CAHIER D`EXERCICES de BIOCHIMIE 2. Biologie Moléculaire

http://www.chusa.upmc.fr/disc/bio_cell
PCEM1
CAHIER D'EXERCICES
de BIOCHIMIE
2007-2008
EDITE PAR LE DEPARTEMENT DE BIOLOGIE
2. Biologie
Moléculaire
L'étude des acides nucléiques

Cahier d'Exercices de Biochimie / PCEM1 Biologie Moléculaire / 2
Faculté de Médecine Pierre & Marie Curie
CAHIER D'EXERCICES POUR PCEM1
BIOCHIMIE
II. BIOLOGIE MOLECULAIRE:
l'étude des acides nucléiques
SOMMAIRE
Page
1. Structure des acides nucléiques .........………. 3
2. Transcription ....................……........ 3
3. Traduction .................……................ 4
4. Réplication et Réparation ..........…......... 11
5. Altérations du matériel génétique et
Outils de Biologie moléculaire ......………... 12
6. QCM ………………………….......………... 16
7. Annales du concours ……………….......……. 22
ANNEXES.
I • Code génétique ................………..... 27
II • Codes des acides aminés ......………..... 27
Image de couverture :
Photographie en microscopie électronique d'une fourche de réplication déficiente
chez un mutant de levure. Une anomalie lors de la réplication d'ADN serait l'un des
mécanismes contribuant à l'instabilité génomique
(Science-26 juil 2002 www.sciencemag.org)

Cahier d'Exercices de Biochimie / PCEM1 Biologie Moléculaire / 3
Faculté de Médecine Pierre & Marie Curie
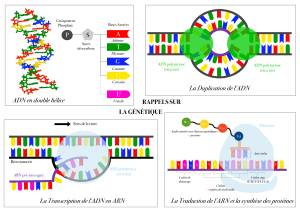
1. STRUCTURE DES ACIDES NUCLEIQUES
1.1 Structure de l’ADN
a. Par convention la séquence d’un simple brin d’une molécule d’ADN est écrite dans le sens
5’ (gauche) - 3’ (droite).
Quels sont les groupements chimiques correspondant à ces extrémités ?
b. Un échantillon d’ADN contient 28,9 moles pour 100 d’adénine. Quels sont les
pourcentages de thymine, guanine et cytosine ? Quelles caractéristiques structurales
permettent de différencier ces bases?
c. Est-ce que la proposition suivante est vraie : « si la séquence d’un déoxyribonucléotide
est p C p T p G p G p A p C , alors sa séquence complémentaire est p G p A p C p C
p T p G » ?
1.2 Soit le fragment d'ADN suivant:
5'ACTTC3'
3'TGAAG5'
a. Par l'intermédiaire de quels atomes et de quel type de liaison cette structure est-elle
stabilisée?
b. Comment peut-on dénaturer cette molécule?
c. Quel intérêt présente la possibilité de réassocier des simples brins d'ADN entre eux
?
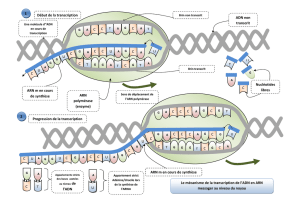
2.TRANSCRIPTION
2.1 Déroulement de la transcription d’un gène
a. Quelle est la définition d’un gène?
b. Quels sont les composants moléculaires nécessaires à la transcription
?
c. Comment se fait l’initiation de la transcription?
d. Quel est le sens d’incorporation des nucléotides dans l’ARN en cours de synthèse
?
e. Quel est le sens de lecture du brin matrice lors de la transcription
? Comment
appelle-t-on ce brin matrice?
f. Montrer comment un signal hormonal peut réguler l’expression d’un gène.
2.2 Citer les 3 évènements indispensables à la maturation post-transcriptionnelle des
transcrits primaires d'ARN conduisant à la formation des ARN messagers chez les
Eucaryotes. Vous préciserez le déroulement chronologique, les étapes ainsi que le rôle de
chacune de ces modifications nucléaires.
2.3 Compléter les propositions suivantes.
a. La synthèse d’ARN, qui est aussi appelée ____________________, est un processus
hautement sélectif.
b. La transcription commence quand une molécule d’_________________________ se lie à une
séquence ____________________ sur la double hélice d’ADN;
c. L’___________________________ transcrit les gènes dont les ARN seront traduits en
protéines, l’______________________________ synthétise les grands ARN ribosomiques, et
l’_____________________________ produit une variété d’ARN stables très petits.
d. L’addition d’un nucléotide G méthylé à l’extrémité 5’ d’un transcrit initial forme la
___________________ , qui semble protéger de la dégradation l’ARN en élongation, et joue un
rôle important dans l’initiation de la synthèse protéique.

