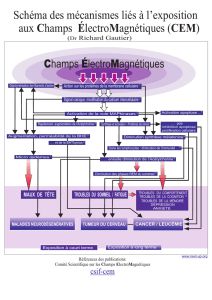
Les fautes d`accord en nombre entre le sujet et le verbe en français

LES FAUTES D’ACCORD EN NOMBRE ENTRE LE SUJET ET LE VERBE
EN FRANÇAIS ET EN ALLEMAND
Magisterarbeit
zur
Erlangung der Würde
der Magistra Artium
der Philologischen, Philosophischen und Wirtschafts- und
Verhaltenswissenschaftlichen Fakultät der
Albert-Ludwigs-Universität
Freiburg i. Br.
vorgelegt von
Sarah Schimke
aus Münster
SS 2004
Romanische Philologie: Französisch (Hauptgebiet) und Spanisch (Nebengebiet)

Mes remerciements s’adressent au Dr. Lars Konieczny, pour son aide relative au contenu, à la
modélisation et à la préparation de l’expérience,
et aux Dr. Lars Konieczny, Prof. Wolfgang Raible, Prof. Georges Kleiber et Dr. Barbara
Hemforth, qui ont rendu ce mémoire possible et m’ont apporté leur soutien pendant sa
réalisation.

1
Table de Matières
Table de Matières......................................................................................................... 1
1. Introduction............................................................................................................ 3
2. L’état de la recherche sur l’accord entre sujet et verbe.......................................... 5
2.1. Un modèle cadre de la production du langage................................................ 5
2.2. Résultats empiriques fondamentaux ............................................................... 9
2.2.1. L’effet mismatch ...................................................................................... 9
2.2.2. L’asymétrie singulier- pluriel................................................................. 10
2.2.3. Les niveaux conceptuel et morpho-phonologique du nombre............... 12
2.2.4. Résumé................................................................................................... 15
2.3. Modèles d’explication................................................................................... 16
2.3.1. Les modèles d’explication non-syntaxiques .......................................... 16
2.3.1.1. Les approches basées sur la distance .............................................. 16
2.3.1.2. Les approches basées sur la mémoire ............................................. 17
2.3.2. Etudes empiriques sur les modèles non-syntaxiques ............................. 19
2.3.3. Les modèles d’explication syntaxiques.................................................. 23
2.3.3.1. Clausal Packaging.......................................................................... 23
2.3.3.2. Feature Percolation........................................................................ 24
2.3.3.3. Agreement and Movement............................................................... 26
2.3.4. Etudes empiriques sur les modèles syntaxiques .................................... 28
2.3.5. Le modèle basé sur l’activation de Hemforth et Konieczny.............. 33
2.3.5.1. Les données de base........................................................................ 33
2.3.5.2. Le modèle........................................................................................ 35
2.3.6. Le potentiel explicatif du modèle basé sur l’activation ......................... 37
2.3.6.1. Le potentiel explicatif pour les données présentées jusqu’ici......... 37
2.3.6.2. Les effets de l’accord dans la compréhension................................. 38
2.3.6.3. L’existence d’une erreur générale de singulier ............................... 41
2.3.6.4. Résumé............................................................................................ 44
2.4. Résumé de l’état de la recherche................................................................... 44
3. La modélisation.................................................................................................... 48
3.1. Présentation globale d’ACT-R...................................................................... 48
3.1.1. La structure d’ACT-R ............................................................................ 49
3.1.2. Le niveau symbolique ............................................................................ 50
3.1.3. Le niveau sous-symbolique.................................................................... 53
3.2. Description du modèle .................................................................................. 56
3.2.1. Réflexions préliminaires ........................................................................ 56
3.2.2. Le modèle au niveau symbolique........................................................... 59
3.2.2.1. Le savoir lexical et morphologique................................................. 60
3.2.2.2. Les productions et les buts : introduction et vue d’ensemble ......... 61
3.2.2.3. Le traitement lexical des syntagmes ............................................... 62
3.2.2.4. Le rattachement des syntagmes modificateurs................................ 66
3.2.2.5. La représentation et le traitement du nombre.................................. 67
3.2.2.6. Les processus de traitement superordonnés .................................... 69
3.2.2.7. La production du nombre du verbe................................................. 72
3.2.2.8. Résumé............................................................................................ 76
3.2.3. Le modèle au niveau sous-symbolique .................................................. 77
3.2.3.1. L’erreur générale de singulier ......................................................... 78
3.2.3.2. L’effet mismatch après les têtes au singulier .................................. 84
3.2.4. Résultats................................................................................................. 86

