commentaires - ASI @ INSA Rouen

PESQUET Guillaume
LECOQ Jean-Christophe
DEA ICSV
Février 2000
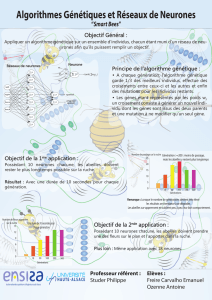
Algorithmes d’apprentissage rapide pour les réseaux neuronaux multi-couches.
( Fast Training Algorithms for Multi-layer Neural Nets, Richard P.Brent, Fellow, IEEE )
Problème : L’algorithme d’apprentissage pour réseaux neuronaux multi-couches ( perceptron multi-couches ) par
rétro-propagation ( back-propagation ) est très long et nécessite des choix arbitraires sur les neurones, et sur le
nombre de couches. Cet article présente un autre algorithme qui lui est plus rapide.
L’idée principale de cet algorithme est de construire un arbre de décision puis de le simuler avec un réseau
neuronaux. Les classifieurs par arbre de décision ont été implanté avec succès dans de nombreuses applications.
L’idée d’utiliser des arbres de décision avec des réseaux neuronaux n’est pas nouvelle.
Avec un ensemble d’apprentissage S constitué de points d’apprentissage, on peut construire l’arbre de décision
T, arbre binaire dont les nœuds non terminaux correspondent à des tests hyperplans de la forme :
n
jjj xaa 1
00
( 1 )
, et dont les feuilles correspondent aux classes des objets à classer ( au nombre de K ).
Un tel arbre classifie correctement tous les points de l’ensemble d’apprentissage S, et partitionne l’espace des
caractéristiques Rn des points x par un ensemble de régions convexes V, bornées par des hyperplans. La
détermination des l’hyperplans H qui séparent l ‘ensemble des points d’apprentissage S en sous-ensembles, se
fait de manière optimale. L’optimalité est définie par des critères précis. L’auteur en développe un.
Il existe une correspondance naturelle entre l’arbre de décision T et un réseau neuronaux, qui possède t neurones
dans la première couche cachée, t+1 dans la seconde, et au plus K neurones de sortie. Les fonctions de seuillage
des neurones sont des fonctions très restrictives ( step functions ).
- Les neurones de la première couche correspondent directement aux nœuds non terminaux de T.
Chacun évalue un test de la forme (1) ; avec des poids a1,…,an et un seuillage de –a0.
- Les neurones de la seconde couche correspondent à un chemin entre la racine de T et une feuille.
- Chaque neurone de sortie correspond à une classe unique.
La difficulté de mise en œuvre de cet algorithme réside dans les deux cas suivants :
- Dans l’approximation du critère par une fonction continue, afin que les algorithmes d’optimisation continus
soient applicables. L’auteur conseille une version appropriée de l’algorithme du gradient conjugué, qui peut
être implémenté avec peu d’efforts, et qui est généralement rapide. Une méthode plus sophistiquée comme
un « quasi » algorithme de Newton pourrait aussi être utilisée, et serait probablement encore plus rapide que
le gradient conjugué.
- Dans le fait que les données pouvant être bruitées, il peut devenir nécessaire de réduire l’arbre par fusion de
certains de ses nœuds.
Analyse de la complexité :
Pour deux raisons, cette méthode est plus rapide que celle utilisant la rétro-propagation :
- Le critère définit par l’auteur est un problème à n degrés de liberté, alors que la rétro-propagation doit tenter
de trouver au moins nt paramètres simultanément, avec t le nombre de neurones dans la première couche du
réseau.
- Comme la construction de l’arbre de décision se fait de manière récursive, la partie ayant rapport avec
l’apprentissage devient de plus en plus petite. Uniquement la détermination de l’hyperplan correspondant à
la racine de l’arbre, nécessite d’avoir l’ensemble d’apprentissage S en entier.
Résultats des tests :
L’algorithme a été testé dans le cas de problèmes artificiels comme le problème de parité, dans des problèmes
réels comme la reconnaissance de la voix,… .Ils ont été implantés en Pascal sous VAX 11/750 sous VMS et
Turbo Pascal sous IBM PC.
Les résultats sont aussi bons pour les performances de reconnaissances que ceux obtenus en utilisant la rétro-
propagation, mais sont bien meilleurs concernant le processus d’apprentissage.
1
/
1
100%