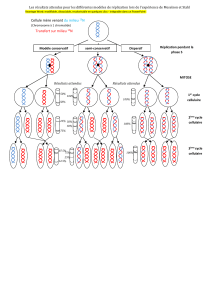
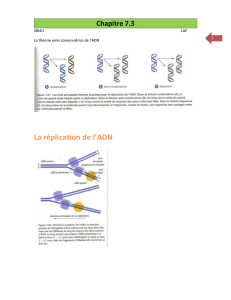
Vers la Réplication Universelle

République Algérienne Démocratique et Populaire
MINISTERE DE L’ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE SCIENTIFIQUE
UNIVERSITE D’ORAN ES-SENIA
FACULTE DES SCIENCES
DEPARTEMENT INFORMATIQUE
THÈSE
PRESENTEE PAR
M
Mr
rA
Al
li
iB
BE
EL
LK
KA
AC
CE
EM
MI
I
Pour obtenir le Diplôme de Magistère
Spécialité : Informatique
THEME
BASES DE DONNEES
Date de Soutenance : 11 juin 2008
Composition du Jury :
Président : P
Pr
r.
.D
D.
.B
Be
en
nh
ha
am
ma
am
mo
ou
uc
ch
h
Examinateurs : D
Dr
r.
.S
S.
.N
Na
ai
it
tB
Ba
ah
hl
lo
ou
ul
l
P
Pr
r.
.H
H.
.H
Ha
af
ff
fa
af
f
D
Dr
r.
.M
M.
.O
Ou
ua
al
li
i
Directeur de Thèse : P
Pr
r.
.M
M.
.K
K.
.R
Ra
ah
hm
mo
ou
un
ni
i
TITRE
V
Ve
er
rs
sl
la
aR
Ré
ép
pl
li
ic
ca
at
ti
io
on
nU
Un
ni
iv
ve
er
rs
se
el
ll
le
e


˜REMERCIEMENTS ™
Mes premiers remerciements vont aux membres du jury :
Monsieur Benhamamouche Djillali, Professeur au département d’informatique – faculté
des sciences Es-Sénia Oran pour l’honneur qu’il me fait de présider ce jury.
Monsieur Haffaf Hafid, Professeur au département d’informatique – faculté des
sciences Es-Sénia Oran d’avoir bien voulu apporter son jugement sur cette thèse. Je tiens à lui
exprimer toute ma gratitude pour l’intérêt qu’il porte à mon travail.
Melle Nait Bahloul Safia, Maître de conférences au département d’informatique –
faculté des sciences Es-Sénia Oran qui me fait honneur de juger mon travail.
Monsieur Ouali Mohamed, Chargé de cours au département d’informatique – faculté
des sciences Es-Sénia Oran, qui me fait l’honneur de participer à ce jury. Je le remercie
également pour l’aide, les conseils et la confiance qu’il m’a apportés.
Monsieur Rahmouni Mustapha Kamel professeur au département d’informatique –
faculté des sciences Es-Sénia Oran, qui m’a encadré. Je lui suis reconnaissant pour sa
disponibilité, ses conseils et sa gentillesse dont il a fait preuve. Je ne saurai jamais lui
exprimer toute ma gratitude pour avoir été mon encadreur, mais aussi une personne sur
laquelle j’ai toujours pu compter.
Outre les membres du jury, mes remerciements vont a :
Mademoiselle Bendida Nacera, pour la disponibilité et l’efficacité dont elle a fait preuve.
Monsieur Izza Rabah et Fatmi Mohamed pour leur soutien.
Melle Zegai Imène pour sa disponibilité.
Enfin, je n’oublierai pas mes familles, en particulier
— Maman, pour s’être occupée de moi et qui m’a permis de conquérir le monde
adulte.
— Mafemme et mes enfants pour l’amour et la fierté qu’ils éprouvent envers moi.
N’oubliez pas je serai toujours la pour vous.

L
L’
’i
in
nf
fo
or
rm
ma
at
ti
iq
qu
ue
ec
c’
’e
es
st
tg
gé
én
ni
ia
al
l…
……
……
…
M
Ma
ai
is
sq
qu
ua
an
nd
dç
ça
af
fo
on
nc
ct
ti
io
on
nn
ne
e.
.

 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
1
/
106
100%