Biochimie du 24 novembre 2003

1
Biochimie du 24 novembre 2003.
D. Organisation génomique.
Dans les virus ou bactérie, le mode d’organisation est plus simplifié car dans ces organismes
il y a très peu d’ADN perdu donc tous les gènes sont bout à bout et l’organisation des gènes
est différente car chez les microorganismes il n’y a pas de séquences introniques.
Dans nos cellules c’est un génome diploide formé de 2 jeux de chromosomes et chez l’homme
il y a 22 autosomes et 2 chromosomes sexuels. Lorsqu’on dessine un chromosome on met des
bandes correspondantes à des structures particulières. Sur les chromosomes il y a un
étranglement : la région centromérique avec un bras court et un bras long. Les deux
extremités sont les télomères et ces régions ont des sorts particuliers au moment de la
réplication. En dessinant un baton on représente un chromosome en mettant un rond figurant
le centromère. Le chromosome c’est un très grand double brin d’ADN et les deux brins sont
anti parallèles.
En fonction de la position du centromère, on définit un bras court qui est le bras P et le bras
long est le bras Q. Donc si on s’intéresse au chromosome 1, c’est 1q qui veut dire
chromosome 1 sur le bras long. Un positionnement plus fin « 1q2.1 » signifie que cette région
est sur le bras long et situé au niveau de la deuxième bande et à l’intérieur de ces bandes il y a
des sous bandes donc ici sous bande 1 de la bande 2. La numérotation est toujours du
centromère vers le télomère donc si une région 1q3 est plus éloigné que 1q2. Cela permet de
positionner grossièrement une région chromosomique qui est dit « un locus ». Quand
plusieurs régions c’est un loci. Si on envisage une paire de chromosome 1, sachant que les
deux chromosomes sont identiques (maternelle et paternelle) ils définissent 2 allèles : ce
qu’on appel région allèlique est la région identique que l’on doit retrouver sur le chromosome
de la même paire donc ici locus 1q2.1 sera définit par l’allèle numéro 1 d’un des
chromosomes numéro 1 et la même région situé au même niveau sur le deuxième
chromosome de la même paire c’est l’allèle numéro2. Donc normalement toujours un système
à deux allèles sauf dans le cas des chromosomes sexuels car un seul X et un seul Y chez les
garçons. Ceci est le cas de région diallèlique mais les deux chromosomes sont
« théoriquement » identiques mais il peut y avoir des microdifférences entre chacun des deux
chromosomes ce qui permet de les différencier.
Si on prends une région chromosomique : soit on trouve la même séquence et c’est deux
allèles identiques soit il y a une toute petite différence par exemple une base G est remplacé
par T donc couple T/A au même niveau sur le deuxième chromosome donc ça définit 2 allèles
et c’est ce qu’on appel une variation qui peut être soit une mutation soit simplement un
polymorphisme = changement d’ADN sans conséquence ; ici c’est un système diallèlique,
c’est le cas le plus fréquent mais il existe des régions formées de répétitions c’est à dire que
dans un autre endroit du chromosome on a une séquence de type CAGCAGCAG : des
répétitions de motifs et ce nombre de répétitions est variable et là on peut avoir des systèmes
polyallèliques où il y a plus de 2 possibilités. Par exemple sur le premier chromosome il va y
avoir 5 répétitions ce qui définit le premier allèle mais si on regarde la même région sur le
2ème chromosome il n’y a que 4 répétitions donc il y a une différence entre les deux, c’est
toujours un système diallèlique (soit 4 soit 5). Mais si on étant cette analyse en regardant au
niveau de ces mêmes régions chromosomiques chez d’autres individus on s’aperçoit que chez
certains individus au lieu d’avoir 4 ou 5 c’est 3 c’est à dire qu’il y a plusieurs possibilités au
niveau de cette région c’est à dire possibilité d’avoir x allèles donc on parle de polyallèlisme.
Chez un individu il n’y a que 2 possibilités car que 2 chromosomes mais dans une population
générale il peut y avoir plusieurs allèles possibles au niveau de la même région.

2
Les gènes : séquences d’ADN qui portent l’information qui sera exprimé ne sont pas contigus
dans la majorité, c’est à dire les gènes ne sont pas mis bout à bout donc on va définir des
régions gèniques et entre les gènes il y aura des régions intergèniques.
