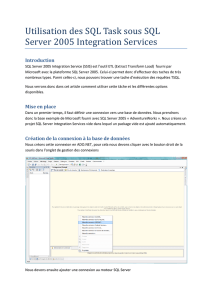
Guide de fonctionnement et de paramétrage de

Guide de fonctionnement et de paramétrage
de SSIS
Article technique SQL Server
Auteurs : Alexei Khalyako, Carla Sabotta, Silvano Coriani, Sreedhar Pelluru, Steve Howard
Relecteurs techniques : Cindy Gross, David Pless, Mark Simms, Daniel Sol
Date de publication : décembre 2012
S'applique à : SQL Server 2012, Base de données SQL Windows Azure
Résumé : SQL Server Integration Services (SSIS) peut être utilisé efficacement comme outil pour
déplacer des données dans et à partir de la Base de données SQL Windows Azure, dans le cadre de la
solution d'extraction, de transformation et de chargement (ETL, Extract, Transform and Load) et de la
solution de déplacement des données. SSIS peut être utilisé efficacement pour déplacer des données
entre les sources et les destinations dans le cloud, et dans un scénario hybride entre le cloud et le site.
Ce document présente les meilleures pratiques SSIS pour les sources et les destinations du cloud,
aborde la planification de projets SSIS si le projet se trouve entièrement dans le cloud ou comporte
des déplacements de données hybrides et vous guide tout au long d'un exemple d'optimisation des
performances sur un déplacement hybride en mettant à l'échelle le déplacement des données.

2
Copyright
Ce document est fourni « en l'état ». Les informations et les opinions exprimées dans ce document,
y compris les adresses URL et les autres références à des sites Internet, peuvent faire l'objet de
modifications sans préavis. Vous assumez tous les risques liés à son utilisation.
Certains exemples mentionnés dans ce document ne sont fournis qu'à titre indicatif et sont fictifs.
Toute ressemblance ou similitude avec des éléments réels est purement fortuite et involontaire.
Ce document ne vous concède aucun droit de propriété intellectuelle portant sur les produits Microsoft.
Vous pouvez copier et utiliser ce document à titre de référence pour un usage interne.
© 2011 Microsoft. Tous droits réservés.

3
Sommaire
Introduction .................................................................................................................................................. 5
Création de projet ......................................................................................................................................... 5
Portée du problème et description ........................................................................................................... 5
Pour quelles raisons le déplacement des données est-il essentiel dans Windows Azure ? ........................ 6
Scénarios clés de déplacement des données ........................................................................................... 7
Chargement initial et migration des données du site vers le cloud ..................................................... 7
Déplacement des données générées dans le cloud vers des systèmes sur site ................................... 8
Déplacement de données entre les services de cloud computing ....................................................... 9
Outils existants, services et solutions ....................................................................................................... 9
SQL Server Integration Services (SSIS) ................................................................................................ 10
Classe SqlBulkCopy dans ADO.NET ..................................................................................................... 11
Programme de copie en bloc (BCP.EXE) ............................................................................................. 12
Stockage Windows Azure (objets blob et files d'attente). .................................................................. 12
Options de conception et d'implémentation .......................................................................................... 13
Concevoir et implémenter une architecture équilibrée ..................................................................... 14
Éléments à prendre en considération pour les types de données ..................................................... 15
Empaquetage et déploiement de solution ............................................................................................. 15
Créer des solutions portables ............................................................................................................. 16
Distribution des packages et des composants de code ...................................................................... 16
Base de données SQL Windows Azure comme destination de déplacement des données ............... 18
Considérations sur l'architecture ................................................................................................................ 19
Conception pour un redémarrage sans perte de progression dans le pipeline ..................................... 19
Principe de base ...................................................................................................................................... 19
Exemple avec une seule destination ................................................................................................... 20
Exemple avec plusieurs destinations ...................................................................................................... 26
Autres conseils pour le redémarrage ...................................................................................................... 28
Conception pour nouvelle tentative sans intervention manuelle .......................................................... 30
Incorporation de nouvelle tentative ....................................................................................................... 31

4
Options de réglage des performances SSIS ................................................................................................ 35
Réglage des paramètres réseau .............................................................................................................. 35
Paramètres réseau .............................................................................................................................. 36
Remarque : lorsque vous modifiez les paramètres de votre carte d'interface réseau de façon
à utiliser les trames Jumbo, vérifiez que l'infrastructure réseau prend en charge ce type de trame.
Taille des paquets ............................................................................................................................... 36
Paramètres de package SSIS ................................................................................................................... 37
Considérations spéciales relatives aux données BLOB ....................................................................... 39
Utilisation des nouvelles fonctionnalités de SSIS 2012 pour analyser les performances sur un
système distribué .................................................................................................................................... 41
Enregistrer les statistiques de performances ..................................................................................... 42
Afficher les statistiques d'exécution ................................................................................................... 43
Analyser le flux de données ................................................................................................................ 49
Conclusion ................................................................................................................................................... 54

5
Introduction
SQL Server Integration Services (SSIS) est un outil efficace pour déplacer des données dans et à partir de
Base de données SQL Windows Azure, dans le cadre de la solution d'extraction, de transformation et de
chargement (ETL, Extract, Transform and Load) ou de la solution de déplacement des données
lorsqu'aucune transformation n'est nécessaire. SSIS est efficace pour diverses sources et destinations si
elles sont toutes dans le cloud, toutes sur site, ou combinées dans une solution hybride. Ce document
présente les meilleures pratiques SSIS pour les sources et les destinations du cloud, aborde la
planification de projets SSIS si le projet se trouve entièrement dans le cloud ou comporte des
déplacements de données hybrides et vous guide tout au long d'un exemple d'optimisation des
performances sur un déplacement hybride en mettant à l'échelle le déplacement des données.
Création de projet
Les projets qui déplacent des données entre le cloud et les banques de données sur site peuvent
impliquer divers processus dans différentes solutions. Il existe souvent plusieurs parties commençant
par le remplissage initial de la destination, qui peut accepter des données d'un autre système ou d'une
autre plateforme, via des opérations de maintenance, telles que le rééquilibrage des datasets parmi le
nombre variable de partitions et se poursuivant probablement par des opérations de données en bloc
ou des actualisations périodiques. La création de projet et les hypothèses sous-jacentes diffèrent
souvent pour une solution portant sur des données dans le cloud par rapport à un environnement
traditionnel de déplacement des données entièrement sur site. Nombre d'enseignements, d'expériences
et de pratiques s'appliquent toujours, mais des modifications sont nécessaires pour adapter les
différences comme le fait que votre environnement n'est plus autonome et complètement sous votre
contrôle, car vous effectuez un déplacement vers un pool partagé de ressources de base. Ces différences
nécessitent une approche plus équilibrée et plus évolutive en vue d'une réussite.
Portée du problème et description
Pour les deux solutions natives conçues depuis le début pour le cloud et pour les solutions migrées, les
données doivent être déplacée dans les deux sens. Cela se produit généralement dans plusieurs phases
du cycle de vie des applications. Les phases comprennent les tests de préproduction, le chargement
initial de données, la synchronisation successive des données entre les données générées dans le cloud
et les bases de données sur site d'origine, ainsi que les instantanés de données récurrents provenant du
cloud transmis à d'autres systèmes sur site (par exemple des entrepôts de données).
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
1
/
55
100%