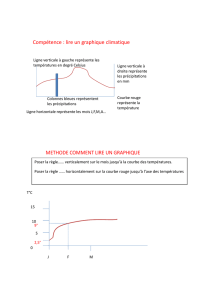
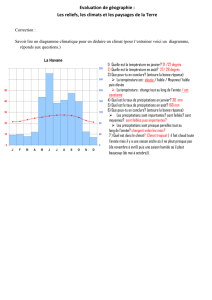
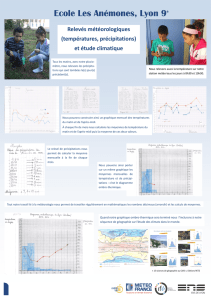
Prédiction des précipitations par chaîne de Markov à Java Ouest
Telechargé par
dandrianarimbola

Données sur les précipitations à Java Ouest en utilisant l'exploration de
données
Série de conférences IOP : Sciences de la terre et de l'environnement
ARTICLE - ACCÈS LIBRE
Une application de la chaîne de Markov pour
la prédiction de l'approche
Pour citer cet article : A Azizah et al 2019 IOP Conf. Ser : Earth Environ. Sci. 303 012026
Consultez l'article en ligne pour connaître les mises à jour et les améliorations.
Vous pouvez également
aimer
- Méthode analytique sur la fiabilité des
données pluviométriques du radar
polarimétrique en bande X
N A Hasan, M Goto et K Miyamoto
- Évaluation des données CCTV pour
l'estimation des conditions de pluie
Sinta Berliana Sipayung, Lilik Slamet, Edy
Maryadi et al.
- Approche par impulsion rectangulaire de
Bartlett Lewis (BLRP) avec procédure
d'ajustement proportionnel dans la
méthode de désagrégation des
précipitations dans le laboratoire
d'hydrologie de la station pluviale de
l'université de Brawijaya
Novita Putri Kurnia Dewi et Suci Astutik
Abonnez-vous à DeepL Pro pour traduire des fichiers plus volumineux.
Visitez www.DeepL.com/propour en savoir plus.

Ce contenu a été téléchargé depuis l'adresse IP 41.77.17.9 le 18/03/2022 à 05:49.

Conférence internationale sur la météorologie tropicale et les sciences
atmosphériques
IOP Publishing
IOP Conf. Series : Science de la terre et de l'environnement 303 (2019)
012026
doi:10.1088/1755-1315/303/1/012026
Une application de la chaîne de Markov pour prédire les
données sur les précipitations à Java Ouest en utilisant une
approche d'exploration de données.
A Azizah1 , R WElastika1 , A Nur Falah2 , B N Ruchjana2 et A S Abdullah3
1Étudiant en master au département de mathématiques de l'Universitas Padjadjaran.
2Département de mathématiques, Universitas Padjadjaran
3Département d'informatique, Universitas Padjadjaran
annisa17056@mail.unpad.ac.id
Résumé. Le modèle de chaîne de Markov est un processus stochastique permettant de
déterminer la probabilité de transition d'un espace d'état en fonction d'un état précédent. Nous
pouvons utiliser une distribution stationnaire du modèle de chaîne de Markov de premier ordre
pour déterminer la probabilité à long terme des phénomènes pluvieux. Les données sur les
précipitations dans la région de Java Ouest sont importantes, car nous disposons de nombreuses
données sur les précipitations provenant de nombreuses villes et régences, à la fois dans les
observations spatiales et temporelles. En outre, dans cet article, nous démontrons une
application de la chaîne de Markov en utilisant une approche d'exploration de données pour
obtenir la connaissance comme un modèle pour la description et la prédiction des données de
précipitations mensuelles dans les saisons humides décembre-janvier-février (DJF) en utilisant
la méthode de découverte de connaissances dans les bases de données (KDD) par le
prétraitement, le processus d'exploration de données et le post-traitement. Nous simulons les
données de précipitations mensuelles de l'année 1981 à 2017 en utilisant des espaces à quatre
états : faible (0), moyen (1), élevé (2) et très élevé (4). Le résultat de la chaîne de Markov
montre que la probabilité d'occurrence des phénomènes pluvieux pour les quatre espaces d'état
est : faible (22,62 %), moyenne (24,86 %), élevée (25,46 %) et très élevée (27,05 %). Cela
signifie que la région de Java Ouest aura, à long terme, une probabilité de précipitations très
élevée.
Mots-clés : Chaîne de Markov, Distribution stationnaire, Data Mining, Pluie.
1. Introduction
L'île de Java est l'île avec la plus grande population en Indonésie et fait divers secteurs de
développement des centres sur là. Java est également la plus grande île affectée par les phénomènes
climatiques par rapport aux autres îles d'Indonésie, si nous prédisons les données de précipitations
dans des endroits non observés, nous obtiendrons des données de précipitations avec un modèle
similaire aux endroits observés en tant que voisins [1]. Les précipitations sont la hauteur de l'eau de
pluie qui s'accumule dans un endroit plat, sans s'évaporer, sans pénétrer et sans s'écouler. 1 millimètre
de pluie, ce qui signifie que dans une zone solide de mètres carrés, un endroit plat est retenu jusqu'à un
millimètre d'eau ou peut contenir un litre ou 1000 ml d'eau [2].
Dans l'ouest de Java, les précipitations sont considérées comme l'une des principales contraintes
des plans et des décisions politiques en matière d'agriculture en raison de la position de l'ouest de Java
comme l'un des centres de l'alimentation basée sur la production de paddy dans la régence de
Karawang. Il soutient les objectifs de développement durable pour couvrir les questions de
développement social et économique, notamment la pauvreté, la faim, la santé, le réchauffement
climatique, l'eau, etc. Les précipitations sont la partie la plus importante des tropiques qui influencent
la production de paddy à Java Ouest. Sur cette base, il est nécessaire de disposer d'une méthode de
prédiction assez précise, en particulier pour les précipitations de la province de Java Ouest, car Java
Ouest est l'une des régions où le secteur agricole est le plus important [3].

