Réseaux neuronaux Perceptron Multi-Couche

1
J.Korczak, ULP 1
Jerzy Korczak, LSIIT, ULP
email : jjk@dpt-info.u-strasbg.fr
http://lsiit.u-strasbg.fr/afd
Réseaux neuronaux
Perceptron Multi-Couche
J.Korczak, ULP 2
R
RR
Ré
éé
éseaux neuronaux
seaux neuronauxseaux neuronaux
seaux neuronaux
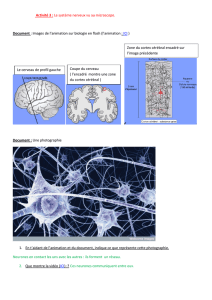
Les fondements biologiques
synapse
dendrites
soma
influx nerveux
cortex : 1011 neurones
neurone : ~104entrées
axone
J.Korczak, ULP 3
10 000 neurones
3 km fil
1mm
Signal:
action potentielle (ang.spike)
action
potential
100µm
Neurone biologique
J.Korczak, ULP 4
Cortex : les couches et les cellules
J.Korczak, ULP 5
Canaux ionique
Comportement
Populations
de neurones
Modéles
Neurones
Molecules
Signaux
Modélisation de réseaux de neurones biologiques
J.Korczak, ULP 6
Mod
ModMod
Modè
èè
èle de cellule de Purkinje
le de cellule de Purkinje le de cellule de Purkinje
le de cellule de Purkinje (
((
(Schutter 2005)
))
)
Le modèle comporte:
•32000 équations différentielles!
•8021 modèles des canaux ioniques
•19200 paramètres d’affinement
•description morphologique

2
J.Korczak, ULP 7
Histoire
HistoireHistoire
Histoire
La modélisation du neurone [McCulloch, Pitts, 1943]
• Le processus d’apprentissage [Hebb, 1949]
• PERCEPTRON [Rosenblatt,1958-1962]
Convergence d’un algorithme itératif d’adaptation de poids
• Limitations du PERPTRON [Minsky, Papert, 1969]
séparation linéaire
Problème du OU-exclusif (XOR)
• Machine de Bolzmann [Hopfield, 1982]
• Rétro-propagation - MLP [Rumelhart, Parker, Le Cun, 1985]
•Cartes topologiques auto-adaptatives [Kohonen, 80s]
J.Korczak, ULP 8
Traitement de l'information dans le cerveau
et l'ordinateur de von Neumann
Ordinateur de von Neumann Cerveau
calcul et mémoire calcul et mémoire
séparés et centralisés intégrés et distribués
programme = séquence d’instr. calcul = satisfaction de multiples
contraintes
exécution d'un sous- combinaison simultanée de
programme à la fois multiples sources d'information
un seul processeur des centaines de milliards
très rapide d'unités de calcul très lentes
J.Korczak, ULP 9
Caractéristiques des systèmes
J.Korczak, ULP 10
Séparation linéaire
x1
x2
wkx > s
wkx < s
XOR
1
1
0
?
•Un ensemble d'exemples est linéairement séparable si il existe
un classifieur linéaire qui peut tous les apprendre.
•Pour n entrées binaires, il existe 2nvecteurs d'entrées possibles,
et 22
nfonctions binaires.
J.Korczak, ULP 11
Applications
ApplicationsApplications
Applications
Reconnaissance des formes, classification
Reconnaissance/synthèse de la parole
Prévision et modélisation
Diagnostic
Compression de données
Vision, robotique, commende de véhicule, contrôle adaptatif
Nouvelles applications
• Recherche d’informations dans le Web
• Extraction d’information, veille technologique
• Multimédia (indexation)
• Data mining
J.Korczak, ULP 12
OCR : reconnaissance de caract
OCR : reconnaissance de caractOCR : reconnaissance de caract
OCR : reconnaissance de caractè
èè
ères par RN
res par RNres par RN
res par RN