Cahier d'Exercices de Biochimie / PCEM1 Biologie Moléculaire / 4
Faculté de Médecine Pierre & Marie Curie
e. L’extrémité 3’ de la plupart des transcrits de la polymérase II est définie par une
modification, au cours de laquelle le transcrit en élongation est clivé à un site spécifique,
et une _________________ est ajoutée à l’extrémité 3’ coupée par une polymérase distincte.
f. Les modifications des extrémités 5’ et 3’ d’une chaîne d’ARN terminent la formation du
_____________________ .
g. Les séquences codantes d’ARN de chaque côté de l’intron sont réunies l’une à l’autre
après que la séquence intronique ait été retirée; Cette réaction est connue sous le nom
d’_____________________________ .
h. Les séquences consensus aux deux extrémités d’un intron sont appelées
_______________________ et _____________________.
2.4 Compléter les propositions suivantes.
a. Les protéines _______________________ stimulent ou inhibent la transcription de certains
groupes de gènes spécifiques.
b. Le motif de liaison à l’ADN en ________________________ a été retrouvé dans des protéines
de liaison à l’ADN chez les eucaryotes et les procaryotes; il contient dans sa structure un
ou plusieurs ions métalliques.
c. Le motif ______________________________ est ainsi appelé car deux hélices , provenant de
chaque monomère, se rejoignent pour former une bobine enroulée.
d. Le motif ____________________________ consiste en une courte hélice reliée par une
boucle à une deuxième hélice , plus longue.
3. TRADUCTION
3.1 Expression du gène de l’apolipoprotéine E
Séquence du gène codant pour l’Apolipoprotéine E humaine(allèle Epsilon 4).
(Genbank : HUMAPOE4)
1 GGAACTTGAT GCTCAGAGAG GACAAGTCAT TTGCCCAAGG TCACACAGCT GGCAACTGGC AGACGAGATT CACGCCCTGG 80
81 CAATTTGACT CCAGAATCCT AACCTTAACC CAGAAGCACG GCTTCAAGCC CTGGAAACCA CAATACCTGT GGCAGCCAGG 160
161 GGGAGGTGCT GGAATCTCAT TTCACATGTG GGGAGGGGGC TCCTGTGCTC AAGGTCACAA CCAAAGAGGA AGCTGTGATT 240
241 AAAACCCAGG TCCCATTTGC AAAGCCTCGA CTTTTAGCAG GTGCATCATA CTGTTCCCAC CCCTCCCATC CCACTTCTGT 320
321 CCAGCCGCCT AGCCCCACTT TCTTTTTTTT CTTTTTTTGA GACAGTCTCC CTCTTGCTGA GGCTGGAGTG CAGTGGCGAG 400
401 ATCTCGGCTC ACTGTAACCT CCGCCTCCCG GGTTCAAGCG ATTCTCCTGC CTCAGCCTCC CAAGTAGCTA GGATTACAGG 480
481 CGCCCGCCAC CACGCCTGGC TAACTTTTGT ATTTTTAGTA GAGATGGGGT TTCACCATGT TGGCCAGGCT GGTCTCAAAC 560
561 TCCTGACCTT AAGTGATTCG CCCACTGTGG CCTCCCAAAG TGCTGGGATT ACAGGCGTGA GCTACCGCCC CCAGCCCCTC 640
641 CCATCCCACT TCTGTCCAGC CCCCTAGCCC TACTTTCTTT CTGGGATCCA GGAGTCCAGA TCCCCAGCCC CCTCTCCAGA 720
721 TTACATTCAT CCAGGCACAG GAAAGGACAG GGTCAGGAAA GGAGGACTCT GGGCGGCAGC CTCCACATTC CCCTTCCACG 800
