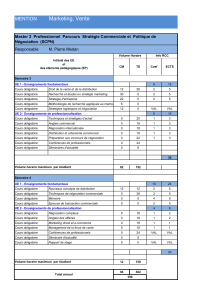
1. FICHIERS
Stocker les données dans des fichiers pour pouvoir les utiliser plus
tard.
C distingue 2 catégories de fichiers : fichiers standards et fichiers
systèmes.
On distingue : fichiers de textes et fichiers binaires.
Fichiers binaires : fichiers de nombres, ils ne sont pas listables.
Fichiers textes ou ASCII sont listables, le dernier octet de ces
fichiers est EOF.
La plupart des fonctions ou primitives permettant la manipulation
des fichiers sont rangés dans la bibliothèque standard string.h.
1

1.1. Définition et propriétés
Un fichier est un ensemble structuré de données stocké sur un support externe.
Un fichier séquentiel est représenté séquentiellement par la suite ordonnée de ses
éléments, notée : <x1, x2, x3,…,xn>.
Propriétés de fichiers séquentiels :
-les fichiers se trouvent en état d’écriture ou bien en état de lecture.
-On accède uniquement à un seul enregistrement se trouvant en face de la tête de L/ E.
-Après chaque accès, la tête de L/ E est déplacée derrière la donnée lue en dernier lieu.
-Un fichier peut être vide.
Un sous-fichier est la restriction d’un fichier f à un intervalle P (suite d’éléments
consécutifs). P est un ensemble fini totalement ordonné.
Ex : f= <5, 7, 59, 67, -1, 0, 18> alors <5, 7, 59> et <67, -1, 0, 18> sont des sous-
fichiers de f. Par contre, <5, 59, 18> n’est pas un sous-fichier.
Tout fichier peut être schématisé par un ruban défilant devant une tête de L/ E.
Elément accessible ou élément courant est l’ élément en face de la tête de L/ E.
Un fichier étant une suite finie, on introduit une marque sur le ruban notée -| (fin de
fichier).
2

tête de lecture/ écriture
sens de défilement
x1
x2
x3
x4
….
xn
-|
-----f- -----------------------f+----------------
L’élément courant (x3) permet, par définition, de
décomposer un fichier en deux sous-fichiers : f = f- || f+
Où f- est le sous-fichier déjà lu et f+ est le sous-fichier
qui reste à lire. L’élément courant est le premier élément
de f+.
Dans cet exemple : f- = <x1, x2>, f+ = <x3,…,xn>,
l’élément courant est x4.
Notation f— est définie par : f- = f--|| val.
f— est le fichier f- avant exécution de l’action : lire(f,val)
3

1.2. Actions primitives d’accès
Elles donnent un modèle du comportement dynamique d’un fichier.
1.2.1. Déclaration
Etapes pour traiter un fichier :
-déclarer un pointeur de type FILE*,
- affecter l’adresse retournée par fopen àce pointeur,
- employer le pointeur àla place du nom du fichier dans toutes les
instructions de lecture ou d’écriture,
-libérer le pointeur àla fin du traitement par fclose.
1.2.2. Primitives d’accès
Avant de créer ou de lire un fichier, nous devons l’ouvrir.
Après avoir terminé la manipulation du fichier, nous devons le fermer.
4

a) Ouvrir un fichier séquentiel
FILE * fopen(char *nom, char *mode) ;
On passe 2 chaînes de caractères :
nom : celui figurant sur le disque, par exemple toto.dat.
mode :rlecture seule ;
wécriture seule, destruction de l’ancienne si elle existe.
a+lecture et écriture d’un fichier existant (mise àjour), pas de
création d’une nouvelle version, le pointeur est positionné à la fin du
fichier.
b) Créer un fichier séquentiel
int fprintf(FILE *f, char * format, liste d’expression) ;
Retourne EOF en cas d’erreur.
exemple : fprintf(f, %s\n, il fait beau); elle crée un fichier.
Avant de lire un fichier on doit l’ouvrir en lecture.
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
1
/
57
100%