La majorité des gènes servent de support d’information pour la synthèse des protéines :
transcrit en ARNm traduit en protéine. Un certain nombre de gène jamais traduit en protéine :
ce sont les gènes transcrit pour former les ARNt qui jouent un rôle pour amener les acides
aminés au moment de la traduction. Les ARN ribosomaux qui ne seront pas traduit, resteront
en ARN, s’associent avec une protéine pour former les ribosomes donc la machinerie qui fait
la synthèse des protéines. Donc un gène n’est pas forcément traduit et peut s’arrêter au niveau
d’ADN donc.
La plupart des gènes qui vont codés pour des protéines sont des gènes en copie unique c’est à
dire que si on considère un génome haploide (moitié des chromosomes) ils seront présent à
une seule unité mais si diploide évidemment 2 copies. Donc la plupart des gènes qui donnent
les protéines : 2 copies par cellules alors que les gènes qui permettent de synthétiser les ARNt
et ARNr sont présents à l’état de multicopie c’est à dire qu’il y a plusieurs centaines de copies
de gènes pour ARNr parce qu’on a besoin de beaucoup d’ARNr. C’est aussi le cas pour des
protéines comme les histones qui ont un rôle dans le compactage de l’ADN : on a besoin
d’une telle quantité quand la cellule se divise qu’il faut assurer une production abondante en
peu de temps donc plusieurs gènes d’histones.
Si les gènes codant pour les ARNt (30) et ARNr (4 types de gènes pour 4 ARNr différents)
ont une taille assez constante par contre pour les ARNm il y a une très grande diversité c’est à
dire qu’on va avoir des gènes de petites tailles, des gènes plus grand (insuline 400pb), et des
gènes énormes comme par exemple pour le gène codant pour CFTR fait 250000 pb et celui
codant pour la dystrophine dont la modification entraine la myopathie de Duchens a un gène
énorme de 2400000pb. Donc palette énorme pour la taille des gènes qui sont le reflet de la
taille des protéines.
Chez les eucaryotes supérieurs (homme), les gènes sont organisés sous forme de mosaique. Si
on prends un gène donné, tout le message génétique ne sera pas retrouvé au niveau de la
protéine donc il y a aura eu un trie. Effectivement dans les gènes il y a des séquences
exprimées retrouvés au niveau des protéines, ce sont les exons et entre les exons il y a régions
éliminées au cours de l’expression : ce sont des introns.
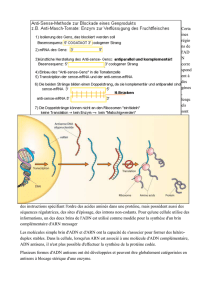
Y a t’il des motifs qui définissent les frontières entre les exons, les introns ?
Les bornes : nucléotides situés à l’extremité d’un intron et au début de l’autre intron suivant
sont toujours les mêmes ce qui a permit de définir une borne accepteur qui commencera
toujours par A/G et un site donneur qui a toujours un G et un T. Et lorsqu’on a une séquence
d’ADN inconnue on fait des prédictions de présence d’introns et d’exons.
L’organisation en mosaique est très variable donc on peut pas prédir à l’avance combien il y
aura d’exons, combien il y aura d’exons, quelle sera la taille de ces exons, chaque gène est un
cas particulier. Le gène de l’interféron alpha fait 600pb et est formé par 1 seul exon et pas
d’intron, tout est exprimé mais il y a des systèmes plus complexes : le gène de la dystrophine
est divisé en 79 exons donc c’est une vrai petite mosaique très morcelée et ce nombre d’exons
n’est pas fonction de la taille car on connaît un gène d’un récepteur : la ryanodine qui est plus
petit que le gène de la dystrophine (700000pb) a 106 exons donc pas de prédictions possibles
en voyant la taille du gène.
Dans la bactérie il y a 6000 gènes, chez l’homme 30000 donc seulement 5 fois plus de gènes
mais pourtant 1000 fois plus d’ADN ce qui veut dire qu’il y a une organisation différente : en
particulier cette structuration exon intron qui allonge la taille du gène et il y a de très
nombreuses régions intergéniques c’est à dire des morceaux d’ADN qui n’ont pas
d’expression. Dans un génome humain : 30 % de cet ADN va être utilisé pour former les
gènes et dans ceux ci seulement ¼ va réellement être codant c’est à dire va être exprimé sous

3
forme de protéines donc à peine 10% de l’ADN présent dans les cellules n’est exprimé sous
forme de protéines. A quoi servent les 90% restant ?
