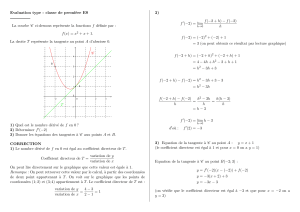
Analyse Bidimensionnelle : Variables et Méthodes Statistiques
Telechargé par
atktaou abdellatif

1
Chapitre I
ANALYSE BIDIMENSIONNELLE
L'analyse bidimensionnelle ou bivariée consiste à étudier conjointement deux
variables. L'objet est de quantifier la relation entre deux ou plusieurs variables
principal, une telle étude essaie de mettre en évidence une éventuelle liaison
statistique qui peut exister entre les deux variables de manière à ce qu’on puisse
expliquer l’une par l’autre.
La mise en évidence permet aussi de spécifier la nature et l’intensité d’une telle
relation.
Dans le cas quantitative on parle d’ajustement ou de régression et de corrélation
Dans le cas qualitative, on parle de tableau de contingence de test de chi-deux,
de coefficient d’association et de corrélation de spearman.
La recherche de combinaison entre deux variables dépend donc de la nature des
variables ; s’agit t’il de variables quantitatives, de variables qualitatives
nominales ou de variables qualitatives ordinales.
Il est évident quelque soit la nature des variables, et quelque soit la nature de la
méthode choisie ; l’objectif et de tirer des conclusions concrètes en relation avec
le problème étudié, un tel problème est fixé au préalable.
I. Combinaison de deux variables qualitatives nominales
Le croisement de deux variables qualitatives nominales définit un tableau de
contingence où les lignes correspondent aux modalités de la variable 1 mise en
lignes et les colonnes correspondent aux modalités de la variables 2 mise en
colonnes. A l'intersection de la ligne i et de la colonne j on trouve nij le nombre
d'individus ayant simultanément la modalité i de la variable 1 et la modalité j de
la variable 2.
Exemple : Soit un échantillon de 240 personnes. Deux variables nominales ont
été relevées : - Sexe (deux modalités)
- Lieu d'achat du dentifrice (trois modalités)
Pharmacie Ailleurs NSP ni.
Masculin 30 90 0 120
Féminin 60 40 20 120
n.j 90 130 20 240

2
A partir d'un tableau de contingence on peut définir un tableau de fréquences
obtenu en divisant chaque case par l'effectif total n.
soit fij = nij / n
On définit aussi :
f
i. = Σj f ij Fréquences marginales en lignes
f
.j = Σi f ij Fréquences marginales en colonnes
f
.. = Σj f .j = Σi f i. = 1
La lecture de ce tableau de fréquences permet d'avoir une idée sur la distribution
de l'échantillon sur les deux variables statistiques.
L'analyse numérique effectuée sur un tel tableau vise la mesure de
l'indépendance entre les deux variables X et Y. Cette mesure est donnée par le χ2
qui teste l'existence d'une liaison statistique significative entre les deux
variables.
(n ij - T ij)2
Calcul du χ2 : χ2 = Σ ---------------
T
ij
Les Tij sont les fréquences théoriques calculées sous l'hypothèse d'indépendance
entre les deux variables.
Dans les cas de l'exemple étudié, celles-ci sont données dans le tableau suivant :
Pharmacie Ailleurs NSP Total
Masculin 45 65 10 120
Féminin 45 65 10 120
Total 90 130 20 240
Application numérique : χ2 = 49, 24
Cette valeur est à comparer avec une valeur théorique donnée par la table de la
loi du Χ2 en fonction du nombre de degrés de liberté ddl et du risque d'erreur
qu'on est prés à tolérer. Le nombre de degrés de liberté est ddl = (L - 1)(C - 1).
Dans ce cas ddl = 2; et pour un risque de 5% la valeur critique du χ2critique = 5,99
Comme la valeur calculée est supérieure à la valeur critique, l'hypothèse de
l'indépendance est donc rejetée au risque de 5%. En définitive, le lieu d'achat de

