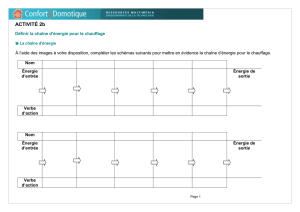
Extraction de collocations à partir de textes

⇒
⇒
⇒

?
?
IM(x, y) = log2
P(x, y)
P(x)P(y)

IM(x, y) = log2NC(x, y)
C(x)C(y)
≥

?
z=C(x, y)−E
√Eq o`u q = 1 −p
N
x C(x)
y C(y)
C(x, y y
x
S
x y
p
x p C(y)
N−C(x)
E
x y E =pC(x)S

S
z(house, y)y
 6
7
8
9
10
11
12
13
14
15
6
7
8
9
10
11
12
13
14
15
1
/
15
100%