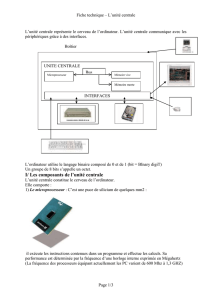
Cours d`archi ig2

BTS IG2 -Cours d’Architecture
Page 1 sur 55
BTS INFORMATIQUE DE GESTION
COURS D’ARCHITECTURE
2è ANNEE

BTS IG2 -Cours d’Architecture
Page 2 sur 55
Chapitre 1 La Numération 3
Chapitre 2 Le Codage 5
Chapitre 3 Le codage des nombres flottants 8
Chapitre 4 Algèbre de BOOLE 10
Chapitre 5 La Logique Combinatoire 15
Chapitre 6 La Logique Programmée 20
Chapitre 7 Les Mémoires 24
Chapitre 8 La Gestion des E/S 31
Chapitre 9 La Transmission des données 36
Chapitre 10 Les puces RISC 47
Chapitre 11 Les ordinateurs multiprocesseurs 49
Chapitre 12 Le Microprocesseur 52

BTS IG2 -Cours d’Architecture
Page 3 sur 55
Chapitre 1 - La Numération
1 Les systèmes de numération
La numération est la façon d'énoncer ou d'écrire des nombres (Numérations arabe et romaine). C'est aussi un
système qui organise la suite des nombres en séries hiérarchisées. Il existe une multitude de systèmes de
numération (appelé aussi base), en fait, autant qu'il y a de nombres. Nous allons nous intéresser à quatre d'entre
eux, ceux utilisés par les logiciels.
A Le système décimal
C'est le système le plus utilisé et j'espère qu'il n'a plus de secrets pour vous !!!
Il va nous servir d'exemple pour expliquer les 3 autres. Il est basé sur le nombre 10, 10 étant la base du système
décimal. Les chiffres 0, 1, .....,8, 9, soit 10 caractères au total sont utilisés pour la représentation des nombres.
Un nombre est subdivisé en puissances de 10, que l'on énonce en allant de la plus élevée à la plus faible.
Exemple :
On note en indice la base du système de numération dans lequel le nombre est représenté. Pour le nombre
décimal 159, chaque chiffre à ce qu'on appel un rang. Le chiffre 1 a le rang des centaines, on dit que son "poids "
est de cent. Pour le nombre 1995, le chiffre 1 est appelé le chiffre de poids fort MSB et le 5 le chiffre de poids
faible LSB.
B Le système binaire
C'est le système que l'on devrait tout le temps utilisé, mais il est peu pratique dans la vie courante. Par contre en
informatique il est le plus utilisé. En effet un ordinateur n'a que 2 possibilités OUI ou NON, VRAI ou FAUX
(l'homme ayant la 3ème possibilité " je ne sais pas "). Ces 2 possibilités sont représentées par les chiffres 0 et 1,
soit 2 caractères au total, utilisés pour la représentation des nombres. Le système binaire est donc basé sur le
chiffre 2. Comme en décimal, un nombre est subdivisé en puissances de 2, que l'on énonce en allant de la plus
élevée à la plus faible.
Exemple :
En base 2, on ne parle plus de chiffres mais de bits (en anglais Binary Digit), et on dit bit de poids le plus fort
(MSB Most Significant Bit) et bit de poids le plus faible (LSB Less Significant Bit)
Le comptage en binaire ne diffère pas, sur le principe, du comptage en décimal. Lorsque la capacité numérique
d'une position est dépassée, on obtient une retenue se reportant sur la position suivante ; ceci arrive lorsque l'on
dépasse le chiffre 1 dans une position du système binaire et le chiffre 9 dans une position du système décimal.
C Le système octal
C'est un système qui découle du système binaire. Il est constitué de 8 caractères, 0, 1, à 7. Il est surtout utilisé
dans les systèmes d'exploitations tels que Unix pour les droits sur les fichers, répertoires etc... (voir cours SE).
D Le système hexadécimal
On a vu lors de l'étude du système binaire que les nombres devenaient vite très longs. Ce système binaire est
surtout utilisé en électronique, automatique, mécanique, les informaticiens utilisent plus facilement le système
hexadécimal.
Les chiffres 0, 1, .....,8, 9, A, B, C, D, E et F soit 16 caractères au total sont utilisés pour la représentation des
nombres.
A 10, B 11, C 12, D 13, E 14 et F 15
Un nombre est subdivisé en puissances de 16, que l'on énonce en allant de la plus élevée à la plus faible.