-Au niveau des 30% qui forme le gène, une partie est sous forme d’intron (qui ne code pas
pour des protéines) et il y a des pseudo gènes c’est à dire des gènes non exprimés car ont
subit au cours de l’évolution une activation et ils sont incomplet de telle sorte qu’ils sont
présent mais ne peuvent pas s’exprimer ; et à l’intérieur des exons il y a des séquences qui ne
seront pas traduites donc tout cela fait que dans un gène il y a 75% de l’ADN qui va se
retrouvé sous une forme non exprimé en protéine.
-Les 70 autres % qui correspondent à de l’ADN entre les gènes : nommé ADN poubelle
auparavant mais actuellement on montre que dans ces régions il y a des zones de régulations
importantes. Dans ces régions d’ADN extra génique il y a 2 grandes catégories d’ADN :
l’ADN forme de séquences uniques très peu répéttés c’est à dire que ça va être les séquences
retrouvées qu’une fois et qui représente ¼ de l’ADN extra gènique. La major partie de cet
ADN extra génique est formé d’ADN répétitif : répétitions divisées en deux : les répétitions
en tandem organisés les une à la suite des autres (CAGCAGCAG) et les répétitions dispersés
à travers tout le génôme.
1- l’ADN répété dispersé c’est à dire répétitions dispercés à travers le génome : 2 grandes
familles, les SINE (short, court élément nucléotides dispercés répétitivement) et les LINE
(plus long).
-SINE : 300 pb répéttés 900000 fois dispercés sur les différents chromosomes. Ces
motifs de 300 pb sont appelés séquences alu car ce sont des séquences reconnues par un
enzyme de coupure particulier obtenu à partir d’une bactérie Alu. On pense que ces copies se
sont accumulées par rétrotranspositions (cours suivant), c’est à dire ce sont des copies qui
étaient présentes à 1 ou 2 exemplaires au début mais se sont accumulés par copies internes ce
qui explique leurs grands nombres et leurs similarités.
-LINE :
-LINE-1 : nombre de copies un peu plus faible, 5000. Séquences plus longues
(6-7kpb), comportent 2 ORF c’est à dire 2 « cadres ouvert de lecture » qui est une séquence
d’ADN qui potentiellement peu coder pour une protéine (on ne sait pas quelle protéine donc
c’est un cadre potentiel). Un de ces ORF code pour une rétrotransposable qui permet la
multiplication de ces codons.
-THE-1 : un peu plus cours avec 2Kpb mais nombres de copies environ
identiques.
SINE ou LINE sont dispercés sans localisation préférentielle, on en retrouve sur tous les
chromosomes et à n’importe quelle endroit d’un chromosome donc pas de région ciblée.
2- L’ADN répété en tandem : Là il y a une juxtaposition, les unes à côté des autres. Il y a 3
grandes familles : satellites, minisatellites et microsatellites. Ce terme est en fonction de la
taille respective de chacune de ces répétitions.
-Satellites : Essentiellement localisés au niveau centromérique, répétitions de 100
milles à quelques millions de pb. Différents types d’ADN satellites : certain ont une fonction
connue. L’ADN alphoide ou CENP-B a un rôle important au niveau de l’accrochage du
chromosome sur le fuseau mitotique. L’ADN satellite 1,2,3 n’a pas une nature ou intérêt
connu mais c’est à ce niveau là qu’on a montré que des délétions à ce niveau là vient
perturber l’expression de certain gène donc il y a peu être un lien entre cet ADN répété et
l’expression de certains gènes.
-Minisatellites : Répétitions plus modérés, 100 à 20000 pb et ils ont une localisation
préférentielle aux extremités des chromosomes à une position sous télomérique. Ces
minisatellites sont de 2 espèces différentes : les séquences tel (télomères) sont des motifs chez
l’homme simples (CCCCAA) répéttés plusieurs dizaines de fois aux extremités télomériques
et on verra leurs importances fondamentales pour la réplication des extremités des

4
chromosomes. La deuxième classe c’est les séquences variables VNTR (répétition en tandem
de longueur variables) qui ont une importance pas pour la cellule mais pour le médecin légiste
car c’est ces répétitions dont le nombre peu varier entre chacun des 2 chromosomes d’une
même paire et dont le nombre d’allèles est très important dans la population générale, ce sont
ces répétitions en médecine légale utilisés pour réaliser les empruntes génétiques (on verra
comment ça marche).
