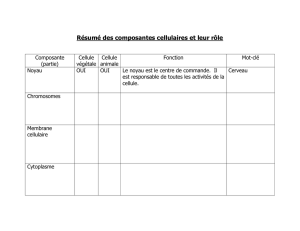
Le Noyau Linux

“livre”
2006/8/26
page xi
Préface
Durant le premier semestre de l’année 1997, nous avons donné un cours sur les systèmes d’ex-
ploitation en nous appuyant sur Linux 2.0. Notre intention était d’encourager les étudiants
à parcourir le code source. Pour parvenir à nos fins, les projets que nous leur avons confiés
consistaient à modifier le noyau et à tester ces versions remaniées. À cette occasion, nous
avons également créé des supports de cours sur certaines des fonctionnalités importantes du
noyau Linux, notamment sur la commutation et la planification des tâches.
Puis vint la première édition du Noyau Linux à la fin de l’année 2000 et pour laquelle l’aide de
notre éditeur Andy Oram d’O’Reilly nous a été très précieuse. Cet ouvrage s’intéressait à la
version 2.2 de Linux et à quelques points du futur noyau 2.4. Le succès qu’il a rencontré nous
a encouragé à continuer dans cette direction. Fin 2002, nous publiions une seconde édition
qui concernait le noyau 2.4. (La première édition française correspondait à la version 2.4 du
noyau.) Vous tenez dans vos mains la troisième édition qui traite de la version 2.6 du noyau.
Comme par le passé, nous avons parcouru des milliers de lignes de code pour essayer d’en
extirper la substantifique moelle. Nous savons aujourd’hui que le jeu en valait la chandelle.
Nous avons beaucoup appris, un savoir qui n’existe dans aucun livre, et nous espérons que
nous avons réussi à le transcrire dans les pages qui suivent.
Notre public
Toute personne manifestant de la curiosité quant à la manière dont Linux fonctionne et sur
les raisons de son efficacité trouvera ici des réponses. Après avoir lu ce livre, vous pourrez par-
courir seul les milliers de lignes de code qui constituent le noyau Linux et faire la différence
entre les structures de données cruciales et celles qui sont moins importantes. En un mot,
vous serez devenu un véritable hacker de Linux.
Notre exposé peut être assimilé à une visite guidée du noyau : y sont décrits la plupart des
structures de données significatives, beaucoup d’algorithmes et certaines astuces de program-
mation en usage dans le noyau. Des fragments de code seront fréquemment analysés ligne
par ligne. Vous devrez bien entendu disposer du code source du noyau et être prêt à passer
un temps significatif pour déchiffrer certaines fonctions qui ne seront pas complètement dé-
taillées dans cet ouvrage pour des raisons de concision.
Ce livre fournit également un aperçu utile aux personnes désireuses de connaître la manière
de concevoir un système d’exploitation moderne. Il ne s’adresse pas spécifiquement aux ad-
ministrateurs système ou aux développeurs, mais à toutes les personnes qui souhaitent com-

“livre”
2006/8/26
page xii
xii Préface
prendre comment les choses fonctionnent à l’intérieur d’un ordinateur. Comme tout guide
qui se respecte, nous essaierons de ne pas nous cantonner aux aspects superficiels. Nous pré-
senterons pour cela le contexte des fonctionnalités majeures d’un point de vue historique, ce
qui nous permettra de comprendre la raison de leur existence.
L’aspect matériel
Lorsque nous avons commencé à formaliser ce livre, nous avons dû faire face à une décision
importante : devrons-nous prendre pour référence une plateforme matérielle spécifique ou
laisser de côté les détails relatifs à un matériel particulier afin de nous concentrer sur les par-
ties purement indépendantes du matériel ?
D’autres ouvrages consacrés à l’étude du noyau Linux ont retenu cette dernière approche.
Nous avons choisi la première pour les raisons suivantes.