801 CTTGGCCCCC AGAATGGAGG AGGGTGTCTG TATTACTGGG CGAGGTGTCC TCCCTTCCTG GGGACTGTGG GGGGTGGTCA 880
881 AAAGACCTCT ATGCCCCACC TCCTTCCTCC CTCTGCCCTG CTGTGCCTGG GGCAGGGGGA GAACAGCCCA CCTCGTGACT 960
961 GGGCTGCCCA GCCCGCCCTA TCCCTGGGGG AGGGGGCGGG ACAGGGGGAG CCCTATAATT GGACAAGTCT GGGATCCTTG 1040
1041 AGTCCTACTC AGCCCCAGCG GAGGTGAAGG ACGTCCTTCC CCAGGAGCCG GTGAGAAGCG CAGTCGGGGG CACGGGGATG 1120
1121 AGCTCAGGGG CCTCTAGAAA GAGCTGGGAC CCTGGGAAGC CCTGGCCTCC AGGTAGTCTC AGGAGAGCTA CTCGGGGTCG 1200
1201 GGCTTGGGGA GAGGAGGAGC GGGGGTGAGG CAAGCAGCAG GGGACTGGAC CTGGGAAGGG CTGGGCAGCA GAGACGACCC 1280
1281 GACCCGCTAG AAGGTGGGGT GGGGAGAGCA GCTGGACTGG GATGTAAGCC ATAGCAGGAC TCCACGAGTT GTCACTATCA 1360
1361 TTATCGAGCA CCTACTGGGT GTCCCCAGTG TCCTCAGATC TCCATAACTG GGGAGCCAGG GGCAGCGACA CGGTAGCTAG 1440
1441 CCGTCGATTG GAGAACTTTA AAATGAGGAC TGAATTAGCT CATAAATGGA ACACGGCGCT TAACTGTGAG GTTGGAGCTT 1520
1521 AGAATGTGAA GGGAGAATGA GGAATGCGAG ACTGGGACTG AGATGGAACC GGCGGTGGGG AGGGGGTGGG GGGATGGAAT 1600
1601 TTGAACCCCG GGAGAGGAAG ATGGAATTTT CTATGGAGGC CGACCTGGGG ATGGGGAGAT AAGAGAAGAC CAGGAGGGAG 1680
1681 TTAAATAGGG AATGGGTTGG GGGCGGCTTG GTAAATGTGC TGGGATTAGG CTGTTGCAGA TAATGCAACA AGGCTTGGAA 1760
1761 GGCTAACCTG GGGTGAGGCC GGGTTGGGGG CGCTGGGGGT GGGAGGAGTC CTCACTGGCG GTTGATTGAC AGTTTCTCCT 1840
1841 TCCCCAGACT GGCCAATCAC AGGCAGGAAG ATGAAGGTTC TGTGGGCTGC GTTGCTGGTC ACATTCCTGG CAGGTATGGG 1920
1921 GGCGGGGCTT GCTCGGTTCC CCCCGCTCCT CCCCCTCTCA TCCTCACCTC AACCTCCTGG CCCCATTCAG ACAGACCCTG 2000
2001 GGCCCCCTCT TCTGAGGCTT CTGTGCTGCT TCCTGGCTCT GAACAGCGAT TTGACGCTCT CTGGGCCTCG GTTTCCCCCA 2080
2081 TCCTTGAGAT AGGAGTTAGA AGTTGTTTTG TTGTTGTTGT TTGTTGTTGT TGTTTTGTTT TTTTGAGATG AAGTCTCGCT 2160
2161 CTGTCGCCCA GGCTGGAGTG CAGTGGCGGG ATCTCGGCTC ACTGCAAGCT CCGCCTCCCA GGTCCACGCC ATTCTCCTGC 2240
2241 CTCAGCCTCC CAAGTAGCTG GGACTACAGG CACATGCCAC CACACCCGAC TAACTTTTTT GTATTTTCAG TAGAGACGGG 2320
2321 GTTTCACCAT GTTGGCCAGG CTGGTCTGGA ACTCCTGACC TCAGGTGATC TGCCCGTTTC GATCTCCCAA AGTGCTGGGA 2400
2401 TTACAGGCGT GAGCCACCGC ACCTGGCTGG GAGTTAGAGG TTTCTAATGC ATTGCAGGCA GATAGTGAAT ACCAGACACG 2480
2481 GGGCAGCTGT GATCTTTATT CTCCATCACC CCCACACAGC CCTGCCTGGG GCACACAAGG ACACTCAATA CATGCTTTTC 2560
2561 CGCTGGGCCG GTGGCTCACC CCTGTAATCC CAGCACTTTG GGAGGCCAAG GTGGGAGGAT CACTTGAGCC CAGGAGTTCA 2640
2641 ACACCAGCCT GGGCAACATA GTGAGACCCT GTCTCTACTA AAAATACAAA AATTAGCCAG GCATGGTGCC ACACACCTGT 2720
2721 GCTCTCAGCT ACTCAGGAGG CTGAGGCAGG AGGATCGCTT GAGCCCAGAA GGTCAAGGTT GCAGTGAACC ATGTTCAGGC 2800
2801 CGCTGCACTC CAGCCTGGGT GACAGAGCAA GACCCTGTTT ATAAATACAT AATGCTTTCC AAGTGATTAA ACCGACTCCC 2880

