avant que la précédente ne soit terminée.
Démontrons cela sur un schéma :
R.I.2D.I.2R.O.2X.I.2S.R.2
R. I.1D.I.1R.O.1X.I.1S.R.1
Figure 2 : Traitement des instructions en « pipe-line »
Dans l’exemple, les deux instructions sont exécutées en 6 unités de temps soit un gain
de 40%.
Le nombre d’instructions qui peuvent être traitées suivant le principe du pipeline donne
le nombre d’étages du pipeline.
temps
1 2
temps
1
2
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
1
/
134
100%