-Microsatellites : répétitions de motifs s’étendent sur des distances assez courtes : 100
à 400pb donc chaine encore plus petite et les motifs répéttés sont simples car de type
CACACA ou CAGCAGCAG donc répétitions simples qui n’ont pas de localisation définits,
nombreuses (50000 répertoriés actuellement) sur toutes les régions chromosomiques et qui
ont trouvés un intérêt pour le généticien car permettent de localiser les différents gènes et
éventuellement pour trouver les gènes associés aux maladies.
Donc ces différents motifs d’ADN répéttés sont intéressant à différents niveau : soit pour le
généticien en biologie moléculaire ou pour la cellule en remplissant une fonction particulière.
II/ Réplication et maintenance du matériel génétique.
Tout se qu’on a observé chez bactérie a été transposés chez les eucaryotes sans trop de
variations. Lorsque Watson et Crick en 1953 ont proposés cette structure en double hélice, ils
écrivaient que cette structure suggérait en elle même un possible mécanisme du matériel
génétique. Il y avait 2 hypothèses possibles : soit c’est une réplication conservative c’est à
dire un mécanisme partant de cette molécule double brin, permet d’obtenir deux molécules
identiques mais une étant une molécule parentale dans son intégrité mais l’autre étant une
molécule néosynthétisé en totalité. La deuxième hypothèse envisageable était celui d’un
mécanisme semi conservatif c’est à dire qu’on obtenait 2 molécules filles d’ADN identiques
mais avec la moitié de la molécule parentale dans chacune des molécules filles.
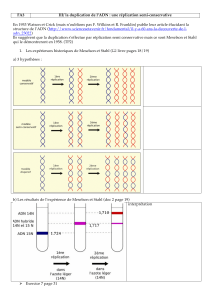
-Démonstration de l’hypothèse semi conservative : c’est basé sur les propriétés de densité de
l’ADN. Ils ont pris des bactéries qu’ils ont mis dans un milieu de culture qui contenait comme
source d’azote de l’azote N15 (lourd) ce qui veut dire que les bactéries l’incorporait dans leurs
molécules d’ADN en particulier. Au bout d’un temps tout l’ADN était marqué par l’azote
N15 et ils ont extraits l’ADN de ces bactéries, ont mesurés la densité en faisant une
ultracentrifugation sur gradient de densité c’est à dire que dans un tube on met des couches
successives de chlorure de cesium donc réactif chimique à densités différentes et ensuite on
dépose à la surface la solution d’ADN, on fait tourner à haute vitesse et l’ADN s’arrête à la
région qui correspond à sa propre densité. Ensuite ils ont pris ces bactéries pour les mettre à
pousser dans un milieu contenant l’azote normal N14 donc ces bactéries continuent à pousser
en incorporant maintenant du N14 donc auront à la fois N15 et N14 quand on réplique le
matériel génétique. Après un temps de génération, ils refont la même expérience et
maintenant il s’aperçoivent qu’ils obtiennent une bande d’ADN à un niveau de densité
différent du précédent donc densité plus légère. Donc effectivement ce n’est pas une
réplication conservatif sinon on aurait 2 bandes, une correspondant à l’ADN lourd et la
nouvelle correspond à l’ADN légé. Le fait qu’on ait un ADN mixte veut dire que l’ADN est
formé à la fois de N14 et N15 et ils ont pu montrés que cette hypothèse était bonne en
refaisant encore une réplication donc reforment de l’ADN avec du N14 mais maintenant ils
obtiennent une bande d’ADN légé qui a incorporé l’ADN 14.
En résumé dans la première étape on a de l’ADN lourd à une certaine densité, dans la
deuxième expérience l’ADN s’est dupliqué et a formé deux molécules filles formés de deux
brins : un légé et un lourd donc on a une densité intermédiaire. Mais si ceci se réplique le brin
légé va formé un ADN légé entièrement et le brin lourd va s’associé à un brin légé donc
redonne la population intermédiaire. Donc cette réplication est semi conservative.