Cahier d'Exercices de Biochimie / PCEM1 Biologie Moléculaire / 5
Faculté de Médecine Pierre & Marie Curie
2881 CCCTCACCCT GCCCACCATG GCTCCAAAGA AGCATTTGTG GAGCACCTTC TGTGTGCCCC TAGGTAGCTA GATGCCTGGA 2960
2961 CGGGGTCAGA AGGACCCTGA CCCGACCTTG AACTTGTTCC ACACAGGATG CCAGGCCAAG GTGGAGCAAG CGGTGGAGAC 3040
3041 AGAGCCGGAG CCCGAGCTGC GCCAGCAGAC CGAGTGGCAG AGCGGCCAGC GCTGGGAACT GGCACTGGGT CGCTTTTGGG 3120
3121 ATTACCTGCG CTGGGTGCAG ACACTGTCTG AGCAGGTGCA GGAGGAGCTG CTCAGCTCCC AGGTCACCCA GGAACTGAGG 3200
3201 TGAGTGTCCC CATCCTGGCC CTTGACCCTC CTGGTGGGCG GCTATACCTC CCCAGGTCCA GGTTTCATTC TGCCCCTGTC 3280
3281 GCTAAGTCTT GGGGGGCCTG GGTCTCTGCT GGTTCTAGCT TCCTCTTCCC ATTTCTGACT CCTGGCTTTA GCTCTCTGGA 3360
3361 ATTCTCTCTC TCAGCTTTGT CTCTCTCTCT TCCCTTCTGA CTCAGTCTCT CACACTCGTC CTGGCTCTGT CTCTGTCCTT 3440
3441 CCCTAGCTCT TTTATATAGA GACAGAGAGA TGGGGTCTCA CTGTGTTGCC CAGGCTGGTC TTGAACTTCT GGGCTCAAGC 3520
3521 GATCCTCCCG CCTCGGCCTC CCAAAGTGCT GGGATTAGAG GCATGAGCAC CTTGCCCGGC CTCCTAGCTC CTTCTTCGTC 3600
3601 TCTGCCTCTG CCCTCTGCAT CTGCTCTCTG CATCTGTCTC TGTCTCCTTC TCTCGGCCTC TGCCCCGTTC CTTCTCTCCC 3680
3681 TCTTGGGTCT CTCTGGCTCA TCCCCATCTC GCCCGCCCCA TCCCAGCCCT TCTCCCCCGC CTCCCCACTG TGCGACACCC 3760
3761 TCCCGCCCTC TCGGCCGCAG GGCGCTGATG GACGAGACCA TGAAGGAGTT GAAGGCCTAC AAATCGGAAC TGGAGGAACA 3840
3841 ACTGACCCCG GTGGCGGAGG AGACGCGGGC ACGGCTGTCC AAGGAGCTGC AGGCGGCGCA GGCCCGGCTG GGCGCGGACA 3920
3921 TGGAGGACGT GCGCGGCCGC CTGGTGCAGT ACCGCGGCGA GGTGCAGGCC ATGCTCGGCC AGAGCACCGA GGAGCTGCGG 4000
4001 GTGCGCCTCG CCTCCCACCT GCGCAAGCTG CGTAAGCGGC TCCTCCGCGA TGCCGATGAC CTGCAGAAGC GCCTGGCAGT 4080
4081 GTACCAGGCC GGGGCCCGCG AGGGCGCCGA GCGCGGCCTC AGCGCCATCC GCGAGCGCCT GGGGCCCCTG GTGGAACAGG 4160
4161 GCCGCGTGCG GGCCGCCACT GTGGGCTCCC TGGCCGGCCA GCCGCTACAG GAGCGGGCCC AGGCCTGGGG CGAGCGGCTG 4240
4241 CGCGCGCGGA TGGAGGAGAT GGGCAGCCGG ACCCGCGACC GCCTGGACGA GGTGAAGGAG CAGGTGGCGG AGGTGCGCGC 4320
4321 CAAGCTGGAG GAGCAGGCCC AGCAGATACG CCTGCAGGCC GAGGCCTTCC AGGCCCGCCT CAAGAGCTGG TTCGAGCCCC 4400
4401 TGGTGGAAGA CATGCAGCGC CAGTGGGCCG GGCTGGTGGA GAAGGTGCAG GCTGCCGTGG GCACCAGCGC CGCCCCTGTG 4480
4481 CCCAGCGACA ATCACTGAAC GCCGAAGCCT GCAGCCATGC GACCCCACGC CACCCCGTGC CTCCTGCCTC CGCGCAGCCT 4560
4561 GCAGCGGGAG ACCCTGTCCC CGCCCCAGCC GTCCTCCTGG GGTGGACCCT AGTTTAATAA AGATTCACCA AGTTTCACGC 4640
4641 ATCTGCTGGC CTCCCCCTGT GATTTCCTCT AAGCCCCAGC CTCAGTTTCT CTTTCTGCCC ACATACTGCC ACACAATTCT 4720
4721 CAGCCCCCTC CTCTCCATCT GTGTCTGTGT GTATCTTTCT CTCTGCCCTT TTTTTTTTTT TAGACGGAGT CTGGCTCTGT 4800
4801 CACCCAGGCT AGAGTGCAGT GGCACGATCT TGGCTCACTG CAACCTCTGC CTCTTGGGTT CAAGCGATTC TGCTGCCTCA 4880