3
J.Korczak, ULP 13
Qu’est-ce qu’un réseau de neurones ?
RN est un réseau d’automates finis partiellement ou totalement
connectés entre eux, en interaction locale ou globale. Il est
entièrement caractérisé par son architecture et les fonctions de
transition d’état des neurones.
Deux grands classes de RN :
• RN dont l’apprentissage est supervisé
Une méthode d’apprentissage supervisé est une méthode qui
utilise directement les connaissances d’un expert et essaye de
reproduire ces connaissances.
• RN dont l’apprentissage est non supervisé
Une méthode d’apprentissage non supervisé est une méthode qui
essaye de dériver des généralisations à partir des données, de
segmenter l’espace de données.
J.Korczak, ULP 14
R
RR
Ré
éé
éseaux neuronaux :
seaux neuronaux : seaux neuronaux :
seaux neuronaux :
‘
‘‘
‘bonnes applications
bonnes applicationsbonnes applications
bonnes applications’
’’
’
Des caractéristiques d’une bonne application :
•Problèmes très difficiles à expliciter ou à formaliser
•On dispose d’un ensemble d’exemples
•Le problème fait intervenir des données bruitées
•Le problème peut évoluer
•Le problème nécessite une grande rapidité de
traitement
•Il n’existe pas de solutions technologiques
courantes
J.Korczak, ULP 15
Le Perceptron Multi-Couche (MLP)
Le MLP est composé de couches successives : une couche
d’entrée (où sont présentées les entrées), une ou plusieurs
couches cachées, et une couche de sortie (où sont
présentées les sorties calculées par le MLP).
L’apprentissage des MLP :
- algorithme de rétro-propagation du gradient
- algorithme de gradient conjugué
- méthodes de second ordre, …
Les MLP sont des approximateurs universels.
J.Korczak, ULP 16
Réseau de neurones - MLP
couche
d ’entrée
couche de sortie
couches cachées
•Un réseau (suffisamment complexe) de neurones formels peut représenter
•n'importe quelle fonction booléenne ou n'importe quelle partition de Rn.
J.Korczak, ULP 17
Fonctionnement d’un neurone
Σ
ΣΣ
Σxi*wi
Entrées Sorties
Σ
F
Fonction d’activation (ou de transfert)
1
0
w1
w2
wi
wk
Σ
ΣΣ
Σ
Σ
ΣΣ
Σ
X1
X2
X3
Y1
Y2
Y3
J.Korczak, ULP 18
Fonction d’activation
Fonction non linéaire
- choix typiques : fonction logistique, tangente hyperbolique
F(x) = 1/(1+e-x) F(x)= tanh(x)
- propriétés importantes :
- continue, dérivable