5
A. La réplication chez les procaryotes.
Dans un chromosome bactérien circulaire, on obtient des images où on voit la séparation des
2 brins d’ADN enroulés les uns autour des autres pour former le chromosome. Donc on
observe la duplication du chromosome bactérien pour donner à la fin deux nouvelles
molécules d’ADN qui vont être dans chacune des nouvelles bactéries formé par la division
bactérienne. On a parlé d’un « œil de réplication » : cette structure où l’ADN s’ouvre en 2
pour commencer sa réplication. Chez les bactéries, la réplication se développe à partir de
l’origine de réplication du chromosome qu’on appel « ori C » mais si elle démarre en un seul
point, la réplication est bidirectionelle donc se fait dans les deux sens en même temps donc
ouverture du double brin puis deux systèmes enzymatiques remontant le brin d’ADN chacun
en sens opposé formant des fourches de réplications (forme d’un Y) donc deux fourches de
replication travaillant en même temps pour remonter et répliquer l’ADN poru former deux
nouvelles molécules d’ADN. L’intérêt c’est d’aller plus vite. Chez les bactérie la réplication
est rapide, se fait en 20/100 minutes chez EC bactérie.
On a une séquence de terminaison qui permet à ces deux complexes enzymatiques de se
décrocher et ensuite il y a des enzymes qui coupent un des deux brins pour permettre la
séparation de ces deux anneaux. Ces systèmes de replication sont des cibles naturelles pour
des médicaments (antibiotique ou anticancéreux) car si on peut empecher une cellule de se
diviser on peut la tuer de manière sélective. L’origine de réplication correspond à une
séquence d’ADN particulière qui est reconnu par des protéines spécifiques qui s’ariment à
l’ADN grâce à la forme en sillon de l’ADN B.
2. Phase d’initiation : La 1ère étape c’est la reconnaissance de la séquence ori C par des
protéines ADN A. Et la fixation de plusieurs sous unités ADN A sur la séquence ori C induit
un repliement, un bouclage un peu plus loin de la séquence d’ADN qui va permettre à
d’autres protéines de venir se fixer formant le primosome et ces protéines ont des propriétés
interessantes : certaines sont des hélicases donc permettent de dérouler l’ADN (l’ouvrir),
d’autres ont des propriétés de type primase important pour la synthèse de l’amorce de
réplication. Ces protéine s’assemblent pour former ce primosome et comme en même temps
les deux brins sont ouverts ils sont devenus relativement fragile et pour empecher qu’ils se
recollent il y a des protéines SSB (protéines de fixation du simple brin) qui vont se mettre sur
ces deux brins séparés. Cette phase d’initiation étant terminé, l’enzyme de copie entre en
action : c’est l’ADN polymérase (polymérase est un enzyme capable de copier) qui synthètise
le complémentaire de chacun des 2 brins donc on duplique le matériel à l’identique. La 1ère
étape dans la synthèse de ce nouveau brin d’ADN c’est de faire un brin d’ARN c’est à dire
que ce qui va servir à l’ADN polymérase pour copier l’ADN ça va être une amorce d’ARN.
En effet l’ADN polymérase est incapable de copier l’ADN si on lui a pas montré comment il
faut faire. Le premier double brin va être un brin d’ADN + en face un petit morceau d’ARN
synthétisé par cette enzyme primase.
Les polymérases ne peuvent travailler que dans un sens 5’-3’ donc deux mécanismes
différents pour chacun des deux brins. Ce mécanisme est détaillé dans :
3. l’élongation : On retrouve le double brin avec des enzymes qui l’aident à se dérouler :
hélicases, topoisomérases ; il y a les SSB pour stabiliser chacun des brins et la première étape
consiste à synthétiser une petite amorce d’ARN pour la DNA primase qui lorsqu’il y aura un
A sur le brin d’ADN mettra en face un U mais ici ça sera un ribonucléotide. Cette primase fait
donc un petit morceau de 10/15 nucléotides, ce qui sert d’amorce car on mime un double brin.
A partir de cela l’ADN polymérase peut se fixer sur cet embryon de double brin puis elle va
remonter le brin matrice pour à chaque base mettre son complémentaire donc elle constitué le
nouveau brin. Mais l’ADN polymérase ne fonctionne qu’en allant de l’extremité 5’ vers
l’extremité 3’. Ceci explique qu’il y a deux mécanismes différents suivant qu’on a à faire au
bras avancé ou le bras retardé.
 6
7
8
6
7
8
1
/
8
100%