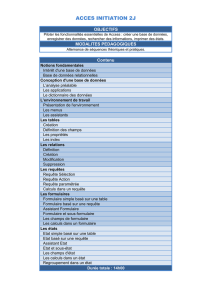
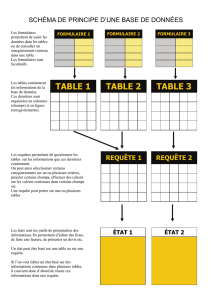
Documents textuels et ingénierie linguistique

Documents textuels et ingénierie linguistique

Thème du cours
●Montrer des techniques informatiques pour trouver, classer,
extraire l'information dans des masses de données textuelles
●Combiner des techniques « classiques » avec des techniques de
l'ingénierie linguistique
●Applications:
–recherche de documents (ex. google)
–filtrage et classification de documents (ex. antispam)
–extraction d'information (ex. qui est le president colombien ?)
–résumé automatique, traduction, ...

Cours pluridisciplinaire
●mathématique et informatique :
–algorithmique,
–formalismes,
–probabilités, ...
●linguistique :
–ressources (dictionnaires, grammaires)
–annotation, ...

Organisation
●Cours complémentaire de celui d'Eric Laporte (ingénierie
linguistique par la linguistique)
●notre cours: vision applicative avec approches hybrides
●6h de cours
●8h de TD/TP
●Projet: antispammer ?

INTRODUCTION GENERALE
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
1
/
69
100%