•Les noyaux des systèmes d’exploitation efficaces tirent parti de la quasi-totalité des fonc-
tionnalités du matériel telles que les techniques d’adressage, les mémoires caches, les ex-
ceptions du processeur, les instructions spéciales, les registres de contrôle du processeur
et ainsi de suite. Si nous voulons parvenir à vous convaincre que le noyau s’acquitte ef-
fectivement au mieux d’une tâche spécifique, il nous faut alors expliquer les fonctions
offertes par le matériel pour cela.
•Même si une grande partie du code source d’un noyau Unix est indépendant du matériel
et écrit dans le langage C, une portion, peu volumineuse mais critique, est développée en
assembleur. Une connaissance approfondie du noyau requiert donc l’étude des quelques
fragments écrits en assembleur qui communiquent avec le matériel.
Lorsque nous exposerons les fonctions liées au matériel, notre stratégie sera fort simple : nous
expliquerons rapidement les tâches qui sont totalement prises en charge par le matériel et
nous nous pencherons en détail sur celles qui nécessitent un support logiciel. Ce qui nous
intéresse ici concerne la conception du noyau plutôt que l’architecture de l’ordinateur.
L’étape suivante dans notre cheminement consistait à choisir une plateforme matérielle à
décrire. Bien que Linux supporte désormais un large choix d’architectures d’ordinateur per-
sonnel ou de stations de travail, nous avons choisi de nous intéresser aux ordinateurs très
populaires et peu onéreux que sont les compatibles IBM-PC et, par conséquent, aux les mi-
croprocesseurs 80x86 et sur quelques autres puces qui habitent ces ordinateurs personnels. Le
terme microprocesseur 80x86 sera utilisé dans les chapitres qui viennent pour faire référence
aux puces Intel 80386, 80486, Pentium, Pentium Pro, Pentium II, Pentium III et Pentium 4
ainsi qu’aux microprocesseurs compatibles. En de rares occasions, des références explicites à
certains modèles seront faites.
Une dernière décision qui nous restait à prendre concernait l’ordre dans lequel nous allions
étudier les composants du noyau. Nous avons opter pour une approche du bas vers le haut,
en commençant par traiter les sujets concernant la gestion du matériel pour terminer par
ceux qui sont indépendants de la plateforme. Ainsi, nous ferons beaucoup de références aux
microprocesseurs 80x86 dans la première partie de ce livre tandis que les parties suivantes
seront peu spécifiques au matériel. Des exceptions notables seront les chapitres 13 et 14. Dans
la pratique, suivre une démarche du bas vers le haut n’est pas aussi simple qu’elle semble l’être

“livre”
2006/8/26
page xiii
Préface xiii
car les domaines qui concernent la gestion de la mémoire, des processus et des systèmes de
fichiers font référence les uns aux autres. Quelques références à des sujets qui n’auront pas
encore été traités seront inévitables.
Chaque chapitre commencera par un aperçu théorique du sujet développé. L’aspect matériel
sera ensuite présenté suivant l’approche du bas vers le haut. Nous débuterons par la descrip-
tion des structures de données requises pour le support des fonctionnalités couvertes dans
le chapitre. La plupart du temps, nous décrirons ensuite les fonctions de bas niveau pour
terminer par celles qui offrent des fonctionnalités de niveau plus élevé. Nous terminerons
le plus souvent en expliquant comment sont pris en charge les appels systèmes réalisés par
les applications.
Niveau d’explication
Toutes architectures confondues, le code source de Linux compte plus de 14000 fichiers écrits
en langage C ou en assembleur et répartis dans plus de 1000 répertoires. Cela représente en-
viron 6 millions de lignes de code qui pèsent plus de 230 méga-octets. Il est bien entendu que
cet ouvrage ne peut en décrire qu’une faible portion. Uniquement pour vous faire une idée
de la taille du code source de Linux, sachez que la totalité du manuscrit de ce livre occupe
moins de 3 méga-octets. Il faudrait donc plus de 75 volumes de cette taille simplement pour
publier tout le code, sans même commencer à le décrire !