3
dentifrice ne peut être considéré comme totalement indépendant du sexe de
l'acheteur.
On peut mesurer le degré de dépendance ou d'association entre les deux
variables grâce au coefficient d'association C :
2
2
Cn
χ
χ
=
+
Ce coefficient, s'il est toujours nul en cas d'indépendance, il prend dans le cas
d'association parfaite une valeur maximale en fonction des dimensions du
tableau de contingence. Un extrait de la table de ces valeurs maximales est
donné ci-après :
Dimensions du tableau C max Dimensions du tableau C max
2 x 2 0,707 3 x 4 0,786
2 x3 0,685 3 x 5 0,810
2 x 4 0,730 4 x 4 0,866
2 x 5 0,752 4 x 5 0,863
3 x 3 0,816 4 x 6 0,877
Pour notre exemple le Cmax est de 0,685. Pour ramener notre coefficient
d'association sur un intervalle [0;1], on prend sa valeur normalisée 0,4126/0,685
= 0,60. Ce résultat indique une association moyennement importante entre les
deux variables.
III- Combinaison de deux variables qualitatives ordinales

4
Une telle combinaison donne lieu bien évidemment à un tableau de contingence
et la liaison entre les deux variables peut être mesurée par le Χ2. Mais le
caractère ordinale des deux variables peut être pris en considération grâce au
coefficient de Spearman. Ce coefficient donne une idée sur le degré
d’association entre les deux variables définies par des rangs.
Exemple : Sur un échantillon de 24 individus nous avons posé deux questions :
1- Classez par ordre d’importance décroissante les trois qualités suivantes :
Goût Texture, consistance Caractéristiques médicales et d’hygiène
2- Pour vous une pâte dentifrice est :
Inutile Utile Très utile Indispensable.
Pour calculer le coefficient de corrélation de Spearman il faut ordonner les 24
réponses en fonction des deux variables.
Soit le tableau condensé des deux variables :
Numéro Goût Utilité
1 3 1
2 2 2
3 1 1
4 3 1
5 2 1
6 3 1
7 1 2
8 2 1
9 1 1
10 2 1
11 1 2
12 1 3
13 1 3
14 2 2
15 1 -1
16 3 3
17 2 3
18 1 2
19 2 1
20 2 2
21 3 3
22 3 3
23 1 2
24 3 2

5
Pour ordonner les 24 réponses selon le goût et l’utilité il faut résoudre le
problème des ex-aequo. Les neufs réponses qui classent le goût en premier
auront un rang égal à :
1+2+3+4+5+6+7+8+9 45
--------------------------- = ----- = 5
9 9
Ainsi le tableau des classements est le suivant :
Numéro Classemen
t selon le
goût
Classement
selon l’utilité
d i d i2
1 21 19 2 4
2 13.5 10.5 3 9
3 5 19 14 196
4 21 19 2 4
5 13.5 19 5.5 30.25
6 21 19 2 4
7 5 10.5 5.5 30.25
8 13.5 19 5.5 30.25
9 5 19 14 196
10 13.5 19 5.5 30.25
11 5 10.5 5.5 30.25
12 5 3.5 1.5 2.25
13 5 3.5 1.5 2.25
14 13.5 10.5 3 9
15 5 24 19 361
16 21 3.5 17.5 306.25
17 13.5 3.5 10 100
18 5 10.5 5.5 30.25
19 13.5 19 5.5 30.25
20 13.5 10.5 3 9
21 21 3.5 17.5 306.25
22 21 3.5 17.5 306.25
23 5 10.5 5.5 30.25
24 21 10.5 10.5 110.25
2167.5
Le coefficient de Spearman est donné par :
6 Σ d i2
r = 1 - ------------------- = 0,06
n (n
2 – 1)
 6
7
8
9
10
11
12
13
14
6
7
8
9
10
11
12
13
14
1
/
14
100%