Analyse LR : Techniques d'analyse syntaxique ascendante
Telechargé par
Fatiha Ait BOURHOU

111
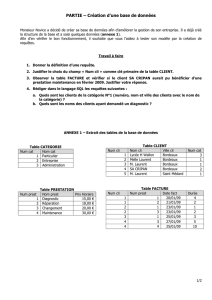
LR Parsing Techniques
1
Analyse Syntaxique ascendante

17/05/2016 2
Sujets
• Préfixes viables.
• Éléments LR(0).
• AFD LR(0) pour reconnaître les préfixes viables.
• Analyseur LR(0).

17/05/2016 3
Objectifs
• Pouvoir calculer l’AFD qui reconnait les préfixes viables.
• Pouvoir générer une table d’analyse LR(0).
• Pouvoir décrire le driver LR(0) et le simuler.

4
Introduction(1)
!Analyseurs descendants
!commence la construction de l'arbre d'analyse à partir du
la racine de l'arbre et se déplacer vers le bas (vers les
feuilles).
!Facile à mettre en œuvre à la main, mais travailler avec les
grammaires restreintes.
!exemple: analyseur prédictifs LL(1)

Introduction(2)
!Analyseurs ascendants (Bottom-up)
!On cherche à construire un arbre de dérivation à partir des feuilles
selon un parcours inverse d’un parcours en profondeur d’abord de
gauche a droite.
!Les étapes de réduction tracent une dérivation à droite à l'envers.
!Suitable pour un générateur d'analyseur syntaxique automatique
! Peut gérer une grande classe de grammaires.
!exemples: shift-reduce parser (or LR (k) parsers)
10/5/205
S → aABe
A → Abc | b
B → d
Grammaire
input string : abbcde.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
1
/
122
100%