Aussi, nous avons dû choisir les parties à étudier. Voici une brève description de nos décisions.
•la gestion des processus et de la mémoire est décrite de manière assez détaillée ;
•nous étudions le système de fichiers virtuel (Virtual Filesystem) ainsi que les systèmes de
fichier Ext2 et Ext3 bien que beaucoup de fonctions seront simplement mentionnées
sans même que leur code ne soit examiné. Nous n’aborderons pas les autres systèmes de
fichiers supportés par Linux ;
•nous décrirons les pilotes de périphériques, qui représentent à eux seuls environ la moitié
du noyau, à partir du moment où il existe une interface avec le noyau. Mais nous ne
tenterons pas d’explorer chacun d’entre eux.
Cet ouvrage décrit la version officielle 2.6.11 du noyau Linux, elle est disponible sur le site
http://www.kernel.org.
Sachez que la version du noyau livrée avec la plupart des distributions de GNU/Linux a été
modifiée afin d’implémenter des nouvelles fonctions ou dans le but d’en améliorer l’effica-
cité. En de rares occasions, il est possible que le code source fourni par votre distribution
favorite soit bien différent de celui qui est présenté dans ce livre.
Souvent, nous montrerons des fragments du code source original remanié afin qu’il soit plus
facile à lire et à comprendre mais ainsi moins efficace. Ce sera le cas à certains endroits cri-
tiques d’un point de vue du temps d’exécution et qui sont souvent écrits avec un mélange de
langage C optimisé manuellement et de code en assembleur. Une fois encore, notre but est
de faciliter l’étude du code original.
Souvent, lorsque nous examinerons le code source du noyau, nous en viendrons finalement
à décrire beaucoup de fonctions bien connues dont les programmeurs Unix ont entendu par-
ler et pour lesquelles ils éprouvent une certaine curiosité (telles que la mémoire paginée et
partagée, les signaux, tubes, liens symboliques et autres).

“livre”
2006/8/26
page xiv
xiv Préface
Plan du livre
Afin d’en faciliter l’abord, le Chapitre 1, Introduction, présente ce que vous trouverez dans un
noyau Unix et comment Linux se place en comparaison des autres systèmes Unix usuels.
Le cœur de tout noyau Linux est la gestion de la mémoire. Le Chapitre 2, Adressage de la
mémoire, décrit les circuits des processeurs 80x86 qui permettent d’adresser les données en
mémoire et la manière dont Linux en exploitent les fonctions.
Les processus sont une abstraction fondamentale proposée par Linux et introduite dans le
Chapitre 3, Processus. Nous expliquerons également à ce moment comment chaque proces-
sus s’exécute en mode non-privilégié (User Mode) ou en mode privilégié (Kernel Mode). Les
transitions entre chacun de ces modes ne sont possibles qu’en utilisant des mécanismes du
matériel bien connus sous le nom d’interruptions ou exceptions. Tout cela est introduit dans le
Chapitre 4, Interruptions et exceptions.
En de nombreuses occasions, le noyau doit gérer un flot important d’interruptions générés
par plusieurs périphériques et processeurs. Des mécanismes de synchronisation sont néces-
saires afin que toutes ces requêtes soient traitées conjointement par le noyau. Nous étudie-
rons ces mécanismes dans le Chapitre 5, Synchronisation du noyau, pour des environnements
monoprocesseur ou multiprocesseurs.
Un type d’interruption particulier est vital afin que Linux mesure et gère correctement le
temps, plus de détails seront exposés dans le Chapitre 6, Mesure du temps.
Dans le Chapitre 7, Ordonnancement des processus, nous expliquerons comment Linux exécute,
tour à tour, chacun des processus actifs du système afin qu’ils puissent progresser dans leur
exécution.
Nous nous pencherons ensuite de nouveau sur la mémoire. Le Chapitre 8, Gestion de la mé-
moire, décrira un ensemble de techniques élaborées, nécessaires afin de gérer la ressource la
plus précieuse du système (juste après le processeur, c’est évident) : la mémoire disponible.