2
3.2.5. Discussion .............................................................................................. 87
3.2.6. Couverture des données obtenues jusqu’ici ........................................... 89
3.3. Résumé.......................................................................................................... 94
4. Vérification empirique: Le transfert à la langue française................................... 95
4.1. Introduction................................................................................................... 95
4.2. Methode ........................................................................................................ 96
4.3. Résultats........................................................................................................ 98
4.4. Discussion ..................................................................................................... 99
5. Discussion générale et perspectives de recherche.............................................. 102
Bibliographie............................................................................................................ 105
Annexe ..................................................................................................................... 109
I. Le modèle ....................................................................................................... 109
Les types de chunk............................................................................................ 109
La mémoire déclarative ................................................................................... 109
Les productions................................................................................................ 109
Les valeurs de paramètres ............................................................................... 114
Code pour le déroulement de l’expérience ...................................................... 114
II. Protocoles de passages du modèle................................................................. 117
protocole 1 ....................................................................................................... 117
protocole 2 ....................................................................................................... 118
protocole 3 ....................................................................................................... 121
protocole 4 ....................................................................................................... 124
protocole 5 ....................................................................................................... 129
protocole 6 ....................................................................................................... 134
protocole 7 ....................................................................................................... 139
III. Matériel de l’expérience............................................................................... 141
IV Zusammenfassung in deutscher Sprache ...................................................... 142

3
1. Introduction
Ce travail porte sur les erreurs d’accord en nombre entre sujet et verbe en se plaçant
dans une optique psycholinguistique. Nous tenterons d’éclaircir ce phénomène en
étudiant en particulier la langue allemande et la langue française. Comme les proces-
sus de l’établissement de l’accord ne diffèrent pas fondamentalement entre le fran-
çais, l’allemand et d’autres langues apparentées, pour lesquelles d’ailleurs la recher-
che sur ce phénomène est souvent plus avancée, nous nous référerons aussi bien à
des résultats de recherche concernant l’allemand et le français qu’à des résultats
concernant ces autres langues. Il s’agit de résultats concernant surtout l’anglais, mais
aussi le néerlandais, l’espagnol et l’italien.
Au premier abord, l’accord en nombre entre sujet et verbe semble être un processus
extrêmement facile dans toutes ces langues, car il existe une règle claire: Le verbe se
met au même nombre que la tête du syntagme nominal qui fonctionne comme sujet
de la phrase (voir p. e. Dubois, 1965).
Toutefois, l’application de cette règle nécessite l’établissement d’une relation entre
deux éléments d’une phrase qui peuvent parfois être très éloignés l’un de l’autre. En
psycholinguistique, le fonctionnement exact des telles dépendances sur de longues
distances n’est pas encore entièrement clair. L’étude des erreurs peut être un moyen
d’approfondir la connaissance du fonctionnement normal de telles dépendances.
Dans les dernières années, une série d’expériences psycholinguistiques a été menée
pour déterminer les conditions dans lesquelles apparaissent les erreurs et tirer des
conclusions sur l’établissement de l’accord en général.
Dans la deuxième partie de ce travail, nous résumerons l’état de cette recherche psy-
cholinguistique sur l’accord sujet-verbe. Nous exposerons d’abord brièvement quel-
ques bases théoriques sur lesquels se fonde la majorité des études. Ensuite, nous pré-
senterons des résultats expérimentaux fondamentaux. Dans le paragraphe suivant,
nous présenterons différents modèles d’explication et leur socle empirique respectif.
Nous montrerons ainsi que le modèle basé sur l’activation, proposé par Hemforth et
Konieczny (2003), est actuellement le modèle le plus apte à expliquer les résultats
connus. Les parties suivantes de ce travail, en conséquence, sont basées sur ce mo-
dèle.
Dans la troisième partie, qui représente la partie centrale, nous présenterons une mo-
délisation cognitive sur ordinateur qui se base sur le modèle de Hemforth et Ko-
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
1
/
144
100%