4
J.Korczak, ULP 19
MLP : apprentissage
Principe :
• Initialisation des poids à des valeurs aléatoires
• Présentation d’un exemple
• Propagation des signaux dans le réseau
• Calcul des erreurs et propagation en sens rétrograde
• Modification des poids de connexions
Défauts :
• Paramétrage
• Lenteur
• Choix de la topologie
J.Korczak, ULP 20
Arrêt de l’apprentissage
• Critères classiques
– l’erreur passe en dessous d’un seuil
– borne sur le temps de calcul
– vitesse de progression
• Une technique de régularisation : arrêt prématuré
(early stopping)
– éviter le sur-apprentissage
– on s’arrête quand l’erreur remonte sur l’ensemble de
validation
J.Korczak, ULP 21
Problème : la sortie désirée pour un neurone caché ?
Entrées
tj: sortie désirée
xi
oiwij
…
Méthode de calcul :
1) fonction de coût : E(t)=Σp(op-tp)2
2) gradient total : w(t+1) = w(t) –λ(t) gradw(Ep(t))
3) calculer dEp/dwij
J.Korczak, ULP 22
Problème : la sortie désirée pour un neurone caché ?
dEp/dwij = (dEp/dσj)(dσj/dwij) =(dEp/dσj) yi
on pose δj= (dEp/dσj), d’où wij(t+1) = wij(t) – λ
λλ
λ(t) δ
δδ
δjyi
entrée
tj
xi
ojwjkoi
σiσjσk
ff
fwij
mais δj= (dEp/dσj)= Σk(dEp/dσk) (dσk/dσj)= Σkδk(dσk/dσj)=
= Σkδkwjk (dyk/dσj)
d’où δ
δδ
δj = 2(oj- tj) f’(σ
σσ
σj)si neurone j en sortie
δ
δδ
δj = (Σ
ΣΣ
Σkwij δ
δδ
δk) f’ (σ
σσ
σj)si neurone j en sortie
J.Korczak, ULP 23
x1
x2
x3
xn
...
t1
t2
t3
tm
...
Vecteur
d ’entrée
o1
o2
o3
...
om
R
RR
Ré
éé
étro
trotro
tro-
--
-propagation du gradient
propagation du gradientpropagation du gradient
propagation du gradient
-
-
-
-
-
yi=
Σ
wijxi
Fonction sigmoïde F(y)=1/(1+e-ky) F’(y) = F(y)(1-F(y))
E=1/2
Σ
(tk- ok)2
wij
J.Korczak, ULP 24
Exemple : Rétro-propagation du gradient (GBP)
Apprentissage
XOR
X Y XOR(X,Y)
0 0 0
0 1 1
1 0 1
1 1 0
f(netk)=1/(1+e-netk)
netj=Σ
ΣΣ
Σwijoi
oj=f(netj)
11
0,5
0,5
0
Wij=0
0
0
0
0
0 0
1
XY
bias
XOR
bias
δ
δδ
δk=(tk-ok)f’(netk)
f’(netk)=ok(1-ok)
wjk(t+1)=wjk(t)-λδ
λδλδ
λδkoj

5
J.Korczak, ULP 25
Exemple : Rétro-propagation du gradient (GBP)
Apprentissage
XOR
X Y XOR(X,Y)
0 0 0
0 1 1
1 0 1
1 1 0
δ
δδ
δh=f’(netj) Σδ
ΣδΣδ
Σδkwkj
= 0,5*(1-0,5)*0,125*0,00625= 0,000195
whx=0+0,1*0,000195*1=0,0000195
11
0,5
0,5
0
Wij=0 0
0
0
0
0 0
1
xy
bias
XOR
bias
λ=0,1
λ=0,1λ=0,1
λ=0,1
δ
δδ
δz=(1-0.5)*0,5*(1-0.5)=
=0,125
wzx(t+1)=0+0,1*0,125*1=
= 0,0125
z
h
J.Korczak, ULP 26
Apprentissage : les poids et le coefficient d’apprentissage
wzx=0,00125
λ
itération
wzy=0 0,1 25496
wzh=0,00625 0,5 3172
whx=0,0000195 3,0 391
why=0 4,0 (fails)
wzbh=0,0000195
f(net) = 0,507031
J.Korczak, ULP 27
Exemple : Rétro-propagation du gradient (GBP)
XOR
X Y XOR(X,Y)
0 0 0
0 1 1
1 0 1
1 1 0
11
0,91
0.98
0
-3,29
-4,95
-4,95
-2,76
10,9
7,1 7,1
1
XY
bias
XOR
J.Korczak, ULP 28
Exemple : Rétro-propagation du gradient (GBP)
XOR
X Y XOR
0 0 0
0 1 1
1 0 1
1 1 0
11
0,91
0,98
0
-3,29
-4,95
-4,95
-2,76
10,9
7,1 7,1
1
XY
bias
XOR
1 * 7,1
1 * -2,76
0 * 7,1
Σ
ΣΣ
Σxw = 4,34
Y=1/(1+e-Σ
ΣΣ
Σxw)
=1/(1+e-4,34)
=0,98
J.Korczak, ULP 29
Exemple : Rétro-propagation du gradient (GBP)
XOR
X Y XOR
0 0 0,08
0 1 0,91
1 0 1,00
1 1 0,10
11
0,91
0,98
0
-3,29
-4,95
-4,95
-2,76
10,9
7,1 7,1
1
XY
bias
XOR
J.Korczak, ULP 30
Axone : Exemple XOR [http://lsiit.u-strasbg.fr/afd]
 6
7
6
7
1
/
7
100%