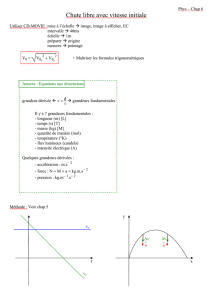
Statistiques
D.Moreaux
18 avril 2016

Table des matières
1 Introduction 1
2 Rappel : statistiques à une variable 3
2.1 représentation des données . . . . . . . . . . . . . . . . . . . . 3
2.2 Grandeurs de base . . . . . . . . . . . . . . . . . . . . . . . . 3
2.3 Grandeurs dérivées . . . . . . . . . . . . . . . . . . . . . . . . 4
3 Rappel : équation d’une droite 5
3.1 Coordonnées cartésiennes . . . . . . . . . . . . . . . . . . . . . 5
3.2 Equation d’une droite . . . . . . . . . . . . . . . . . . . . . . . 5
4 Statistiques à deux variables 7
4.1 Données à plusieurs variables . . . . . . . . . . . . . . . . . . 7
4.2 Lien entre deux variables . . . . . . . . . . . . . . . . . . . . . 7
4.3 Régression linéaire . . . . . . . . . . . . . . . . . . . . . . . . 8
4.4 Corrélation linéaire . . . . . . . . . . . . . . . . . . . . . . . . 8
4.5 Coefficient de corrélation de Pearson . . . . . . . . . . . . . . 9
5 Compléments 11
5.1 Régression non linéaire . . . . . . . . . . . . . . . . . . . . . . 11
5.1.1 Régression logarithmique . . . . . . . . . . . . . . . . . 11
5.1.2 Régression exponentielle . . . . . . . . . . . . . . . . . 12
5.1.3 Régression puissance . . . . . . . . . . . . . . . . . . . 12
5.1.4 Corrélation et régression non linéaire . . . . . . . . . . 12
i

ii

Chapitre 1
Introduction
Dans de nombreux domaines, il est intéressant de prévoir ce qu’une gran-
deur numérique peut valoir. Ces grandeurs numériques sont souvent le ré-
sultat de la combinaison de plusieurs facteurs, dont certains peuvent être de
nature aléatoire.
Les statistiques permettent, à partir d’un nombre de mesures suffisant,
de tenter de retrouver les lois qui régissent les nombres mesurés. Ainsi, les
fréquences associées à des grandeurs tendent vers les probabilités d’obtenir
les grandeurs en question ou la moyenne tend vers l’espérance mathématique
de la variable concernée quand le nombre d’échantillon tend vers l’infini.
Mais de nombreuses situations font apparaître plusieurs grandeurs plus
ou moins liées entre elles. Par exemple, le poids d’une caisse de fruits et le
nombre de fruits présents dans la caisse sont liés, même si les fruits ont tous
des poids différents et donc, la relation entre les deux grandeurs n’est pas
parfaitement linéaire.
Outre les grandeurs liées à une variable unique (par exemple la répartition
des poids des fruits, leur poids moyen,. . .), on s’intéressera donc également
aux relations entre deux variables.
Cela suppose deux choses, d’une part établir une fonction qui lie une des
grandeurs à l’autre et d’autre part, déterminer dans quelle mesure les deux
grandeurs sont liées l’une à l’autre par cette fonction.
Ce sont là les principaux problèmes traités dans les statistiques à deux
variables.
1

2CHAPITRE 1. INTRODUCTION
 6
7
8
9
10
11
12
13
14
15
6
7
8
9
10
11
12
13
14
15
1
/
15
100%