4881 GTAGCTGGGA TTACAGGCTC ACACCACCAC ACCCGGCTAA TTTTTGTATT TTTAGTAGAG ACGAGCTTTC ACCATGTTGG 4960
4961 CCAGGCAGGT CTCAAACTCC TGACCAAGTG ATCCACCCGC CGGCCTCCCA AAGTGCTGAG ATTACAGGCC TGAGCCACCA 5040
5041 TGCCCGGCCT CTGCCCCTCT TTCTTTTTTA GGGGGCAGGG AAAGGTCTCA CCCTGTCACC CGCCATCACA GCTCACTGCA 5120
5121 GCCTCCACCT CCTGGACTCA AGTGATAAGT GATCCTCCCG CCTCAGCCTT TCCAGTAGCT GAGACTACAG GCGCATACCA 5200
5201 CTAGGATTAA TTTGGGGGGG GGTGGTGTGT GTGGAGATGG GGTCTGGCTT TGTTGGCCAG GCTGATGTGG AATTCCTGGG 5280
5281 CTCAAGCGAT ACTCCCACCT TGGCCTCCTG AGTAGCTGAG ACTACTGGCT AGCACCACCA CACCCAGCTT TTTATTATTA 5360
5361 TTTGTAGAGA CAAGGTCTCA ATATGTTGCC CAGGCTAGTC TCAAACCCCT GGCTCAAGAG ATCCTCCGCC ATCGGCCTCC 5440
5441 CAAAGTGCTG GGATTCCAGG CATGGGCTCC GAGCGGCCTG CCCAACTTAA TAATATTGTT CCTAGAGTTG CACTC 5515
La séquence ci-jointe est celle du gène de l'apolipoprotéine E humaine, allèle e4. Le
dernier nucléotide de chaque ligne est numéroté sur la droite (n° de position).
3.1.1 Certaines parties de cette séquence ont été soulignées d'un trait simple; examinez
avec soin le début et la fin des séquences qui sont situées entre ces séquences
soulignées: à quoi correspondent les séquences soulignées ?
3.1.2 Quelles sont les fonctions (rôles) des protéines qui se fixent en premier sur ce
gène dans la région allant du nucléotide 975 au nucléotide 1046 ?
3.1.3 Quel est le rôle du triplet de nucléotides en 1871-1873 ?
3.1.4 Quelle est la traduction de la séquence 1847-1913 de ce gène ?
3.1.5 Le nucléotide en position 1913 est un G qui fait partie de la séquence traduite
:
quelle est sa position dans le cadre de lecture: N1, N2 ou N3 ?
3.1.6 Le nucléotide en position 3007 est un G qui fait partie de la séquence traduite
:
quelle est sa position dans le cadre de lecture: N1, N2 ou N3 ?
3.1.7 Il existe dans le domaine de l'apolipoprotéine E codé par l'exon 4 du gène deux
Arginines qui peuvent être mutées en Cystéines par une simple substitution d'un
nucléotide: quelle est à ces endroits (soulignés deux fois), la séquence du brin
sens du gène muté?
3.1.8 Quelle sera la longueur après transcription et maturation (comprenant l'addition
de 1000 AMP du côté 3'-OH) de l'ARN messager de l'apolipoprotéine E ?
3.1.9 Quel est le rôle du codon (souligné deux fois) TGA en 4496?
3.1.10 Quels sont les numéros des nucléotides de la boîte de polyadénylation ?
3.1.11 La sécrétion de la protéine hors des cellules nécessite l'hydrolyse d'un peptide
de 18 acides aminés du côté N-terminal. Quel est le rôle de ce peptide ?
3.1.12 De combien d'acides aminés se compose l'apolipoprotéine E mature ?
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
1
/
27
100%