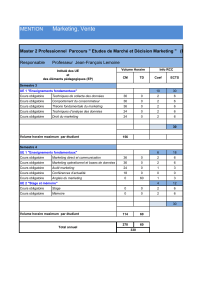
Structure de données en Text Mining


Plan
1Introduction
2Les structures dynamiques (RAM)
Table de Hashage
Arbres binaires de recherche
Splay Tree
Trie, Suffix Tree et Patricia Trie
TST: Ternary Search Tree
Burst Tree
Judy Array
3Les structures dynamiques (Disque)
String B-Tree
4Les structures statiques (RAM)
Trie compil´e
5Les structures statiques (Disque)
String B-Tree statique
6Conclusion / R´ef´erences
Julien Lemoine () Structure de donn´ees en Text Mining 29 mai 2008 2 / 110

Introduction
Usage
Structure de donn´ees: li´ee `a un/des algorithme(s)
Type de structure de donn´ees
Structures g´en´eralistes (Tableaux, Tables de hashages, arbres de
recherches binaires, ...)
Chaque domaine a des structures de donn´ees sp´ecifiques:
par exemple les transducteurs en NLP
Julien Lemoine () Structure de donn´ees en Text Mining 29 mai 2008 3 / 110

Structures utilis´ees dans notre domaine
Dictionnaires
Dans notre m´etier: 99% des structures sont des dictionnaires
Objectif: associer une valeur Y`a chaque cl´e X
Exemples:
dictionnaire de mots
dictionnaire de n-grams
dictionnaire associant des meta-donn´ees `a une url
dictionnaire associant des co-occurrences `a un mot
· · ·
Julien Lemoine () Structure de donn´ees en Text Mining 29 mai 2008 4 / 110

Structures utilis´ees dans notre domaine
Algorithmes
Les algorithmes appliqu´es sur ces structures de donn´ees sont souvent
plus complexes qu’une simple recherche exacte
Par exemple:
recherche via une expression r´eguli`ere
recherche approximative (trouver l’orthographe la plus proche)
recherche par pr´efixe(trouver toutes les urls d’un site dans un
dictionnaire d’urls)
...
Julien Lemoine () Structure de donn´ees en Text Mining 29 mai 2008 5 / 110
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
1
/
111
100%