BTS IG2 -Cours d’Architecture
Page 4 sur 55
Exemple :
La base 16 est surtout utilisée dans les plans mémoire.
2. La conversion
Cela consiste à passer d'une base à une autre.
Base 10 Base 2 : Il est intéressant de savoir passer d'une base 2 à une base 10 et vice versa. Il existe
différentes méthodes, la plus simple est d'utiliser tout bêtement votre chère calculatrice.
Base 16 Base 2 : Pour ce qui est de la conversion de base 2 en base 16 et vice versa, il suffit : de 2 vers 16, de
regrouper les bits 4 par 4 (en commençant par les LSB !) et de convertir.
exemple : 01 1100 1001 0011(2) 1C93(h)
de 16 vers 2, d'éclater les chiffres et de former des paquets de 4 bits et de convertir.
exemple : 1B34D(h) 0001 1011 0011 0100 1101(2)
Voilà l'avantage de la base 16 sur la base 10 en informatique.
3. Les nombres négatifs (signés)
Dans une case mémoire, on ne peut entrer que 1 ou 0, c'est la seule chose que comprend un ordinateur. Pour
représenter les nombres négatifs, il a fallu trouver une solution. La solution la plus immédiate consiste à réserver
un digit binaire (bit) pour le signe, les autres bits représentant la valeur absolue du nombre.
La convention qui prévaut consiste à mettre le MSB à 0 pour représenter un nombre positif et à 1 pour un
nombre négatif. On parle de données ou nombres signés quand on utilise cette convention.
Exemple : sur 8 bits en nombres non signés on va de 0 à 255(10) alors qu'en nombres signés on va de -128
1000 000 à +127 1111 1111
Nous allons voir comment obtenir ces conversions et leurs explications.
Le complément à 1 (restreint) :
Le complément restreint d'un nombre binaire s'obtient par simple inversion des valeurs des bits constituant ce
nombre.
Ainsi en considérant le nombre signé 10010 représentant le nombre -2(10)
il aura pour complément restreint 01101 soit 13(10) ce qui ne représente pas grand chose.
Le complément à 2 (vrai) :
Le complément vrai d'un nombre binaire s'obtient, en inversant les valeurs des bits formant le nombre et en
rajoutant 1.
exemple : 0110 devient 1010 et 0000 devient bien 0000 (essayez).
Admettons que nous ayons des nombres sur 4 bits.
0100 représente soit 4 ,
et son complément à 2 :
1100 représente soit -4.
Le codage sur 8 bits ne permet plus d'obtenir des nombres compris entre 0 et 255 mais entre -128 et +127.
4. Les opérations arithmétiques en système binaire :
L'addition : Il suffit de savoir additionner et de se rappeler que 1+1, ne fait pas 2 mais 10(2) !
La soustraction en complément à 2 : Pour faire des soustractions en binaire, il faut convertir le nombre à
soustraire en complément à 2 et faire une addition.
exemple sur 8 bits: 21 - 63 = -42
63 00111111 donc -63 11000000+1=11000001
donc 21 - 63 0001 0101 + 1100 0001 = 1101 0110 (-128+64+16+4+2) = -42
La multiplication : aucune difficulté, ce ne sont que des additions voir le TD
La division : aucune difficulté, ce ne sont que des soustractions voir le TD
Les nouveaux multiples : Dans le système décimal, on parle de kilo, méga...,ces multiples existent aussi en
bases 2 et 16 mais non pas les mêmes valeurs
1 kilo 210 = 1 024 unités
1 méga 220 = 1024 * 1024 = 1 048 576 unités
1 giga 230 = 1024 * 1024 * 1024 = 1 073 741 824 unités
1 téra 240 = 1024 * 1024 * 1024 * 1024 = 1 099 511 627 776 unités

BTS IG2 -Cours d’Architecture
Page 5 sur 55
Chapitre 2 - Le Codage
1. La représentation des nombres :
A Le code Gray ou code binaire réfléchi
Pour l'instant on a vu le code binaire naturel.
Le code gray est surtout utilisé pour la visualisation d'informations, ou pour la conversion de grandeurs
analogiques (par exemple la position angulaire d'un arbre en rotation).
exemple : on veut repérer la position d'une pièce mobile en utilisant des capteurs de réflexion.
Il y a un risque d'erreur dans le code binaire naturel. les marques sombres correspondent à une faible lumière
réfléchie ou à un 1 logique. Lors des transissions 1 à 2,3 à 4,4 à 5....il y a un risque de voir apparaître à la sortie
du dispositif, des combinaisons fausses. Par exemple, pour passer de la position 1 à la position 2, on peut obtenir
les combinaisons parasites 0 ou 3.
20
21
22
23
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
On est donc conduit à utiliser un code différent où seul un bit change quand on passe d'une position à une autre,
c'est le code Gray ou code binaire réfléchi. Ce code à la particularité de n'avoir qu'un bit qui change à la fois. Il
est utilisé dans les roues codeuses
20
21
22
23
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
B Le code BCD
Abréviation de Binary Coded Decimal en anglais et DCB Décimal Codé Binaire. Ce code cherche à concilier les
avantages du système décimal et du code binaire. Il est surtout utilisé pour l'affichage de données décimales
(calculatrices).
A chaque chiffre du système décimal, on fait correspondre un mot binaire de quatre bits.
Pour coder un nombre décimal en BCD, on va coder séparément chaque chiffre du nombre de base dix en
Binaire.
Exemple : 1985 Û 0001 1001 1000 0101(BCD)
Attention :
- le nombre codé en BCD ne correspond pas au nombre décimal converti en binaire naturel.
- le codage décimal BCD est simple, mais il impossible de faire des opérations mathématiques avec !
2. La représentation des caractères
Le code EBCDIC : Extended Binary Coded Decimal Interchange, ce code est utilisé
principalement par IBM. Il peut être parfois assimilé à un code 9 bits quand il est fait usage
d'une clé d'imparité, (bit supplémentaire destiné à contrôler la validité de l'octet associé).
Le code ANSI : Certains logiciels utilisent la norme ANSI (American National Standard
Institute) qui reprend en grande partie le code ASCII. Ce code propose des extensions
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
1
/
55
100%