Conférence internationale sur la météorologie tropicale et les sciences
atmosphériques
IOP Publishing
IOP Conf. Series : Science de la terre et de l'environnement 303 (2019)
012026
doi:10.1088/1755-1315/303/1/012026
La quantité de pluie qui se produit à ce moment-là pourrait avoir été influencée par la quantité de
pluie une fois auparavant, et la quantité de pluie dans le futur peut être affectée par la pluie actuelle,
etc. Ce phénomène est un exemple concret de l'événement de la chaîne de Markov qui est une méthode
de modélisation en
Le contenu de cet ouvrage peut être utilisé selon les termes de la licence Creative Commons Attribution 3.0. Toute distribution
ultérieure
de ce travail doit maintenir l'attribution à l'auteur ou aux auteurs et le titre du travail, la citation du journal et le DOI.
Publié sous licence par IOP Publishing Ltd1

Conférence internationale sur la météorologie tropicale et les sciences
atmosphériques
IOP Publishing
IOP Conf. Series : Science de la terre et de l'environnement 303 (2019)
012026
doi:10.1088/1755-1315/303/1/012026
2
processus stochastiques [4]. Le modèle de chaîne de Markov est utilisé pour aider à estimer les
changements qui peuvent se produire dans le futur, où les changements sont représentés dans des
variables dynamiques à certains moments. La chaîne de Markov a été inventée par Andrey Andreyev
Markov (1856-1922) [5]. On dit d'un processus stochastique qu'il comprend la chaîne de Markov s'il
remplit les propriétés de Markov (propriété markovienne). Les propriétés de Markov stipulent que la
probabilité d'un événement futur, avec des événements passés et des événements présents connus, ne
dépend pas des événements passés et ne dépend que des événements présents [4, 6].
La chaîne de Markov est généralement classée en deux catégories, à savoir la chaîne de Markov à
indice de paramètre discret et la chaîne de Markov à indice de paramètre continu. On dit que la chaîne
de Markov est un indice de paramètre discret si l'état de changement se produit avec un intervalle de
temps discret fixe. En revanche, la chaîne de Markov est dite à paramètre continu si l'état de
changement se produit avec un intervalle de temps continu [7]. Les données relatives aux
précipitations sont une série de données temporelles qui indiquent le mouvement de l'état dans un
intervalle de temps discret fixe. La prévision des précipitations dans le futur est nécessaire pour
anticiper la prévention si une forte intensité de pluie se produit pendant une longue période. En outre,
elle indique que nous devons prendre en compte les autres phénomènes qui peuvent contribuer de
manière significative à l'augmentation de l'intensité des précipitations [8]. En outre, dans cet article,
une analyse d'une grande base de données de précipitations provenant de 27 districts/villes a été
réalisée en utilisant la distribution stationnaire de la chaîne de Markov, puis utilisée pour prédire les
précipitations dans l'ouest de Java en se basant sur une approche d'exploration de données utilisant la
méthode KDD.
2. Méthode
2.1. Processus stochastiques
Un processus stochastique {(), ∈ } est une collection de variables aléatoires. Autrement dit, pour
chaque dans l'ensemble d'indices , () est une variable aléatoire. Si le paramètre temporel est un
ensemble dénombrable = {0,1,2, ... }, le processus
{(), = 0,1,2, ... } est appelé un processus stochastique à temps discret, et si est un continuum, le
processus
{(), ≥ 0} est appelé un processus stochastique continu. Pour un processus stochastique {(), ∈
}, un ensemble de toutes les valeurs de () est appelé un espace d'états [9, 10].
2.2. Concept de base des chaînes de Markov
Un mathématicien russe, Markov, a introduit le concept de processus dans lequel une séquence ou une
chaîne d'états discrets dans le temps pour lesquels la probabilité de transition d'un état à un état donné
dans l'étape suivante de la chaîne dépend de la condition pendant l'étape précédente [11]. Une chaîne
de Markov du premier ordre est un processus stochastique ayant la propriété que la probabilité des
événements futurs ne dépend que de l'événement présent, en d'autres termes :
(+1 = |1 = 1, 2 = 2, ... , = ) = (+1 = | = ) (1)
Pour tous les états 1 , 2 , ... , et tous ≥ 0, un tel processus stochastique est appelé chaîne de
Markov [7, 12].
2.3. Temps discret de la chaîne de Markov
Supposons que {(), = 0,1,2, ... } est un processus stochastique avec un indice de paramètre discret
et un espace d'état = 0,1,2, ... sauf indication contraire. Si
{\i1D44B↩( + 1) = ||(0) = 0, (1) = 1, ... , ( - 1)
= -1, () = } = {( + 1)} = |() = 1} = (2)
pour tous les 0, 1, ... , -1, , et , alors le processus est appelé une chaîne de Markov à temps discret,
et est appelé une probabilité de transition. La valeur est appelée probabilité de transition
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
/
20
100%