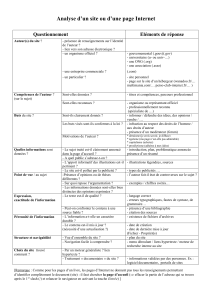
Analyse des opinions sur le web - Opinion mining

CHLOÉ CLAVEL – TELECOM-PARISTECH
Analyse des opinions sur le web
- Opinion mining -
1

Les données du Web
2
Collecte des données et
nettoyage
Analyse de données
textuelles
Analyse des graphes
de communauté (ex:
outil GePhi)
Web : sites,
forums, tweets,
blogs

Plan du cours
Introduction au TALN et à
l’analyse d’opinions
Les méthodes linguistiques et
l’analyse d’opinions
Les méthodes statistiques et la
catégorisation d’opinions
Illustration des méthodes sur
différents corpus
3

TALN : Traitement Automatique du Langage
Naturel
Domaine à la frontière de:
L’intelligence artificielle
La linguistique
L’informatique
Objectifs:
Compréhension du langage naturel : dériver du sens à partir de
données textuelles
Générer automatiquement du langage
En anglais : Natural Language Processing NLP
10/06/14
Traitements linguistiques – module PAROLE 4
https://www.youtube.com/watch?v=Ea_ytY0UDs0 Luc Steels - BREAKING THE WALL TO LIVING
ROBOTS. How Artificial Intelligence Research Tries to Build Intelligent Autonomous Systems

Les enjeux applicatifs du TAL
5
La traduction automatique
La fouille de données textuelles/Le classement des
documents/L’extraction d’information
Les correcteurs orthographiques
Les résumés automatiques
L’interaction humain-machine
La reconnaissance de la parole
La synthèse de la parole
L’analyse des opinions sur le web social
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
1
/
80
100%


![Module d`approfondissement : Analyse de données textuelles [ADT]](http://s1.studylibfr.com/store/data/003642129_1-07974612d4fcbdda6358e009ddcf62e0-300x300.png)