Cette denrée doit être distribuée entre le noyau Linux et les applications des utilisateurs. Le
Chapitre 9, Espace d’adressage des processus, vous expliquera comment le noyau fait face aux
demandes d’allocation de mémoire émises par les programmes voraces.
Le Chapitre 10, Appels système, abordera comment un processus qui s’exécute dans le mode
non-privilégié effectue des requêtes auprès du noyau tandis que le Chapitre 11, Signaux, décrit
la manière dont un processus peut envoyer des signaux de synchronisation à d’autres proces-
sus. Nous serons ensuite fin prêts à aborder un autre domaine essentiel, l’implémentation
des systèmes de fichiers par Linux. Plusieurs chapitres couvriront ce sujet. Le Chapitre 12,
Le système de fichiers virtuel, introduit le concept de couche intermédiaire qui permet l’im-
plémentation de beaucoup de systèmes de fichiers différents. Certains des fichiers de Linux
sont particuliers car ils ouvrent une porte d’accès aux périphériques matériels, le Chapitre 13,
Entrées/sorties et pilotes de périphérique, et le Chapitre 14, Pilotes de périphérique blocs, nous ex-
pliqueront comment fonctionnent ces fichiers spéciaux et les pilotes de périphériques sous-
jacents.
Un autre défi est lié au temps d’accès aux disques. Le Chapitre 15, Mémoire cache, nous mon-
trera comment un usage adroit de la mémoire vive permet de réduire les accès aux disques
afin d’améliorer considérablement les performances du système. En prenant appui sur les

“livre”
2006/8/26
page xv
Préface xv
sujets traités dans les chapitres qui précèdent, nous pourrons ensuite expliquer, dans le Cha-
pitre 16, Accès aux fichiers, le procédé qui permet aux applications d’accéder auxfichiers stan-
dard. Afin de parfaire notre étude sur la gestion de la mémoire, le Chapitre 17, Libération
des espaces mémoire, exposera les techniques employées par le noyau Linux afin de s’assurer
qu’il reste toujours susamment de mémoire disponible. Le dernier chapitre concernant les
fichiers est le Chapitre 18, Les systèmes de fichiers Ext2 et Ext3, qui décrira le système de fichiers
Linux le plus couramment utilisé, soit Ext2, et son dérivé récent Ext3.
Les deux derniers chapitres de notre pérégrination dans le cur du noyau Linux sont le Cha-
pitre 19, Communications entre processus, qui introduit les mécanismes autres que les signaux
utilisés par les processus pour communiquer, et le Chapitre 20, Exécution de programmes, qui
explique comment les applications sont démarrées.
Enfin, arrivant en dernières mais tout aussi utiles les annexes : l’Annexe A, Démarrage du sys-
tème, explique rapidement comment Linux est lancé et l’Annexe B, Modules, décrit comment
modifier la configuration du noyau actif en y ajoutant et en retirant des fonctionnalités à la
demande. L’index du code source liste tous les symboles du noyau référencés dans cet ouvrage,
vous y trouverez le nom du fichier de Linux qui contient la définition de chaque symbole
ainsi que le numéro de page qui le décrit. Il nous semble qu’il s’avérera fort utile.
Prérequis
Aucune connaissance particulière n’est requises si ce n’est quelques notions de programma-
tion en langage C et, éventuellement, la pratique d’un peu de langage assembleur.
Conventions utilisées
Les conventions typographiques suivantes ont été employées dans ce livre :
Chasse fixe
Utilisée pour imprimer le contenu de fichiers ou le résultat de l’exécution de commandes
ainsi que pour signaler des mots-clés extraits du code source.
Italique
Identifie les noms de fichiers et répertoires, les programmes et noms de commandes, les
options d’exécution, les URL et met en évidence des termes nouveaux.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
1
/
40
100%